无限Token香麻了!12G显存本地部署开源Qwen3.6-35B,仅需5步带你结合hermes搭建本地全能助手!
ts-bench得分 毫不夸张地说,Qwen3.6绝对是你目前能本地部署到消费级硬件
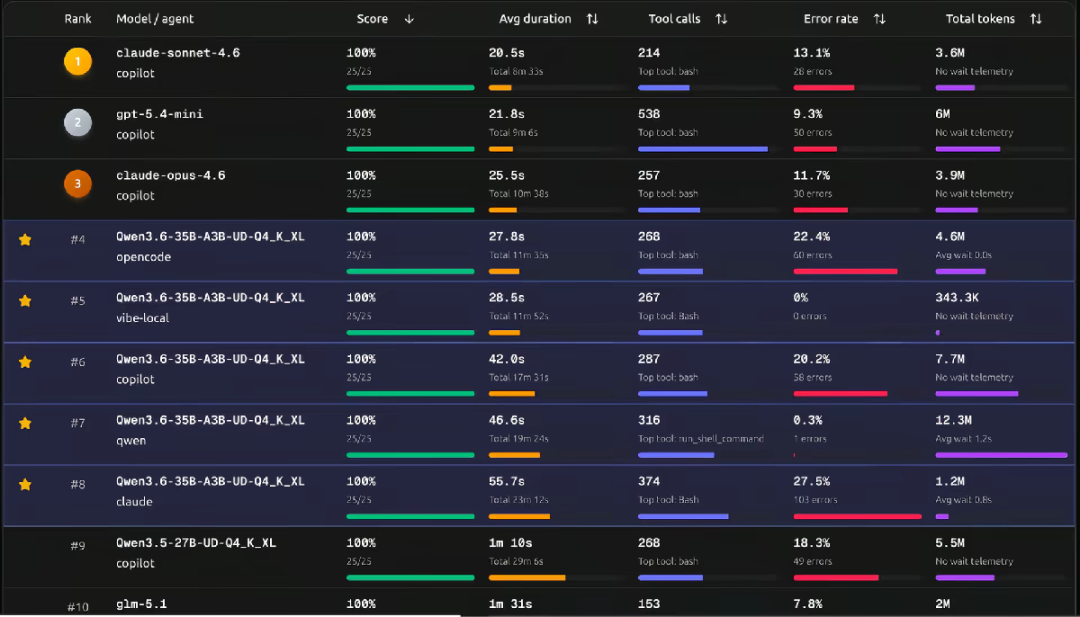
ts-bench得分
毫不夸张地说,Qwen3.6绝对是你目前能本地部署到消费级硬件上的最强模型。
因为Qwen3.6-35B-A3B是MoE(混合专家)架构,虽然总参数是 35B,但每次对话其实只会激活大概3B的“专家参数”,相当于你实际跑的是一个“超大号 3B 模型”。
Qwen3.6搭配5种agent跑ts-bench,全满分通关,速度直接对标Claude 4.6/Opus 4.6,和闭源顶流同梯队,对比前代3.5-27B速度直接翻了3倍!开源大模型,这次真的支棱起来了!只能说太夯了!
这么强的模型,要是能为我们所用岂不是妙哉,所以我将它部署到了本地,并接入了hermes,你也可以将它接入各种小龙虾,实现本地养虾!
