我在 Prompt 里加了四个字,Claude Code 的输出质量提升了一倍
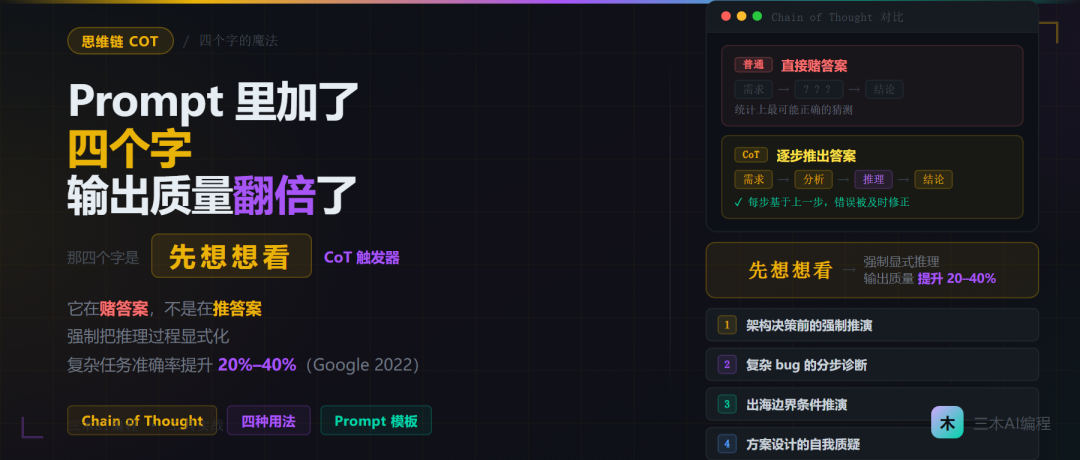
那四个字是:”先想想看”。
不是开玩笑。我有一段时间对 Claude Code 的某类输出不满意——它给的方案太”第一反应”,浅、快、有时候是错的。我以为是 Prompt 写得不够细,结果加了一堆约束也没用。
后来我试着在任务描述后面加了一句:在开始写代码之前,先把你的思路梳理一遍,说说你打算怎么实现。
输出质量肉眼可见地提升了。不是偶然,是每次都有效。
这背后有一个正经的技术原理,名字叫 Chain of Thought。
你以为 AI 是在”想”,其实它在”赌”
大多数人用 Claude Code 的方式是:描述需求,等输出,看结果。
这没问题,大多数简单任务够用。
但有一类任务,这种方式会系统性地给你差结果:需要推理的任务。
需要推理的意思是:答案不是直接检索出来的,而是需要经过多步判断才能得到。比如:帮我设计一个兼容月付和年付的优惠券系统;帮我分析这段代码的性能瓶颈在哪;帮我判断这个功能应该用 Server Action 还是 API Route。
这类任务,如果你直接让它给结论,它给的是”统计上最可能正确的答案”。不是它想清楚了,是它猜了一个看起来合理的结果。
说人话就是:它在赌,不是在想。
Chain of Thought(思维链)解决的就是这个问题。核心原理是:强制它把推理过程显式地写出来,而不是直接跳到结论。
一旦推理过程显式化,它就不得不一步一步地推,而不是猜。每一步推理都基于上一步的结果,错误更容易在过程中被发现和修正,最终结论的质量也就更高。
我当时傻乎乎地以为这是什么玄学技巧,后来研究了一下发现这是有论文支持的——Google 2022 年的研究显示,在复杂推理任务上,CoT 能让准确率提升 20% 到 40%。这不是小数字。
CoT 在 Claude Code 里的四种用法
用法一:架构决策前的强制推演
做技术选型,不要直接问”我应该用 X 还是 Y”。
直接问的问题是:它会给你一个骑墙的答案,把两边的优缺点都列一遍,然后来一句”取决于你的具体情况”——毫无价值。
换成 CoT 写法:
我需要在 Next.js 14 里实现用户订阅状态的全局共享,有两个方案:React Context 放在 layout.tsx 里,或者用 Zustand。
请按照这个顺序思考:
- 先分析这个状态的特点:更新频率、使用场景、是否需要持久化
- 基于分析,判断两个方案各自适合什么场景
- 对照我的具体情况(订阅状态在 Dashboard 的多个子页面都需要读取,但很少更新),给出明确的推荐
- 说出你推荐这个方案的最关键理由(只要一条,最重要的那条)
这个 Prompt 的结构强制它走完整个推理链,而不是直接给你”看情况”的废话答案。
最后那条”只要一条”很重要——它迫使它做取舍,而不是把所有考虑因素都列出来推给你。
用法二:复杂 bug 的分步诊断
遇到难以定位的 bug,用 CoT 让它做系统性排查,而不是猜测。
用户反馈:他们的 Stripe 订阅显示 active,但进入我的付费功能页面时显示”请升级订阅”。
帮我系统性地排查这个问题,按以下步骤思考:
- 首先列出”订阅 active 但被判断为未付费”可能的原因(至少 5 个)
- 对每个原因,说明如何验证它是否是真正的原因
- 按照”最可能出错”到”最不可能出错”的顺序排列这些原因
- 从排名第一的原因开始,帮我写出检查代码
它会给你类似这样的推理过程:
1 | `可能原因: |
大多数教程不告诉你的细节: CoT 让它列出的”可能原因清单”,本身就是价值所在。很多时候你自己排查的时候,会漏掉某个可能性,而它的系统性列举能帮你补上盲区。
用法三:出海场景的边界条件推演
做出海产品,有一大类需求特别适合 CoT:涉及时区、货币、国际化的逻辑。
这类需求表面上简单,但实际上有很多不显眼的边界条件。
举个真实案例,我需要实现一个”年度账单周期提醒”功能,在订阅到期前 7 天、3 天、1 天分别发一封邮件。
直接让它实现,它会给我一个基于 UTC 当前时间减法的逻辑,看起来没问题,但实际有坑:
在开始实现之前,先帮我分析这个功能的边界条件:
- 时区问题:Stripe 的 current_period_end 是 Unix timestamp,我的提醒逻辑应该基于 UTC 还是用户本地时区计算”7天前”?
