一键把杂乱文档变成结构化知识图谱!开源 Hyper-Extract:LLM驱动的超强知识提取神器,Hypergraph + 时空图全支持
一键把杂乱文档变成结构化知识图谱!开源 Hyper-Extract:LLM驱动的超强知识提取神器,Hypergraph + 时空图全支持

一键把杂乱文档变成结构化知识图谱!Hyper-Extract:LLM驱动的超强知识提取神器
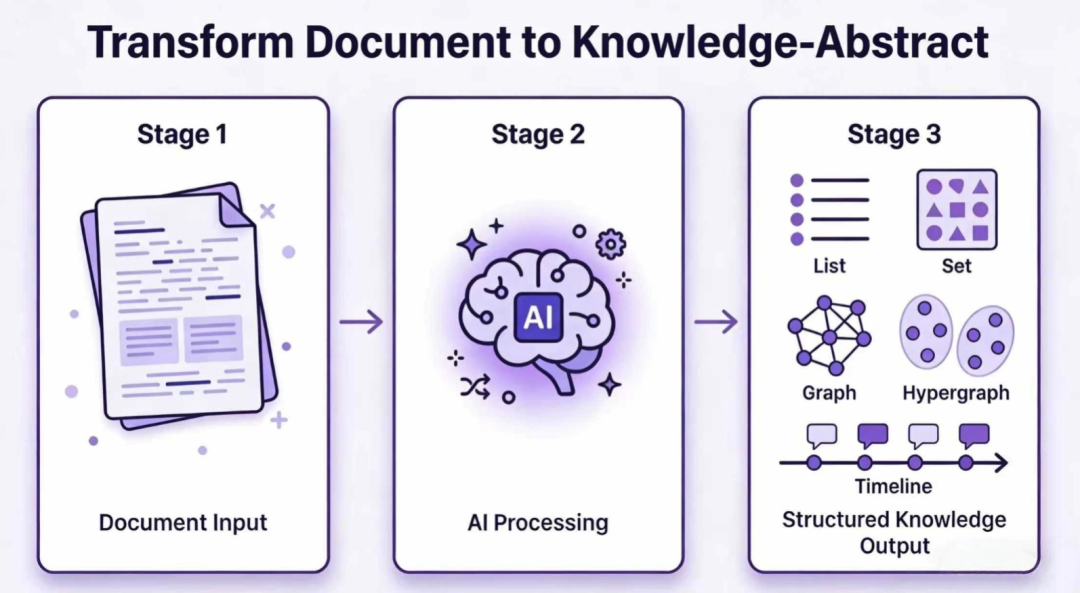
每天面对海量非结构化文本:研究报告、新闻文章、合同、病历、历史资料……阅读容易,真正“理解”和“利用” 很极难。传统工具难以应对复杂关系,而大语言模型(LLM)虽强大,却缺乏系统化的结构化输出能力。
Hyper-Extract(yifanfeng97/Hyper-Extract)一个智能的、LLM驱动的知识提取与演进框架,以一条命令 将高度非结构化的文本转化为持久化、可预测、强类型的 Knowledge Abstracts(知识摘要)。从简单列表到复杂知识图谱、超图(Hypergraph),甚至时空图(Spatio-Temporal Graph),全部支持。
✨ 核心功能全解析
Hyper-Extract 的设计是拥抱复杂性,同时极大简化使用。核心特性包括:
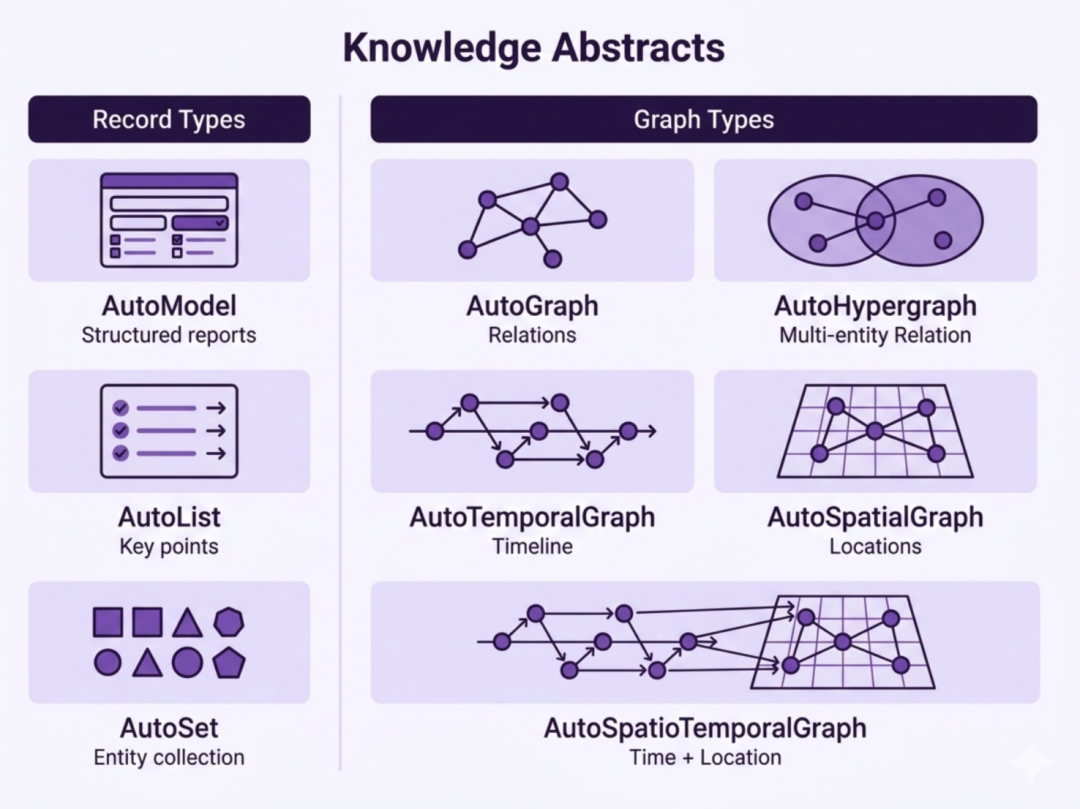
1.8 大 Auto-Types(强类型知识结构)
框架输出数据结构基础,基于 Pydantic 实现类型安全、可序列化、支持增量合并和可视化操作。分为两大类:
○Record Types(记录型,无实体关系):
▪AutoModel:提取单个结构化对象(如公司财报摘要、产品规格)。输出为固定字段的 Pydantic 模型。
▪AutoList:有序集合(排行榜、步骤序列)。保持原始顺序。
▪AutoSet:去重集合(关键词、唯一实体列表)。自动消除重复。
○Graph Types(图结构,带实体关系):
▪AutoGraph:二元关系知识图谱(实体-关系-实体)。经典 KG 结构。
▪AutoHypergraph:超图,支持多实体(3+)参与的复杂关系(如多方协作、合同多方当事人)。支持扁平列表或嵌套角色分组。
▪AutoTemporalGraph:时序图,在关系上附加时间维度(事件时间线)。
▪AutoSpatialGraph:空间图,附加地理位置信息。
▪AutoSpatioTemporalGraph:时空图,同时支持时间 + 空间,实现完整“谁、何事、何时、何地”上下文。