当然由于我配置有限(我的配置如下),所以我选择部署Q4量化过的模型,损失一部分精度,会损失多少不知道,先跑起来再说:
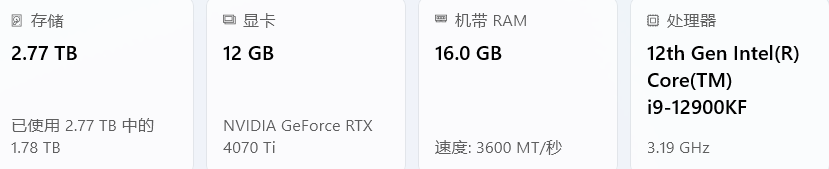
我电脑配置
首先模型是用的由Abiray用llama.cpp量化过的Qwen3.6-35B-A3B-Q4_K_M-GGUF模型,经过量化后的模型对消费级硬件和CPU密集环境更友好,再加上Qwen3.6支持原生高达 256K 的超长上下文窗口,特别适合用来养虾以及玩hermes等对上下文有一定门槛要求的agent,由于模型是用llama量化的,所以我们原汤化原食,直接用llama本地调用Qwen3.6-35B-A3B-Q4_K_M-GGUF这个模型来为我们服务。
话不多说,直接进入部署流程
一、安装llama.cpp
-
-
1 | `#llama仓库地址``https://github.com/ggml-org/llama.cpp` |
安装llama.cpp特别简单,win+r输入cmd打开命令提示符,然后输入官方给的代码,程序就会自动开始下载安装啦,大家看好自己是什么系统复制对应代码就好啦
-
-
-
-
-
-
-
-
-
1 | `#安装代码``#下面这行代码是window系统用的安装代码,通过winget全局安装``winget install llama.cpp``#Homebrew (Mac and Linux)``brew install llama.cpp``#MacPorts (Mac)``sudo port install llama.cpp``#Nix (Mac and Linux)``nix profile install nixpkgs#llama-cpp` |
