4.8MB 的轻量 AI 服务器!Shimmy:用 Rust 打造的极速 LLM API 服务
最近一直在用 Rust 写程序,axum 框架 —— 性能好,开发效率高,本来盘算着基于 axum 自己做一个 LLM 的 API 服务,结果在 GitHub 意外发现了一个类似的宝藏项目:Shimmy(https://github.com/Michael-A-Kuykendall/shimmy),不仅star冲到了4.4k,关键是功能齐全,轻量化、启动快,接下来跟大家详细聊聊。
✨ 起因:想做 Rust AI API,却发现了新大陆
作为 Rust 爱好者,我对高性能、低资源占用的程序有执念。用 axum 写 API 的过程中,我一直在琢磨怎么让 LLM 服务更 “轻”—— 毕竟市面上不少同类工具,要么安装包几百 MB,资源战胜比较大。
直到刷到 Shimmy,才发现有人已经把这个想法落地,并且做得很好:它完全基于 Rust 构建,天生继承了 Rust 的内存安全和高性能特性,最让我惊喜的是,它还做了很多 “人性化” 设计,比如自动加载模型,不用手动配置路径,会自动检索这些位置:
-
-
-
-
1 | `Hugging Face 缓存:~/.cache/huggingface/hub/``Ollama 模型:~/.ollama/models/``本地目录:./models/``环境变量:SHIMMY_BASE_GGUF=path/to/model.gguf` |
不用手动指定模型路径,开箱就能适配常见的模型存放方式,对开发者比较友好了。
🚀 核心亮点:轻,快!
Shimmy 最核心的优势,就是 “轻” 和 “快”。我特意对比了市面上主流的 LLM 服务工具,差距一眼就能看出来:
工具
二进制大小
启动时间
内存占用
OpenAI API 兼容度
Shimmy
4.8MB
<100ms
50MB
100%
Ollama
680MB
5-10s
200MB+
部分兼容
llama.cpp
89MB
1-2s
100MB
需通过 llama-server
4.8MB 的二进制包,不到 100ms 就能启动,内存占用仅 50MB,还 100% 兼容 OpenAI 的 API 格式 —— 意味着你用 ChatGPT 的调用方式,直接就能对接 Shimmy,不用改一行代码,这性价比直接拉满。
💻 实操体验:3 步启动,踩坑与解决
心动不如行动,我立刻动手试了试,安装启动全程超简单,不过踩了个小坑,分享给大家避坑:
第一步:下载二进制包
1 | `curl -L https://github.com/Michael-A-Kuykendall/shimmy/releases/latest/download/shimmy-linux-x86_64 -o shimmy` |

第二步:添加执行权限
1 | `chmod+x shimmy` |
第三步:启动服务(重点避坑!)
我一开始按官方默认命令启动:
1 | `./shimmy serve --gpu-backend auto` |
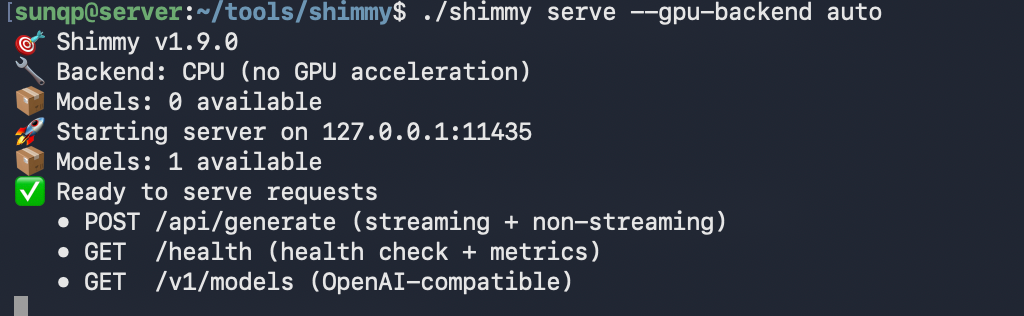
结果发现 GPU 加速没生效,折腾了一下才发现,需要把auto改成vulkan:
1 | `shimmy serve --gpu-backend vulkan` |
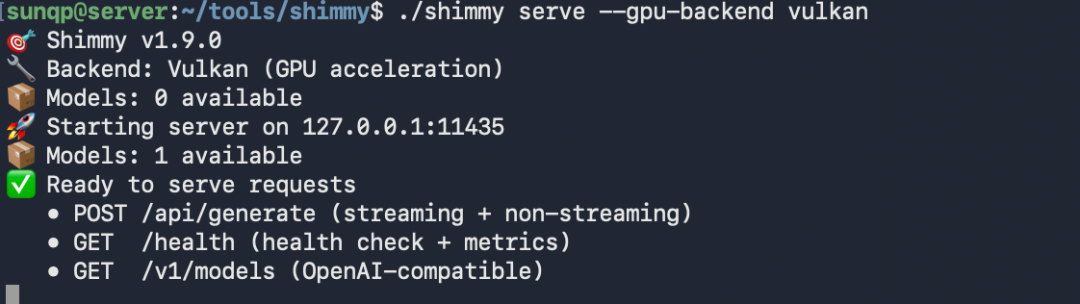
改完之后,GPU 加速正常启用,服务秒启动,全程丝滑无卡顿。
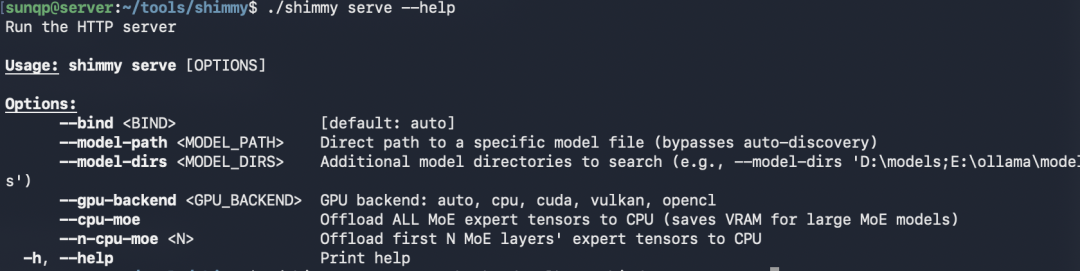
更多的参数如下:
🔌 丰富的 API:兼容 OpenAI,还支持 WebSocket
Shimmy 的 API 设计也很全面,覆盖了常见的使用场景,而且兼容 OpenAI 格式,迁移成本几乎为零:
-
-
-
-
-
1 | `GET /health - 健康检查,快速验证服务是否正常``POST /v1/chat/completions - 兼容 OpenAI 的聊天接口,无缝替换``GET /v1/models - 列出当前可用的模型``POST /api/generate - Shimmy 原生 API``GET /ws/generate - WebSocket 流式输出,适合实时交互场景` |
不管是想快速替换 OpenAI 接口,还是用原生接口做定制化开发,都能满足。试一下模型的接口,结果如下:
-
-
-
-
1 | `# 命令``curl http://127.0.0.1:11435/v1/models``# 结果``{"object":"list","data":[{"id":"phi3-lora","object":"model","created":1777205296,"owned_by":"shimmy"},{"id":"qwen3.6-27b-ud-q8-k-xl","object":"model","created":1777205296,"owned_by":"shimmy"},{"id":"qwen3.6-35b-a3b-q8-0","object":"model","created":1777205296,"owned_by":"shimmy"},{"id":"qwopus3.5-27b-v3-q8-0","object":"model","created":1777205296,"owned_by":"shimmy"}]}` |
🎯 最后:爱折腾的开发者值得一试
作为一个偏爱轻量、高性能工具的开发者,Shimmy 给我的体验远超预期:Rust 加持的极致轻量化、毫秒级启动速度、100% 的 OpenAI API 兼容,还有自动加载模型的贴心设计,爱折腾的同学可以试一下,有问题欢迎在评论区交流。
💬 本文评论区已开启,但暂无读者留言。
本文转载自微信公众号,如有侵权请联系删除。
- 标题: 4.8MB 的轻量 AI 服务器!Shimmy:用 Rust 打造的极速 LLM API 服务
- 作者: lxiol
- 创建于 : 2026-04-29 20:24:58
- 更新于 : 2026-05-12 16:07:03
- 链接: https://blog.lxiol.cn/2026/04/29/48MB-的轻量-AI-服务器Shimmy用-Rust-打造的极速-LLM-API-服务/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。