超越GraphRAG:三层固定实体架构构建下一代高性价比智能问答系统
本文深入探讨了GraphRAG(Graph Retrieval-Augmented Generation)技术,分析了当前主流GraphRAG定义的局限性,并提出了一种基于NLP的、成本效益高的图构建方法。
Part.01
摘要
本文深入探讨了GraphRAG(Graph Retrieval-Augmented Generation)技术,分析了当前主流GraphRAG定义的局限性,并提出了一种基于NLP的、成本效益高的图构建方法。文章旨在为专业人士提供构建高效RAG系统的新视角,特别是在数据量大、预算有限或领域知识不明确的情况下,通过优化图结构和利用NLP技术,实现智能问答能力的飞跃。
【深度解析】三层固定实体架构:重塑知识图谱与RAG的效率边界
Part.02
引言:GraphRAG的定义与挑战
在人工智能飞速发展的浪潮中,检索增强生成(RAG)技术已成为提升大型语言模型(LLM)知识性和准确性的关键。然而,RAG的应用并非没有瓶颈。当面对结构化知识和非结构化文本的融合需求时,图数据库的引入——即GraphRAG——应运而生。但“GraphRAG”至今尚未形成一个统一、广为接受的定义 。
根据作者的观察和行业交流,目前存在几种主流理解:
90% 的人将 GraphRAG 与微软的方法关联,即构建一个图谱并在此基础上进行搜索 。
8% 的人将 GraphRAG 定义为使用 LLM 生成的 Cypher 查询语言或文本到任何图语言(如 Cypher 或 SPARQL)来查询 LPG(Labeled Property Graph)或 RDF(Resource Description Framework)图 。
剩余 2% 则表示不确定或正在探索新的可能性 。
作者认为,虽然微软的 GraphRAG 概念具有前瞻性,但其高昂的成本和复杂性使其在当前大规模工业应用中难以普及,大多数公司更倾向于选择更经济实惠的“标准”向量数据库 。而基于文本生成查询(Text-To-Cypher / Text-To-SPARQL)的技术虽然具有潜力,但也面临LLM调用成本高、不确定性增加、响应时间延长以及实施复杂度高等问题 。
Part.03
GraphRAG的效率优化与成本考量
作为一名顾问和GenAI解决方案开发者,作者致力于服务各种规模的GraphRAG应用 。在扩展GraphRAG能力时,常常需要在准确性与效率之间进行权衡。若能找到一种低复杂度、成本效益高且仍能提供满意结果的解决方案,则具有极高的价值 。
因此,核心挑战在于如何在不产生高昂图谱构建费用的前提下,利用图的强大能力来增强RAG。理想情况是,能够最小化对LLM的依赖,甚至使用小型本地LLM替代昂贵的云端API调用 。
Part.04
固定实体架构(Fixed Entity Architecture)与局限性
作者曾提出一种名为“固定实体架构”的新方法来构建用于RAG的图谱 。该方法的核心思想是构建一个分层图:
【深度解析】三层固定实体架构:重塑知识图谱与RAG的效率边界
层 1:本体层(Ontology Layer)
定义领域本体。由于本体通常范围有限,此层的大小相对固定 。
层 2:文档层(Document Layer)
包含文档块,类似于标准向量数据库中的内容。在此层应用向量索引进行直接查询,即标准的向量数据库搜索 。
层 3(可选):实体层(Entity Layer)
包含从文档块中提取的实体(例如使用 spaCy)。由于实体在不同文档中常有重复,可作为“粘合剂”,提升搜索结果 。
通过这种方法,可以在不依赖LLM的情况下创建图谱。然而,构建本体层面临挑战:并非所有数据集都属于明确定义的领域,且主题专家(SMEs)不一定总能提供协助 。这促使作者探索无需固定本体层的方案。
分层图的优势: Neo4j 允许在单个内部标签上进行向量索引。若节点拥有不同标签,则需要为每个标签构建单独的索引,这在执行向量搜索时可能不切实际。尽管在某些需要严格本体区分/过滤的场景下,拥有大量节点类型有意义,但作者的实践表明,两到三层通常已足够 。为解决标签索引限制,作者采用了一种变通方法:为层内的所有节点分配相同的内部标签,而将实际标签、名称和元数据存储为节点属性 。
