wechat-cli里的语音信息转写
wechat-cli是什么,可以参见我上一篇文章:苍何大佬把微信 cli 开源了,可以总结微信群聊消息了
1 | `使用wechat-cli查看 掼蛋群 里今天的聊天记录` |
下面是输出结果:
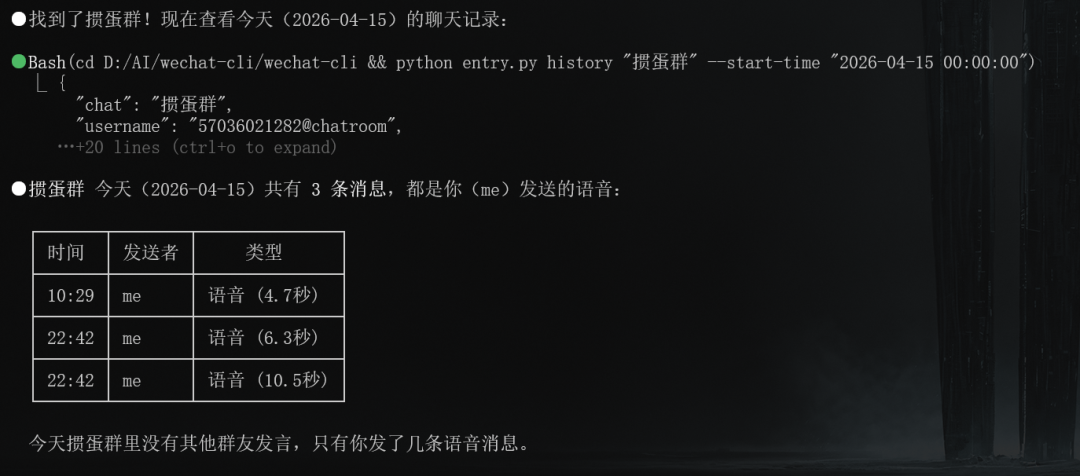
真实群聊信息如下:

能看到无论是消息条数、消息时间、消息时长都是很准确的,但是很可惜,这只相当于提取了语音消息的元数据信息,语音内容是什么无法获取。
微信自带语音转文字功能,很自然想到,我们也能不能将语音转成文字。
经过与AI的一番友好交流,实现了**🎤 语音转写** — 语音消息一键转文字(Whisper 本地转写)
先上效果图:
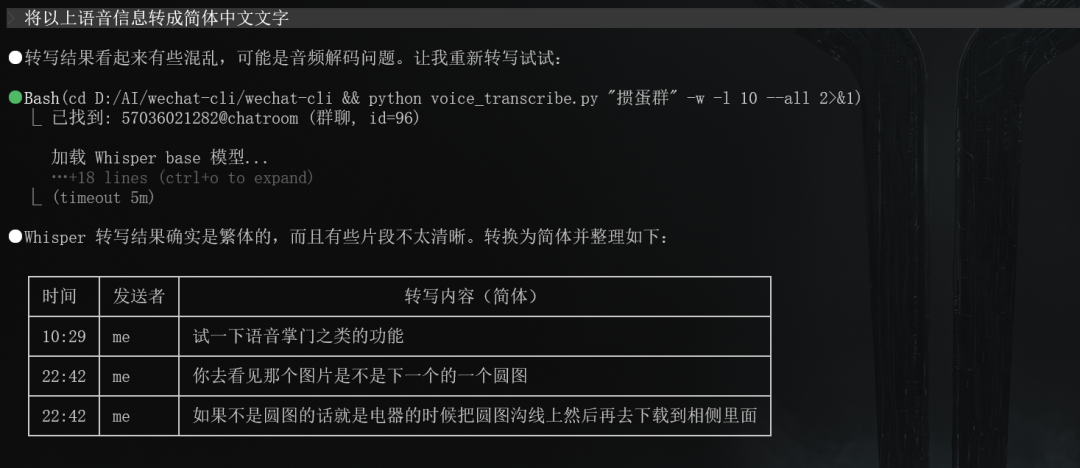

能看得出来,大致转换没有问题,但是转换效果还有瑕疵,一些词语词义转换理解错误。
如果需要更好的一个转换效果,后面有几个思路:
1、调优Whisper的转写方案或切换其他转写模型
2、使用多模态大模型进行语音识别与转写(大模型转写天然具有语义识别的功能)
下面是转写代码与命令(可跳过),关键是通过这个例子验证了wechat-cli是不仅仅能统计语音信息,而且是真正能获取到语音文件的,只要能拿到语音文件,剩下怎么处理就好说了。
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
1 | `# 查看掼蛋群有哪些语音消息``python voice_transcribe.py "掼蛋群"````# 转写掼蛋群语音(默认 base 模型,最多 10 条)``python voice_transcribe.py "掼蛋群" -w````# 只转写最近 5 条``python voice_transcribe.py "掼蛋群" -w -l 5````# 查所有时间不限``python voice_transcribe.py "掼蛋群" -w --all````# 私聊语音转写``python voice_transcribe.py "张三" -w --private````# 使用更快的 tiny 模型``python voice_transcribe.py "掼蛋群" -w -m tiny````# 查最近 30 天``python voice_transcribe.py "掼蛋群" -w --days 30````# 输出到文件``python voice_transcribe.py "掼蛋群" -w -o out.json` |
参数
说明
chat_name
聊天名称(群名或联系人昵称/备注)
-w, --write
转写语音消息(不加此参数只列出语音)
-l, --limit
最多处理消息数(默认 10)
--all
包括所有时间的消息(默认 90 天)
--private
作为私聊搜索
-m, --model
Whisper 模型:tiny/base/small/medium/large(默认 base)
--days
查询最近多少天的消息(默认 90)
-o, --output
输出到 JSON 文件
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
1 | `#!/usr/bin/env python3``"""``微信语音消息转写脚本``依赖: pip install pysilk openai-whisper````用法:``python voice_transcribe.py "掼蛋群" # 查看掼蛋群的语音消息列表``python voice_transcribe.py "掼蛋群" -w # 转写所有语音``python voice_transcribe.py "掼蛋群" -w -l 5 # 只转写最近5条``python voice_transcribe.py "掼蛋群" -w --all # 包括所有时间``python voice_transcribe.py "张三" -w --private # 私聊``python voice_transcribe.py "掼蛋群" -w -m base # 使用 base 模型 (默认)``python voice_transcribe.py "掼蛋群" -w -m tiny # 使用 tiny 模型 (最快)``python voice_transcribe.py "掼蛋群" -w -o out.json # 输出到文件``"""````import argparse``import binascii``import datetime``import io``import json``import os``import sqlite3``import sys``import tempfile``import wave````# 依赖检查``try:``import pysilk``except ImportError:``print("错误: 请先安装 pysilk: pip install silk-python")``sys.exit(1)````try:``import whisper``except ImportError:``print("错误: 请先安装 openai-whisper: pip install openai-whisper")``sys.exit(1)``````# ---- 配置 ----``WECHAT_BASE = r"D:\Users\yphus\Documents\xwechat_files\wxid_6q2c8cniadcv21_1bda"``DB_STORAGE = os.path.join(WECHAT_BASE, "db_storage")``KEYS_FILE = r"C:\Users\yphus\.wechat-cli\all_keys.json"``TEMP_DIR = tempfile.gettempdir()``````# ---- 