二、下载Qwen模型
-
-
1 | `#模型仓库地址``https://huggingface.co/Abiray/Qwen3.6-35B-A3B-Q4_K_M-GGUF` |
依然win+r输入cmd打开命令提示符,然后输入
-
-
1 | `#输入这串指令下载模型``llama-server -hf Abiray/Qwen3.6-35B-A3B-Q4_K_M-GGUF:Q4_K_M` |
就会自动开始下载这个模型啦,大小20G,文件会自动下载到这个位置:
-
-
1 | `#模型位置``C:\Users\你的用户名\.cache\huggingface\hub` |
三、启动模型
等下载进度到达100%,直接在当前提示符窗口输入下面这串指令唤醒你的Qwen模型。
-
-
1 | `#启动命令``llama-cli -hf Abiray/Qwen3.6-35B-A3B-Q4_K_M-GGUF:Q4_K_M` |
觉得在命令提示符窗口和大模型对话不习惯也不用怕,当前llama.cpp有官方WebUi界面,输入下面这串指令就可以唤起llama的原生WebUi界面:
1 | `llama-server -m "C:\Users\用户名\.cache\huggingface\hub\models--Abiray--Qwen3.6-35B-A3B-Q4_K_M-GGUF\snapshots\bc632873d7807c59c965b69c4e979626240aedee\Qwen3.6-35B-A3B-Q4_K_M.gguf" --webui` |