Part.05
NLP的强大力量:摆脱LLM依赖
如何在不依赖大脑或万亿参数LLM的情况下提取文本信息?这正是经典NLP(自然语言处理)的用武之地 。
作者在GPT-3.5时代之前及之后,对NLP库和模型进行了广泛调研,发现许多模型已不再得到支持、更新或维护,这是一个令人遗憾的现状,因为它们蕴含着巨大的潜力 。
尽管如此,出于对行业实际需求的响应和面临的实际限制,作者决定探索一种NLP驱动的方法,旨在构建能够提升标准向量数据库性能的图谱 。作者鼓励读者进一步探索NLP驱动的图结构,因为当前的研究仅触及了其潜力的冰山一角 。
Part.06
GraphRAGs及其应用场景
在深入探讨NLP驱动的图构建实现及其结果之前,有必要先阐述不同GraphRAG类型及其应用 。
微软GraphRAG及其衍生的方法 通常涉及:
使用LLM从大规模文本语料库中提取实体和关系 。
使用LLM对提取的信息进行摘要 。
允许用户查询摘要或社区生成的摘要 。
尽管实现方式各异,但核心原则一致:利用LLM构建文本知识图谱 。
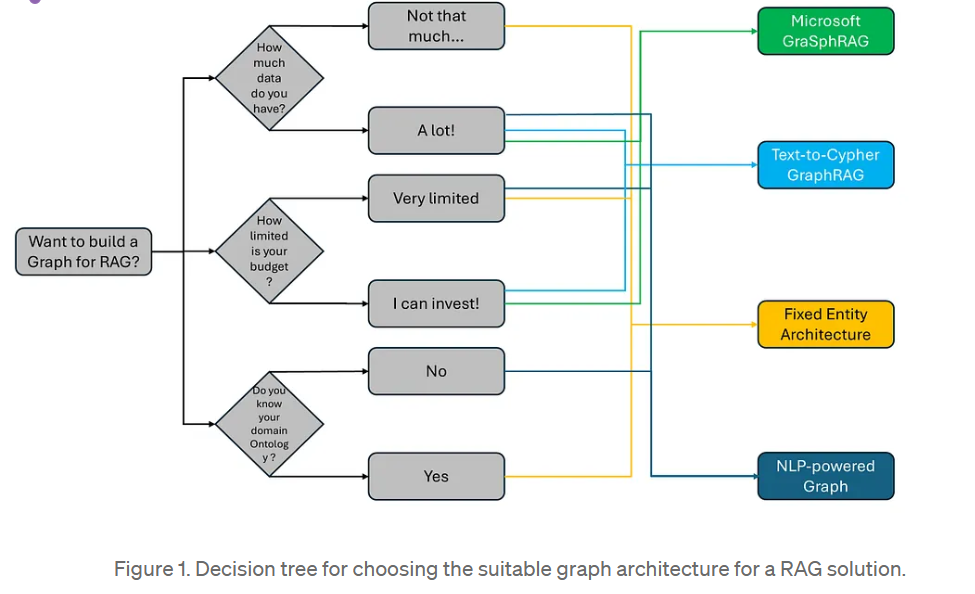
图1 (示意图)展示了作者基于行业经验对不同图基向量搜索RAG系统选择的视角,强调了关键决策因素:
数据量(Data Volume):知识库中有多少数据?
预算限制(Budget Constraints):构建图谱的预算有多紧张?
本体可用性(Ontology Availability):是否有清晰、结构化的本体?知识库是否属于可以构建稳健本体层的固定领域?或者数据是否多样、分散且缺乏明确的领域知识?
这些因素深刻影响GraphRAG解决方案的设计、可行性和效率 。
根据图1的决策树:
数据量大、预算充足、追求高精度:微软的解决方案是强有力的选择 。
预算受限(常见情况),可接受精度妥协,倾向于近乎无LLM的解决方案:最佳方法是建立本体层并构建固定实体架构图 。
难以定义本体、数据理解不足、数据复杂度高:推荐构建NLP驱动的图谱 。
Part.07
NLP驱动的图构建实践
现在,让我们动手构建一个成本极低的图谱(仅考虑电力消耗) 。
技术准备:
一台配备32GB RAM和6GB GPU的商务笔记本。
Neo4j Community Edition,运行在WSL(Ubuntu)上的Docker容器中。
一个包含660个PDF文件的数据集,以及一个经过修改的NVIDIA RAG Blueprint数据预处理管道 。
6.1 NLP驱动的图方法
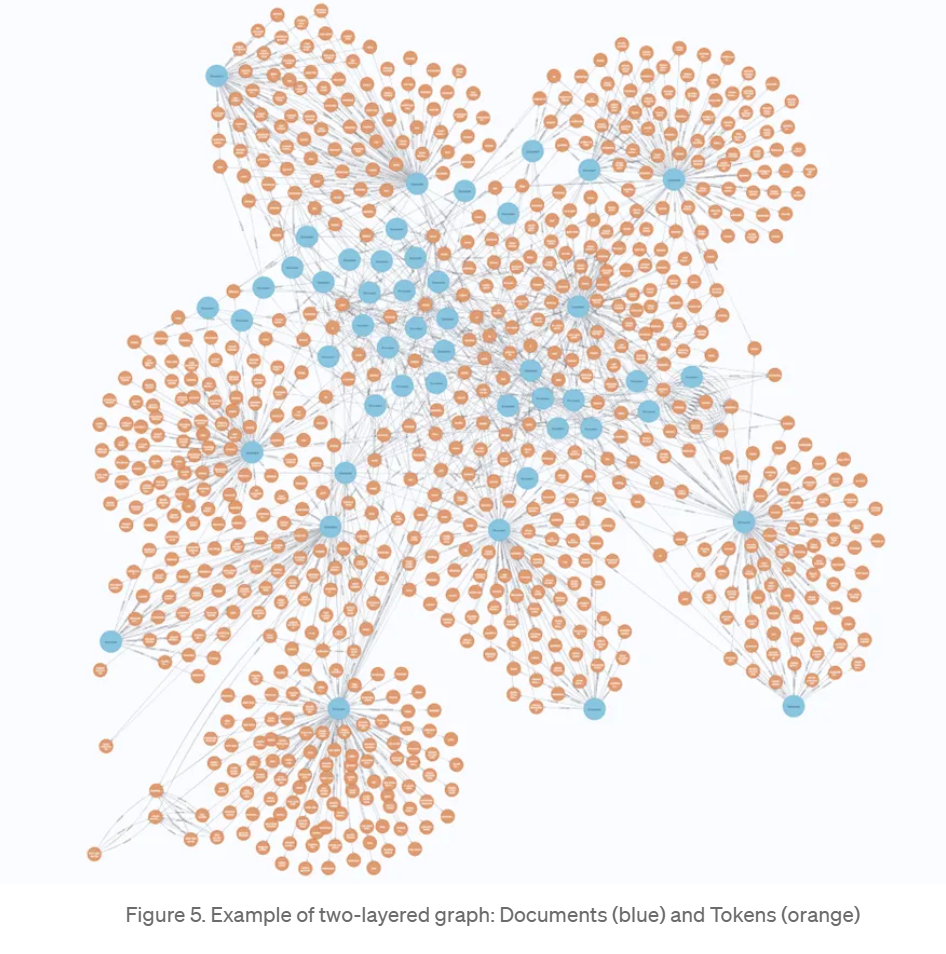
与固定实体架构的关键区别在于,作者 放弃了本体层 。因此,图谱由以下部分组成:
文档层(Document Layer):包含文档块,类似于标准向量数据库。
Token层(Tokens Layer):提取的Token作为额外的连接节点,提升搜索性能 。
通过利用NLP而非LLM密集型处理,此方法显著降低了成本 。
6.2 数据预处理管道
数据预处理管道包含以下关键步骤:
分块(Chunking):使用NVIDIA RAG Blueprint提供的预编写函数将文档分割成小段 。
嵌入(Embedding):替代默认的NVIDIA方法,使用了Hugging Face的“intfloat/e5-base-v2”模型对文档块进行嵌入 。
图谱构建(Graph Construction):在Neo4j中构建第一个图层,将所有文档块节点标记为 Document 。
以下是用于填充Neo4j数据库的文档层代码示例:
1 | python |
`defadd_chunks_to_db ( chunks, doc_name ):
prev_node_id = None
for i, chunk inenumerate (chunks):