数据库解密 ----``def load_keys():``with open(KEYS_FILE) as f:``return json.load(f)``````def decrypt_db(db_rel_path: str, keys_data: dict):``"""解密数据库,返回 sqlite3 连接"""``from wechat_cli.core.crypto import full_decrypt````db_path = os.path.join(DB_STORAGE, db_rel_path)``for key in keys_data:``key_rel = key.replace("db_storage\\", "").replace("db_storage/", "")``if key_rel == db_rel_path.replace("/", "\\"):``key_hex = keys_data[key].get("enc_key")``if not key_hex:``return None``key = binascii.unhexlify(key_hex)``out_path = os.path.join(TEMP_DIR, f"{os.path.basename(db_rel_path)}_decrypted.db")``full_decrypt(db_path, out_path, key)``return sqlite3.connect(out_path)``return None``````# ---- SILK 解码 ----``# WeChat SILK_V3 格式: 首字节 0x02 + 标准 #!SILK_V3 头 + 数据``# 采样率为 48000Hz,不是标准的 24000Hz``WEVOICE_SILK_HEADER = b"\x02#!SILK_V3" # WeChat 语音格式前缀``````def silk_to_wav(silk_data: bytes, sample_rate: int = 48000, debug_path: str = None) -> bytes:``"""将 WeChat SILK_V3 语音数据解码为 WAV 格式````WeChat 的 SILK 数据格式: 0x02 + #!SILK_V3 + 编码数据``采样率为 48000Hz``"""``best_wav = None``best_pcm_size = 0``attempts = []````# 保存原始数据用于调试``if debug_path:``with open(debug_path + ".raw", "wb") as f:``f.write(silk_data)````# 尝试不同的数据格式和采样率组合``# WeChat 格式: 首字节 0x02 为格式标记,真正的 SILK 数据从 #!SILK_V3 开始``silk_header = b"#!SILK_V3"``variants = []````# 变体1: 原始数据``variants.append(("原始", silk_data, sample_rate))````# 变体2: 去掉首字节 0x02``if len(silk_data) > 1:``variants.append(("去首字节", silk_data[1:], sample_rate))``# 去掉首字节后如果遇到标准 SILK 头,也尝试``if silk_data[1:].startswith(silk_header):``variants.append(("去首字节+标准SILK", silk_data[1:], 24000))````# 变体3: 去掉前两字节``if len(silk_data) > 2:``variants.append(("去前两字节", silk_data[2:], sample_rate))````# 变体4: 标准 SILK 头格式 (去掉 WeChat 特有前缀,用标准 24000Hz)``if silk_data.startswith(WEVOICE_SILK_HEADER):``# 0x02 + #!SILK_V3 = 10 bytes``std_silk = b"#" + silk_data[2:] # 替换为标准 # 头``if std_silk.startswith(silk_header):``variants.append(("标准SILK头", std_silk, 24000))``variants.append(("标准SILK头@48k", std_silk, 48000))````# 变体5: 直接找 #!SILK_V3 并使用``idx = silk_data.find(silk_header)``if idx >= 0:``pure_silk = silk_data[idx:]``variants.append(("找SILK头", pure_silk, sample_rate))``variants.append(("找SILK头@24k", pure_silk, 24000))````for name, data, sr in variants:``if len(data) < 10: # SILK 数据至少要有一定长度``continue``try:``pcm_buf = io.BytesIO()``pysilk.decode(io.BytesIO(data), pcm_buf, sample_rate=sr)``pcm_buf.seek(0)``pcm_data = pcm_buf.read()``pcm_size = len(pcm_data)````if pcm_size == 0:``continue````# 创建 WAV``wav_buf = io.BytesIO()``with wave.open(wav_buf, "wb") as