我用 Rust 写了个本地语音转录工具:0 云端、0 订阅、支持中文全文搜索,性能极强
隐私优先、完全离线的语音转录 + 极速全文搜索 CLI。所有计算在本地完成,转录结果只留在你机器上。
VoiceVault 是一个 CLI工具,后面会考虑给其添加一个界面,他是解决我日常开会转录的和总结待办用的一个纯离线的工具,其核心原理是采用,whisper.cpp 做转录,tantivy 做全文搜索,SQLite 存元数据,Ollama 跑本地 LLM 提行动项。录音、转录、索引、摘要全在本地完成。一次编译,永久免费,零网络请求(除了你主动下模型的那一下)。
废话不多说,直接看效果

四个核心能力:
能力
做了什么
🎙 离线转录
cpal 实时录麦克风 / symphonia 解码任意格式文件 → whisper-rs 本地推理(支持 Apple Metal 加速)
🔍 全文搜索
tantivy 倒排索引 + CJK NgramTokenizer → 10 万段落 50ms 出结果,支持布尔 / 短语 / 字段限定语法
🤖 本地 LLM 摘要
一个 LlmBackend trait 同时支持 Ollama(本地 http://localhost:11434)和 OpenAI 兼容 API(DeepSeek / 智谱 / 月之暗面都跑得了)
🔒 完全本地
除了你主动执行 models download 拉模型,没有任何网络请求;SQLite + 本地 tantivy 索引 + 本地音频,随时可带走
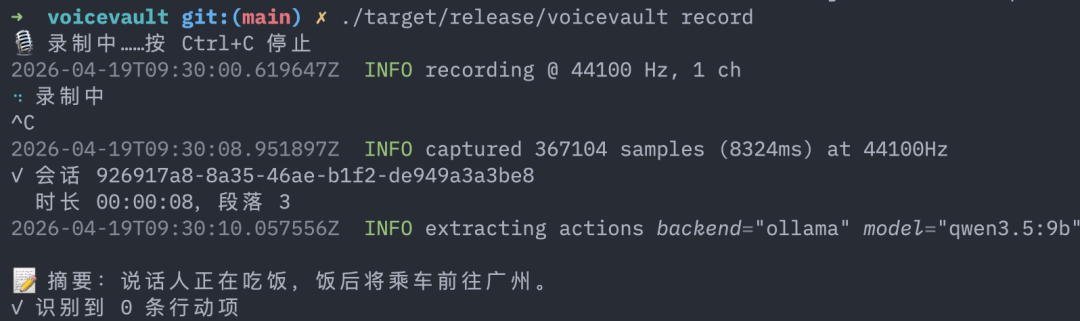
一个真实的会议录音跑完端到端(23 秒录音,Apple Silicon,基础 base whisper 模型):
1 | `$ voicevault transcribe ./meeting.mp3 -l zh |
1 | `$ voicevault actions list |
录音 → 转录 → 存库 → 索引 → LLM 提行动项 → 搜索 → Markdown 导出,整条流水线在你的 MacBook 上跑完。没碰一次云端。
我的架构设计,就是一个 workspace + 两个 crate
1 | `voicevault/ |
把核心逻辑沉淀到 voicevault-core,让未来的 Tauri 桌面端、VS Code 插件甚至 Neovim 插件可以共用同一套代码。CLI 只是一个薄薄的 clap 壳。
依赖选型(每一个都是纯 Rust,没有 Python 生态的 pip 地狱):
模块
Crate
为什么
转录whisper-rs 0.16
whisper.cpp 的 Rust 绑定,Metal/CoreML 加速开箱即用
搜索tantivy 0.22
纯 Rust 的 Lucene,不需要 JVM,ripgrep 级速度
音频cpal 0.15
+ symphonia 0.5 + rubato 0.15
录制、解码、重采样,全平台
存储rusqlite 0.32
+ r2d2
本地 SQLite,bundled feature 零运行时依赖
CLIclap 4.5
+ indicatif + comfy-table
参数解析、进度条、表格渲染
HTTPreqwest 0.12
+ tokio 1