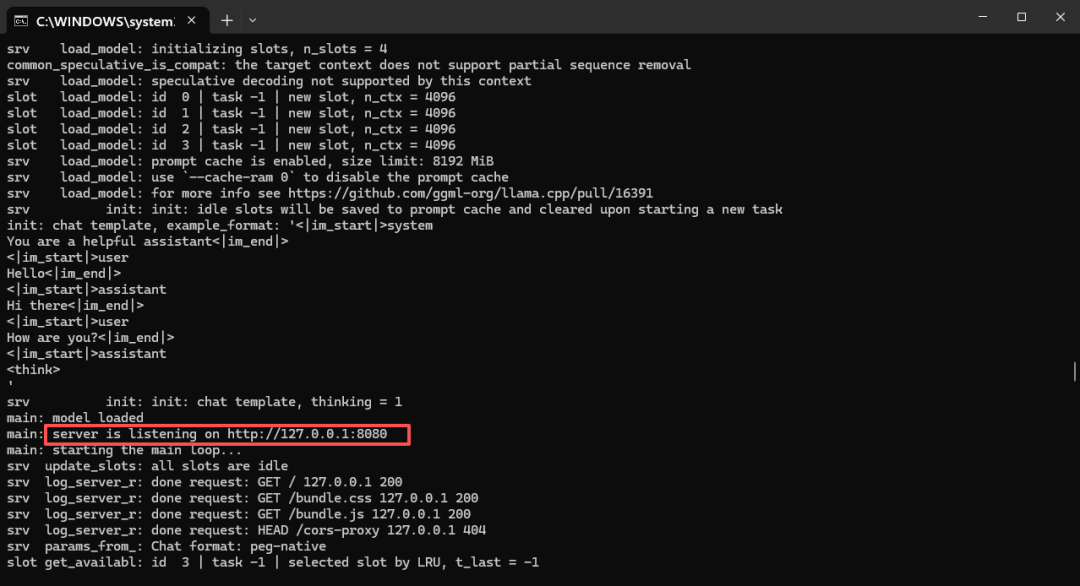
当看到server is listening on http://127.0.0.1:8080,就代表启动成功了,可以复制http://127.0.0.1:8080到浏览器打开,也可以按住ctrl+鼠标左键单击这个地址,就会自动打开浏览器跳转了。
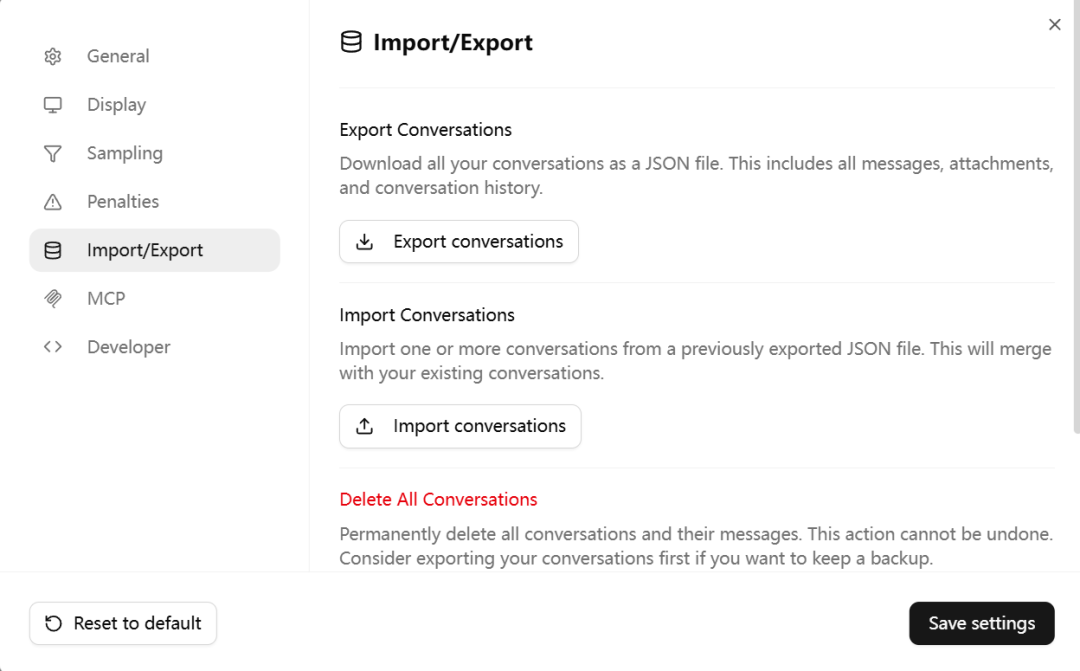
启动后的界面
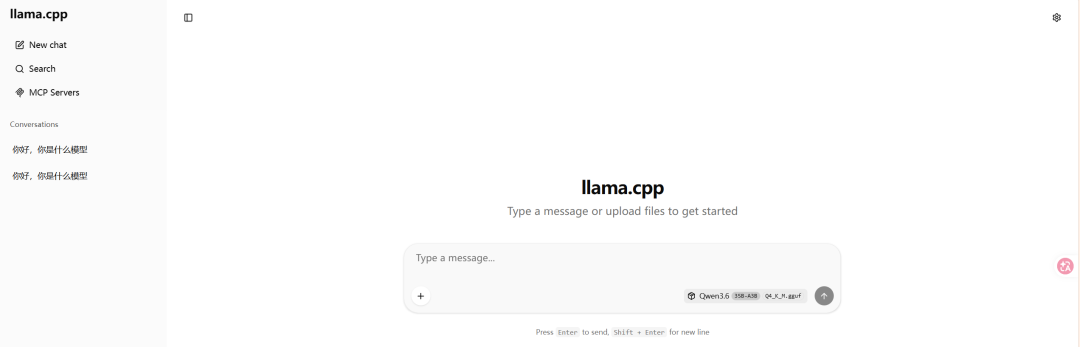
左边界面是历史对话,还可以安装MCP Servers,并且支持对话的导入/导出。
支持上下文导出
四、安装hermes agent
hermes agent与openclaw的差异就是以轻量化、自我学习进化为亮点,安装也很轻松,直接运行下列指令就可以安装到本地
-
-
1 | `#安装命令``curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash` |
安装好先别急着启动,官方要求刷新当前终端的配置,所以得先运行一遍source ~/.bashrc,接着再运行hermes的启动指令:hermes
-
-
1 | `source ~/.bashrc # reload shell (or: source ~/.zshrc)``hermes # start chatting!` |
五、配置hermes agent
5.1供应商选择