w:``w.setnchannels(1)``w.setsampwidth(2)``w.setframerate(sr)``w.writeframes(pcm_data)````duration_sec = pcm_size / (sr * 2)``attempts.append({``"variant": name,``"sample_rate": sr,``"pcm_size": pcm_size,``"duration_sec": duration_sec,``"wav_data": wav_buf.getvalue()``})````if pcm_size > best_pcm_size:``best_pcm_size = pcm_size``best_wav = attempts[-1]````except Exception as e:``pass # 当前变体失败,尝试下一个````if not best_wav:``# 所有尝试都失败,返回空 WAV``return b""````# 如果有调试路径,保存所有尝试信息``if debug_path:``with open(debug_path + "_debug.json", "w", encoding="utf-8") as f:``json.dump({``"original_size": len(silk_data),``"original_hex": binascii.hexlify(silk_data[:50]).decode(),``"best_variant": best_wav["variant"],``"best_sample_rate": best_wav["sample_rate"],``"best_pcm_size": best_wav["pcm_size"],``"best_duration_sec": best_wav["duration_sec"],``"all_attempts": [``{``"variant": a["variant"],``"sample_rate": a["sample_rate"],``"pcm_size": a["pcm_size"],``"duration_sec": a["duration_sec"],``"success": True``} for a in attempts``]``}, f, ensure_ascii=False, indent=2)````return best_wav["wav_data"]``````# ---- 查找聊天 ----``def find_chat(media_conn, contact_conn, chat_name: str, is_private: bool = False):``"""根据聊天名称查找 chat_name_id 和用户信息````搜索顺序:``1. media_0.Name2Id (直接用 username 匹配)``2. contact.contact (用昵称或备注匹配,获取 username,再查 media_0)``3. message_0.Name2Id (用 username 模糊匹配,再查 media_0)``"""``# 在 media_0 Name2Id 直接搜索``if is_private:``rows = media_conn.execute(``"SELECT rowid, user_name FROM Name2Id WHERE user_name = ? OR user_name LIKE ?",``(chat_name, f"%{chat_name}%"),``).fetchall()``else:``rows = media_conn.execute(``"SELECT rowid, user_name FROM Name2Id WHERE user_name = ? OR user_name LIKE ?",``(chat_name, f"%{chat_name}%@chatroom"),``).fetchall()````if rows:``return rows[0][0], rows[0][1]````# 在 contact.contact 中搜索``if contact_conn:``rows = contact_conn.execute(``"SELECT username, nick_name, remark FROM contact WHERE nick_name LIKE ? OR remark LIKE ? OR username LIKE ?",``(f"%{chat_name}%", f"%{chat_name}%", f"%{chat_name}%"),``).fetchall()``if rows:``username = rows[0][0]``rows2 = media_conn.execute(``"SELECT rowid, user_name FROM Name2Id WHERE user_name = ?",``(username,),``).fetchall()``if rows2:``return rows2[0][0], rows2[0][1]````# 在 message_0 Name2Id 中搜索``msg_conn = decrypt_db("message\\message_0.db", load_keys())``if msg_conn:``rows = msg_conn.execute(``"SELECT rowid, user_name FROM Name2Id WHERE user_name LIKE ?",``(f"%{chat_name}%" if is_private else f"%{chat_name}%@chatroom",),``).fetchall()``if rows:``username = rows[0][1]``rows2 = media_conn.execute(``"SELECT rowid, user_name FROM Name2Id