Escape single quotes in the chunk content
escaped_chunk = chunk.replace( “‘“ , “\‘“ )
Create the chunk node
query = f’’’
MERGE (d:Document {{
chunkID: “ { f”chunk_ {i} “ } “,
docID: “ {doc_name.replace( “‘“ , “\‘“ )} “,
full_text: ‘ {escaped_chunk} ‘,
embeddings: {embeddings.embed_documents(chunk).tolist()}
}})
RETURN elementId(d) as id
‘’’
result = run_query(query)
chunk_node_id = result[ 0 ][ ‘id’ ]
If this is not the first chunk, create a NEXT relationship to the previous chunk
if prev_node_id isnotNone :
query = f’’’
MATCH (c1:Document), (c2:Document)
WHERE elementId(c1) = $prev_node_id AND elementId(c2) = $chunk_node_id
MERGE (c1)-[:NEXT]->(c2)
MERGE (c2)-[:PREV]->(c1)
‘’’
run_query(driver, query)
prev_node_id = chunk_node_id`
1 | ``` |
sql
1 | `CREATE VECTOR INDEX vector_index_document |
Part.08
结论
本文详细阐述了GraphRAG技术的发展现状、面临的挑战以及一种创新的NLP驱动的图构建方法。通过去除本体层,并利用NLP技术进行实体提取和关系构建,可以在显著降低成本的同时,有效增强RAG系统的性能。对于寻求构建高效、经济实惠的智能问答解决方案的企事业单位和科研院所而言,这种方法提供了一条切实可行的路径。
**欢迎加入「知识图谱增强大模型产学研」知识星球,获取最新产学研相关"知识图谱+大模型"相关论文、政府企业落地案例、避坑指南、电子书、文章等,行业重点是医疗护理、医药大健康、工业能源制造领域,也会跟踪AI4S科学研究相关内容,以及Palantir、OpenAI、微软、Writer、Glean、OpenEvidence等相关公司进展。**
![]()
往期推荐
[[300页电子书]Palantir 股票的大数据,大利润:为什么Palantir是未来企业级AI的潜力股](https://mp.weixin.qq.com/s?__biz=MzI3ODE5Mzc1Ng==&mid=2247504021&idx=1&sn=a10f1aeea796f5e5790db895304e6956&scene=21#wechat_redirect)
[[555页电子书]从LLM Agent到RAG与知识图谱全攻略实战指南重磅发布——构建具备推理、检索与行动能力的智能体](https://mp.weixin.qq.com/s?__biz=MzI3ODE5Mzc1Ng==&mid=2247503564&idx=1&sn=349609a5107b50c0009c7b533cb0b218&scene=21#wechat_redirect)
[250页电子书-医学领域的人工智能革命:GPT-4及医学大模型未来展望。OpenAI CEO作序](https://mp.weixin.qq.com/s?__biz=MzI3ODE5Mzc1Ng==&mid=2247503667&idx=1&sn=2dbe9f4ece739c2e7bd378f33083b1f2&scene=21#wechat_redirect)