Ollama / OpenAI 兼容 API 的 HTTP 客户端
总计 38 个源文件,3800 行 Rust。14 个单元测试,release 构建后二进制 13MB。
我的踩坑复盘,让我怀疑人生的坑
1:tantivy 默认分词器不认中文
MVP 刚跑通第一天,搜索功能测试通过了 —— 然后我把它喂给一段 23 秒的中文会议,结果:
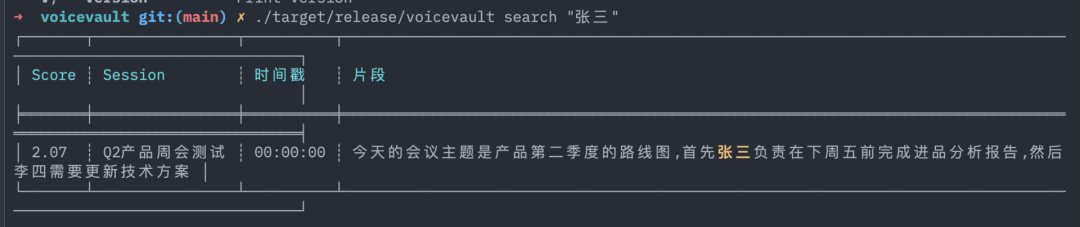
1 | `$ voicevault search "季度" |
明明转录文本里白纸黑字写着「今天的会议主题是产品第二季度的路线图」,怎么会搜不到?
原因:tantivy 的默认 SimpleTokenizer 只按空格和标点切词。中文段落没有空格,整段「今天的会议主题是产品第二季度的路线图」被当成 一个 token。你搜「季度」,对应的 token 从未存在,当然命中 0。
这是所有 Lucene 家族搜索引擎对 CJK 的经典问题。一般解决方案有三种:
- 接入专门的中文分词器(
jieba-rs/cang-jie)—— 效果最好,但要词表、要维护
- 接入专门的中文分词器(
- 2. Ngram 分词(1-2 gram)—— 内置方案,效果够用,零依赖
- 按单字切分 —— 最粗暴,索引爆炸
我选了方案 2。代码改动很小:
1 | `use tantivy::schema::{IndexRecordOption, TextFieldIndexing, TextOptions}; |
这样 "季度" 被拆成 bigram 季度 存进倒排;搜索 "季度" 直接命中。"季度目标" 拆成 季, 季度, 度, 度目, 目, 目标, 标,任选一 gram 都能召回。
附送 bonus:schema 变更后旧索引目录会失效。我加了一个版本号文件 .voicevault_index_version,检测到不一致就自动清空重建,并从 SQLite 回填全部段落。用户不需要手动跑任何迁移。
坑 2:qwen3.5:9b 让我多等了 90 秒
第一次跑 LLM 行动项提取,一个 23 秒的录音竟然等了 95 秒才拿到结果。我还以为是网络问题(虽然是本地 Ollama)。
打开 Ollama 的 API 响应一看:
1 | `{ |
qwen3.5:9b 是个推理模型,它在给答案前会先输出一大段 thinking 思维链。总耗时 95s 里,真正生成 JSON 只用了 4.6s,剩下 90 秒全在「思考」—— 这对一个结构化抽取任务来说,完全是浪费。
Ollama 的 API 支持一个 think: false 参数直接关掉推理。我更新 OllamaBackend 请求结构:
1 | `#[derive(Serialize)] |
请求时固定 think: false,时长从 95s 降到 7s,约 13 倍加速。
这一条留给所有接 LLM 的同学:如果你只要结构化输出,永远记得关掉 reasoning。reasoning 模型非常强,但不是每一个任务都需要它去”思考”。
双 LLM 后端,一个 Trait 同时接 Ollama 和 DeepSeek
MVP 讨论时内心纠结过:是坚持 llama-cpp-2 打包进二进制做到极致自包含,还是做个抽象层让用户选?