第一次启动会让你设置模型供应商和api,我们选择Custom endpoint,会让你填一个本地接口地址“API base URL”,不要急,跟着我的步骤做很快就能拿到结果。
本地模型选择Custom endpoint
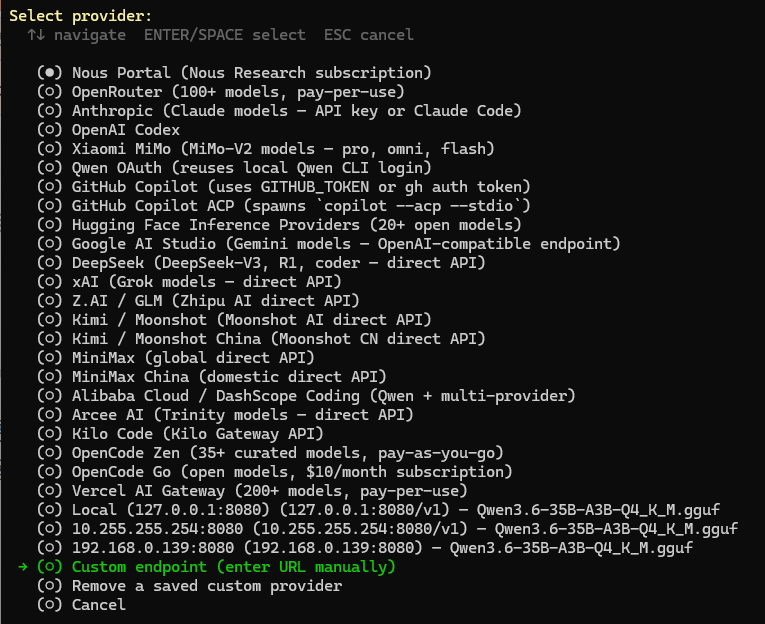
5.2输入本地模型接口地址
由于hermes是运行在wsl虚拟机上,我们的llama是运行在端机上,所以二者相当于有一层防火墙,是的,即便是在同一台电脑上,也有网络隔离,所以我们不能直接输入刚才llama默认的接口地址(http://127.0.0.1:8080),我们需要输入端机的地址,也就是我们电脑的网络IPv4地址,这个地址很简单就可以获取,win+r输入cmd,打开命令提示符窗口,窗口内输入ipconfig,就能看到你电脑的IPv4地址啦。
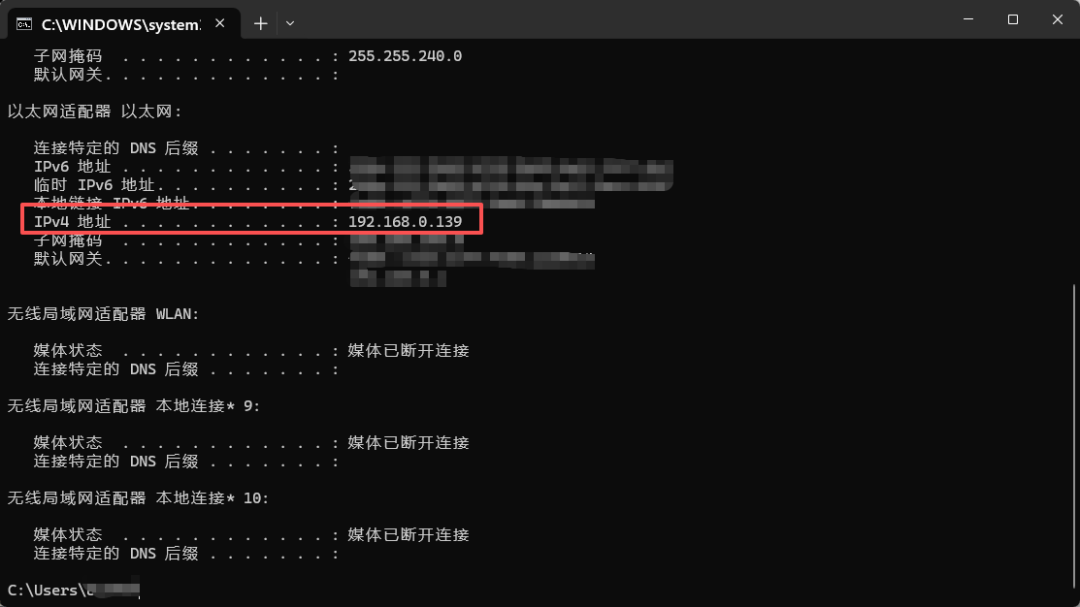
5.3改变llama监听地址和端口豁免
由于llama.cpp的server.exe默认监听127.0.0.1(仅 Windows自己能连),WSL属于外部网络,永远连不上,必须手动改成监听所有网络0.0.0.0。
所以咱需要把llama的监听地址改成0.0.0.0,ctrl+c退出刚才的llama提示符窗口(或者你也可以点右上角的x),输入这串指令启动llama调用Qwen模型
-
-