- 重复发送问题:如果定时任务每小时跑一次,怎么防止同一封邮件被发多次?
- 取消订阅的用户:如果用户在提醒周期内取消了订阅,还要不要继续发剩余的提醒?
- 新用户:刚注册的用户如果订阅周期正好是 7 天内,会不会在注册当天就收到”即将到期”的邮件?
把这四个问题都分析清楚,每个给出处理建议,然后再开始写实现代码
这四个边界条件,没有 CoT 的引导,它写的代码里可能一个都没覆盖。有了这个分析过程,生成的代码里会自动包含这些处理逻辑。
用法四:方案设计的自我质疑
这是 CoT 最高阶的用法,也是最容易被忽视的。
让它设计完一个方案之后,立刻让它质疑自己:
你刚才设计的这个方案,现在站在反对方的立场上,列出这个方案的三个最大弱点,每个弱点说明在什么情况下会产生问题
这个技巧的价值是:它自己设计方案时的优化方向,和它批评方案时的角度不同。两者互补,能帮你找到方案的盲点。
我在做 Stripe Webhook 的幂等性设计时用过一次,它设计的方案是用 Redis 记录已处理的 event_id。然后让它质疑自己,它说出了:如果 Redis 重启或者键过期了,会有漏处理的风险——这个问题在它设计阶段没有提到,但在质疑阶段说出来了。
踩坑环节
坑一:用了 CoT,它的推理过程太长,淹没了真正的答案
有一次我让它做一个复杂的架构分析,它给我输出了 800 字的推理过程,最后的结论埋在最后两行,我差点没看到。
这种情况的问题不是 CoT 没用,是我没有让它控制输出结构。
解决方案: 在 Prompt 末尾加一句:思考过程用简短的要点形式呈现,最终结论单独一段加粗显示。格式约束和 CoT 不冲突,加上格式要求能让推理过程可读、结论突出。
坑二:让它”先想想”,结果它想到一半开始写代码了
有几次我说”先分析再实现”,它分析到一半觉得方向清楚了就直接开始写代码,分析没做完,代码也写得不全。
两步走没走完,掉在中间了。
解决方案: 把分析和实现拆成两次对话。第一次只让它分析,明确说”这次只分析,不写代码,等我确认方向之后再实现”。分析结果你看完觉得没问题,再开启第二次对话让它实现。
这样做的额外好处是:分析阶段你可以纠正它的判断,实现阶段的方向是经过你确认的,不会出现”写完了发现方向不对”的情况。
总结
CoT 的本质是:把 AI 的推理从隐式变显式,从”赌一个答案”变成”推出一个答案”。
在 Claude Code 里,凡是需要判断、需要取舍、需要分析的任务,都值得用 CoT 触发一遍。直接要答案的代价是:你得到了一个看起来合理但可能有重大遗漏的方案。
多花两分钟写 CoT Prompt,省掉的是上线后排查问题的几小时。
最后一个值得认真想的问题: 你在用 Claude Code 时,有没有某个反复让它做但结果老是不稳定的任务类型——今天对明天偏?如果有,把那个任务描述出来,试着改成 CoT 结构重新问一次,看看结果是否更稳。结果告诉我。
💬 本文评论区已开启,但暂无读者留言。
本文转载自微信公众号,如有侵权请联系删除。
- 标题: 我在 Prompt 里加了四个字,Claude Code 的输出质量提升了一倍
- 作者: lxiol
- 创建于 : 2026-05-06 19:58:17
- 更新于 : 2026-05-12 16:07:04
- 链接: https://blog.lxiol.cn/2026/05/06/我在-Prompt-里加了四个字Claude-Code-的输出质量提升了一倍/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。