2.10+ Extraction Engines(提取引擎)
开箱即用多种先进方法:
○RAG-based:GraphRAG、LightRAG、Hyper-RAG、HypergraphRAG、Cog-RAG 等,支持检索增强生成,提升大规模文档处理准确性。
○Typical:KG-Gen、iText2KG、iText2KG* 等传统知识图谱生成方法。
用户可通过模板或 API 灵活选择最适合的引擎。
3.Declarative YAML Templates(声明式 YAML 模板)
零代码定义提取逻辑。内置 80+ 预设模板,覆盖 6 大领域:Finance(金融)、Legal(法律)、Medical(医学)、TCM(中医)、Industry(工业)、General(通用)。
模板包含:语言、名称、类型、描述、output schema(字段定义)、guideline(提取指引、规则)、identifiers(唯一标识规则)、display(可视化标签)。
支持自定义模板,详见 DESIGN_GUIDE.md。
4.Incremental Evolution(增量演进)
核心亮点之一:已提取的 Knowledge Abstract 支持 feed 新文档 持续扩展,无需重新处理全部数据。知识可持久化、搜索和演化。
5.CLI + Python API 双模式
○CLI(he 命令):适合快速处理、批量操作。
○Python SDK:深度集成,支持自定义 pipeline。
其他实用功能:多语言支持(en/zh 等)、搜索查询知识摘要、可视化(he show 或 ka.show())、配置管理(API Key 等)、序列化保存/加载。
安装方法
推荐使用 uv(现代 Python 包管理器):
●CLI 全局安装(推荐大多数用户):
uv tool install hyperextract
安装后即可全局使用 he 命令。
●作为 Python 库安装:
uv pip install hyperextract
从源码安装(开发/最新版):
1 | ●●●bash |
项目使用 pyproject.toml + uv.lock 管理,兼容性强。
使用方法
CLI(默认使用 gpt-4o-mini + text-embedding-3-small):
1 | ●●●bash |
Python API 示例:
1 | ●●●python |
支持批量处理、自定义方法选择等高级用法。详见 examples/ 目录和官方文档。