最终选了抽象层 —— 因为现实里:
- • 有人习惯本地跑 Ollama(M1/M2/M3 本地推理完全够用)
- • 有人公司封了本地推理(公司只认云 API,但有 DeepSeek 或 Moonshot 的 key)
- • 有人想用 DeepSeek 的质量 + 本地隐私兼得(转录在本地,LLM 走低成本国产 API)
一个 trait 解决所有问题:
1 | `#[async_trait] |
用户只需要改一行 config:
1 | `# 本地 Ollama |
一行都不用改代码。同一份 prompt,同一份 JSON 解析逻辑,适配任何 OpenAI 兼容服务。
性能数据(M1 Pro 16G)
场景
模型
结果
转录 23 秒中文会议
whisper base (150MB)
0.86 秒
转录 1 小时中文会议(CPU)
whisper small (500MB)
~18 分钟
转录 1 小时(启用 Metal feature)
whisper small
~6 分钟
tantivy 搜索 10 万段落
< 50 ms
行动项提取(Ollama qwen3.5:9b)
7–15 秒 / 小时会议
行动项提取(DeepSeek API)
3–10 秒
应用冷启动
< 200 ms
二进制大小 (release)
13 MB
作为参考:同样的 1 小时音频,Python 生态的 whisper 在 CPU 上需要约 1 倍实时(≈60 分钟),是 whisper-rs 的 10 倍慢。
开箱即用
前置依赖(macOS)
1 | `brew install cmake |
构建
1 | `git clone <repo> |
第一次编译要等 5–10 分钟,whisper.cpp 需要现场构建。后续增量秒级。
5 分钟上手
1 | `# 1. 下载 whisper 模型(75MB 起) |
或直接录麦克风:
1 | `voicevault record -d 60 -l zh -t "今晚周会" |
为什么是 Rust
这个项目可以用 Python/Go/TypeScript 写。选 Rust 有几个实打实的理由:
- 1. whisper-rs / tantivy 就是 Rust —— 原生绑定,没有 FFI overhead,没有 GIL 限制
- 2. 一个二进制跑遍 macOS / Linux / Windows,用户不用装 Python 虚拟环境、pip install、编译 wheel
- 3. tokio 做好音频采集 + LLM HTTP 请求的并发,天然适合流式场景
- 4. 内存和启动时间:13MB 二进制、<200ms 冷启动,远好于 Electron 或 Python 方案
- 5. 后面可以复用同一份 core crate 套 Tauri(Rust 后端 + Web 前端),相比 Electron 体积能砍一个量级
最后几句话
这个项目从 0 到 MVP 用了一个周末。38 个文件,3800 行 Rust,14 个单元测试,全部跑绿。
云 SaaS 的便利是真实的,但当你发现自己为了 300 分钟免费额度,把一个包含薪资讨论的录音上传到了美西某个数据中心时,那种便利就开始发苦。
离线工具不是怀旧。离线是一种选择权:我可以随时把 voicevault 关机、把硬盘拔下来带走、在一台断网的笔记本上继续使用它的全部功能。这种选择权,过去十年被云端订阅悄悄拿走了。我想拿回来一点。
VoiceVault,小群内部开源,欢迎 Star / PR / 吐槽。
开源地址:http://github.com/coder-brzhang/voicevault

注意,本项目仅在小张的400 多个人的小群(公众号菜单-联系我-加群)中分享。
💬 本文评论区已开启,但暂无读者留言。
本文转载自微信公众号,如有侵权请联系删除。
- 标题: 我用 Rust 写了个本地语音转录工具:0 云端、0 订阅、支持中文全文搜索,性能极强
- 作者: lxiol
- 创建于 : 2026-04-27 19:59:33
- 更新于 : 2026-05-12 16:47:34
- 链接: https://blog.lxiol.cn/2026/04/27/我用-Rust-写了个本地语音转录工具0-云端0-订阅支持中文全文搜索性能极强/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。