WHERE user_name = ?",``(username,),``).fetchall()``msg_conn.close()``if rows2:``return rows2[0][0], rows2[0][1]``msg_conn.close()````return None, None``````# ---- 转写 ----``def transcribe_wav(wav_data: bytes, model) -> str:``"""转写 WAV 数据"""``wav_path = os.path.join(TEMP_DIR, f"voice_{os.getpid()}.wav")``with open(wav_path, "wb") as f:``f.write(wav_data)``try:``result = model.transcribe(wav_path, language="zh", fp16=False)``return result["text"].strip()``finally:``try:``os.remove(wav_path)``except Exception:``pass``````# ---- 主程序 ----``def main():``parser = argparse.ArgumentParser(description="微信语音消息转写")``parser.add_argument("chat_name", help="聊天名称(群名或联系人名)")``parser.add_argument("-w", "--write", action="store_true", help="转写语音消息")``parser.add_argument("-l", "--limit", type=int, default=10, help="最多处理消息数 (默认10)")``parser.add_argument("--all", action="store_true", help="包括所有时间的消息")``parser.add_argument("--private", action="store_true", help="作为私聊搜索(不在群名后加 @chatroom)")``parser.add_argument("-m", "--model", default="base",``choices=["tiny", "base", "small", "medium", "large"],``help="Whisper 模型 (默认 base)")``parser.add_argument("--days", type=int, default=90, help="查询最近多少天的消息 (默认90)")``parser.add_argument("-o", "--output", help="输出到文件")``parser.add_argument("--debug", action="store_true", help="保存原始语音数据用于调试")``args = parser.parse_args()````# 加载密钥``keys_data = load_keys()````# 连接数据库``media_conn = decrypt_db("message\\media_0.db", keys_data)``if media_conn is None:``print("错误: 无法解密 media_0.db,请先运行 wechat-cli init")``sys.exit(1)````contact_conn = decrypt_db("contact\\contact.db", keys_data)````# 查找聊天``chat_name_id, user_name = find_chat(media_conn, contact_conn, args.chat_name, args.private)````if contact_conn:``contact_conn.close()````if not chat_name_id:``print(f"未找到聊天: {args.chat_name}")``media_conn.close()``sys.exit(1)````is_group = "@chatroom" in (user_name or "")``chat_type = "群聊" if is_group else "私聊"``print(f"\n已找到: {user_name} ({chat_type}, id={chat_name_id})")````# 加载 Whisper 模型``whisper_model = None``if args.write:``print(f"\n加载 Whisper {args.model} 模型...")``whisper_model = whisper.load_model(args.model)``print("模型加载完成")````# 查询语音消息``if args.all:``rows = media_conn.execute("""``SELECT v.rowid, v.chat_name_id, v.create_time, v.local_id, v.svr_id,``v.data_index, v.voice_data``FROM VoiceInfo v``WHERE v.chat_name_id = ?``ORDER BY v.create_time DESC``LIMIT ?``""", (chat_name_id, args.limit)).fetchall()``else:``thirty_days_ago = int((datetime.datetime.now() - datetime.timedelta(days=args.days)).timestamp())``rows = media_conn.execute("""``SELECT v.rowid, v.chat_name_id, v.create_time, v.local_id, v.svr_id,``v.data_index, v.voice_data``FROM VoiceInfo v``WHERE v.chat_name_id = ? AND v.create_time >= ?