技术原理、架构与实现方式
Hyper-Extract 采用 三层架构,清晰解耦,便于扩展:
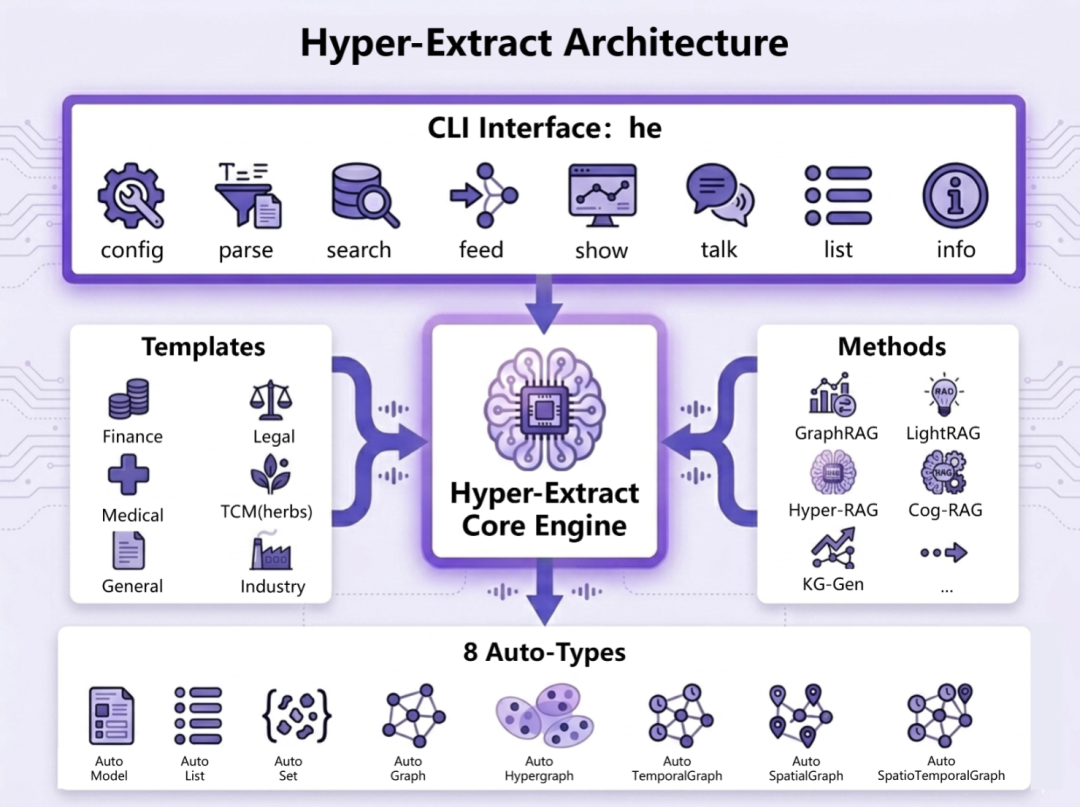
1.Layer 1: Auto-Types(数据层)
核心是 8 个强类型类(位于 hyperextract/types/),继承自 base.py。
○使用 Pydantic 验证字段、支持 JSON 序列化。
○内置方法:search()、visualize()、save()、merge() 等。
○Graph 类型实现节点/边/超边管理,Temporal/Spatial 添加专用字段和标识逻辑(identifiers 中的 time_field、location_field)。
2.Layer 2: Methods(算法层)
hyperextract/methods/ 下分 rag/ 和 typical/ 子目录。
○RAG 方法利用检索增强,提升长文档上下文处理和准确性(GraphRAG 等经典范式)。
○Typical 方法聚焦直接提示工程 + 结构化解析。
通过 registry.py 注册和管理引擎,用户可切换或扩展。
3.Layer 3: Templates(配置层)
YAML 驱动,hyperextract/templates/presets/ 提供领域模板。
○Schema vs Guideline 分离:output 定义“提取什么”(字段、类型),guideline 定义“如何高质量提取”(规则、避免常见错误)。
○identifiers 确保实体/关系唯一性(e.g., relation_id 模板字符串)。
○display 控制可视化标签生成。
DESIGN_GUIDE.md 详细说明设计流程、决策树、类型特定最佳实践和 QA 检查列表。
数据流:文档 → Template(加载 YAML + Prompt 构建)→ Method(LLM 调用)→ Auto-Type 实例(验证 + 后处理)→ 可持久化 Knowledge Abstract。支持增量是因为 Auto-Types 设计为可合并的。
项目Python 实现,依赖 LLM API(OpenAI 兼容)。可视化可能集成 NetworkX 或类似库生成图谱。
在复杂结构支持(Hypergraph、时空)、开箱即用模板、CLI 便利性 和 增量演进 上具有显著优势。适合研究者、开发者、分析师、企业知识管理等场景。
—— 如此才是