[[100页电子书]知识图谱&大模型双轮驱动的工业 AI 数智化转型权威指南 - Cognite](https://mp.weixin.qq.com/s?__biz=MzI3ODE5Mzc1Ng==&mid=2247504169&idx=1&sn=adaadb6cd270296d19d4cadb33090004&scene=21#wechat_redirect)
[[73页]OpenAI联合哈佛等重磅发布全球首份ChatGPT使用报告,分析用户增长、使用模式及其经济价值](https://mp.weixin.qq.com/s?__biz=MzI3ODE5Mzc1Ng==&mid=2247504691&idx=1&sn=d62e871ebe46b48bab942aed8ad2f02e&scene=21#wechat_redirect)
[[140页]Neo4j GraphRAG白皮书](https://mp.weixin.qq.com/s?__biz=MzI3ODE5Mzc1Ng==&mid=2247504716&idx=1&sn=fe10dfa1652b20019ea76d2d5fc94de2&scene=21#wechat_redirect)
[[72页]谷歌推出个性化实时监测主动健康管理大模型PH-LLM](https://mp.weixin.qq.com/s?__biz=MzI3ODE5Mzc1Ng==&mid=2247505018&idx=1&sn=fc1a4f328e710fd671f91253479418ac&scene=21#wechat_redirect)
[[180页电子书]GraphRAG全面解析及实践-Neo4j:构建准确、可解释、具有上下文意识的生成式人工智能应用](https://mp.weixin.qq.com/s?__biz=MzI3ODE5Mzc1Ng==&mid=2247505054&idx=1&sn=0c35dba17bd0f74270e0dbd0480f6270&scene=21#wechat_redirect)
[[30页电子书]GraphRAG开发者指南](https://mp.weixin.qq.com/s?__biz=MzI3ODE5Mzc1Ng==&mid=2247505202&idx=1&sn=b1d1c48af604c94391c0d7d8b5346cdf&scene=21#wechat_redirect)
[[550页电子书]2025年10月最新出版-知识图谱与大语言模型融合的实战指南:KG&LLM in Action](https://mp.weixin.qq.com/s?__biz=MzI3ODE5Mzc1Ng==&mid=2247507059&idx=1&sn=891585b48bdf518db7646cba3476f515&scene=21#wechat_redirect)
[[230页电子书]谷歌AI产品负责人撰写《AI产品经理经理指南- 构建人工智能驱动的产品战略、工具和Agent设计》](https://mp.weixin.qq.com/s?__biz=MzI3ODE5Mzc1Ng==&mid=2247505720&idx=1&sn=686e88a5732a996c48a845c04e12c216&scene=21#wechat_redirect)
---
> 💬 本文评论区已开启,但暂无读者留言。
> 本文转载自微信公众号,如有侵权请联系删除。
- 标题: 超越GraphRAG:三层固定实体架构构建下一代高性价比智能问答系统
- 作者: lxiol
- 创建于 : 2026-04-29 20:22:55
- 更新于 : 2026-05-12 16:32:44
- 链接: https://blog.lxiol.cn/2026/04/29/超越GraphRAG三层固定实体架构构建下一代高性价比智能问答系统/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。