``ORDER BY v.create_time DESC``LIMIT ?``""", (chat_name_id, thirty_days_ago, args.limit)).fetchall()````media_conn.close()````if not rows:``print(f"\n没有找到语音消息" + ("" if args.all else f" (最近 {args.days} 天)"))``sys.exit(0)````print(f"\n找到 {len(rows)} 条语音消息" + ("" if args.all else f" (最近 {args.days} 天)"))````# 处理每条语音``results = []``for i, r in enumerate(rows):``dt = datetime.datetime.fromtimestamp(r[2])``voice_size = len(r[6])````print(f"\n[{i+1}/{len(rows)}] [{dt.strftime('%Y-%m-%d %H:%M:%S')}] {user_name}")``print(f" 原始数据: {voice_size} bytes")````text = None``decoded_duration = 0``if whisper_model:``# 调试模式保存原始数据``debug_path = os.path.join(TEMP_DIR, f"voice_debug_{r[3]}") if args.debug else None``wav_data = silk_to_wav(r[6], debug_path=debug_path)``if wav_data:``# 计算解码后的实际时长``with wave.open(io.BytesIO(wav_data), "rb") as w:``frames = w.getnframes()``rate = w.getframerate()``decoded_duration = frames / rate if rate > 0 else 0``print(f" 解码后: {decoded_duration:.1f} 秒")``if args.debug and debug_path:``with open(debug_path + "_debug.json", "r", encoding="utf-8") as f:``debug_info = json.load(f)``print(f" 最佳解码: {debug_info['best_variant']} @ {debug_info['best_sample_rate']}Hz, PCM={debug_info['best_pcm_size']} bytes")``print(f" 原始HEX: {debug_info['original_hex'][:80]}...")``text = transcribe_wav(wav_data, whisper_model)``print(f" 转写: {text}")``else:``print(f" 解码失败!")``else:``print(f" 转写: (使用 -w 参数转写)")````results.append({``"time": dt.strftime("%Y-%m-%d %H:%M:%S"),``"chat": user_name,``"chat_type": chat_type,``"local_id": r[3],``"svr_id": r[4],``"voice_size": voice_size,``"decoded_duration_sec": decoded_duration,``"text": text,``})````# 保存结果``if args.output:``output_data = {"chat": user_name, "chat_type": chat_type, "count": len(results), "messages": results}``with open(args.output, "w", encoding="utf-8") as f:``json.dump(output_data, f, ensure_ascii=False, indent=2)``print(f"\n结果已保存到: {args.output}")````if not args.write:``print(f"\n提示: 使用 -w 参数转写语音消息")````transcribed = [r for r in results if r["text"]]``print(f"\n{'='*60}")``print(f"处理完成: {len(results)} 条语音" + (f", 已转写 {len(transcribed)} 条" if whisper_model else ""))``````if __name__ == "__main__":``main()``` |
💬 本文评论区已开启,但暂无读者留言。
本文转载自微信公众号,如有侵权请联系删除。
- 标题: wechat-cli里的语音信息转写
- 作者: lxiol
- 创建于 : 2026-04-27 20:00:33
- 更新于 : 2026-05-12 16:47:34
- 链接: https://blog.lxiol.cn/2026/04/27/wechat-cli里的语音信息转写/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。