把复杂的技术,讲成你真正能用上的生产力
零基础也能玩转卫星!开源Ground Station + SDR 打造个人地面站全攻略
OpenClaw & Hermes刷屏后,GitHub Mercury Agent如何打动用户? 灵魂驱动+权限铁闸+24/7永动 vs 两大竞品
苹果M系列芯片的福音!无需H100、无需云GPU,本地MacBook就能微调Gemma 4多模态模型
开源Minecraft终极杀手!12.7K星GitHub神器Luanti(原Minetest)完整中文攻略:零基础安装、2800+模组随便玩、服务器+源码编译
AI 直接操控 Unity/Godot/Unreal 编辑器!用 OpenClaw + TomLeeLive 插件,聊天就能把你的游戏梦想变成现实
老婆/女朋友每天早上纠结45分钟穿什么?GitHub 开源AI衣柜神器 Wardrowbe 彻底解放!完整自托管安装+使用教程
开源项目Paseo,AI编码代理跨设备统一指挥中心:统管Claude Code、Codex、OpenCode(以及Copilot、Pi等)
Notebook LM平替,开源Open Notebook:隐私零泄露、18+AI模型随意切、1-4人定制播客秒生成
30MB Rust无头浏览器Obscura:击败Chrome、V8真实JS+CDP全兼容,AI Agent与爬虫的隐形核武器
Rust重写的jcode:性能碾压Cursor Claude Code 139倍的下一代Coding Agent Harness,人类级内存图谱+多会话Swarm
Warp开源震撼发布!5年Rust GPU终端+Oz Agentic开发环境完整拆解:功能全览、源码编译教程、核心架构深度解析
💬 本文评论区已开启,但暂无读者留言。
本文转载自微信公众号,如有侵权请联系删除。
- 标题: 一键把杂乱文档变成结构化知识图谱!开源 Hyper-Extract:LLM驱动的超强知识提取神器,Hypergraph + 时空图全支持
- 作者: lxiol
- 创建于 : 2026-05-06 19:54:44
- 更新于 : 2026-05-12 16:07:04
- 链接: https://blog.lxiol.cn/2026/05/06/一键把杂乱文档变成结构化知识图谱开源-Hyper-ExtractLLM驱动的超强知识提取神器Hypergraph-时空图全支持/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。