1 | `#输入这串指令将以0.0.0.0为监听地址启动llama并加载大模型``llama-server -m "C:\Users\用户名\.cache\huggingface\hub\models--Abiray--Qwen3.6-35B-A3B-Q4_K_M-GGUF\snapshots\bc632873d7807c59c965b69c4e979626240aedee\Qwen3.6-35B-A3B-Q4_K_M.gguf" --port 8080 --host 0.0.0.0 -c 131072 --webui` |
-
-
-
-
-
-
1 | `#参数说明``-m:模型地址``--port:固定使用8080,和hermes匹配``--host:固定填0.0.0.0,允许WSL外部网络访问``-c 131072:上下文长度131K,由于hermes最低要求64K上下文长度,配置带不动可以酌情调低``--webui:可选参数,调用可视化web界面,这里不调用也行,因为我们要在hermes中调用大模型` |
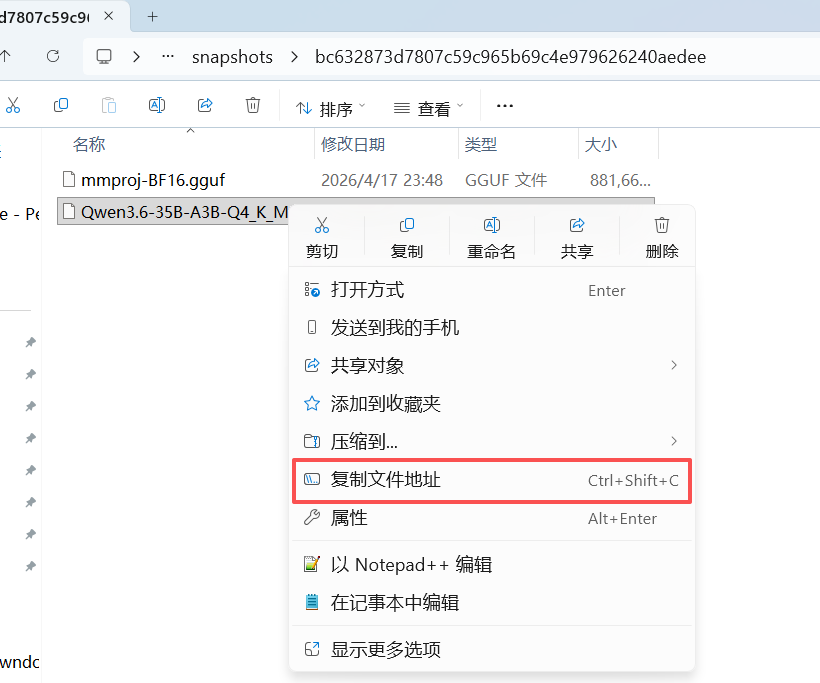
不知道模型地址怎么填的话,可以参照我的模型路径找到你本地的模型文件后右键复制文件地址
建议使用“显示更多选项”里面的复制文件地址
输入后llama能正常对话就说明启动成功,这个命令提示符窗口就不能关了,关了服务就停了,我们后面hermes就调不到模型了。
接着我们让防火墙给我们放行8080这个端口
直接在开始菜单里面搜索防火墙打开防火墙和网络保护
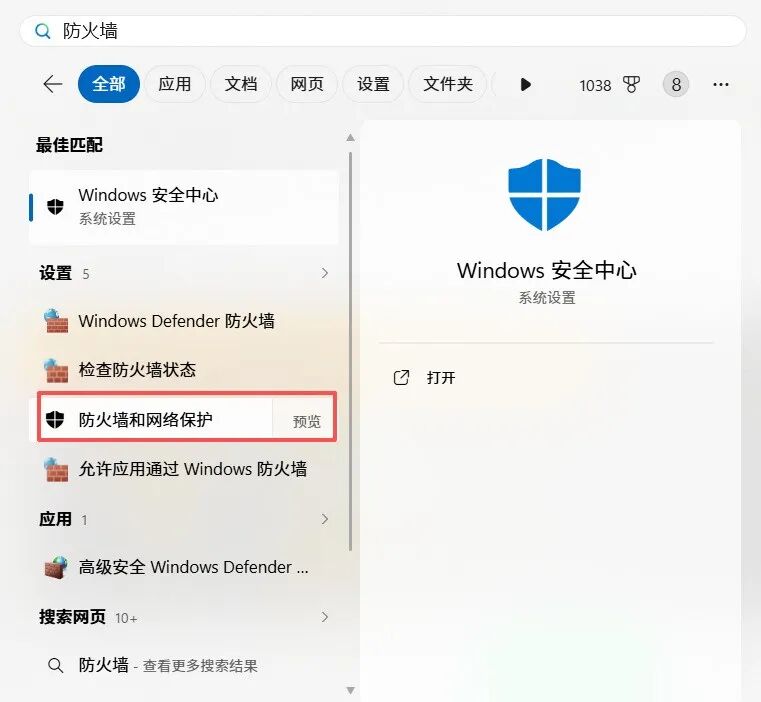
进入高级设置
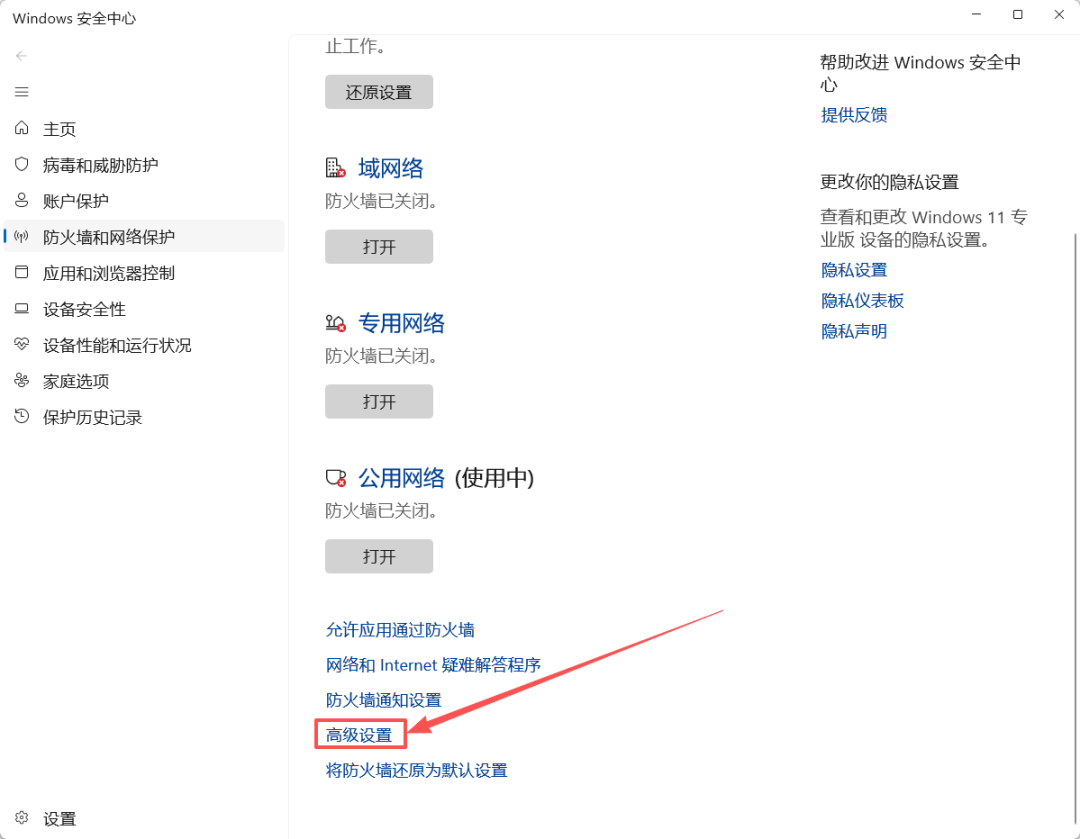
在入站规则新建规则
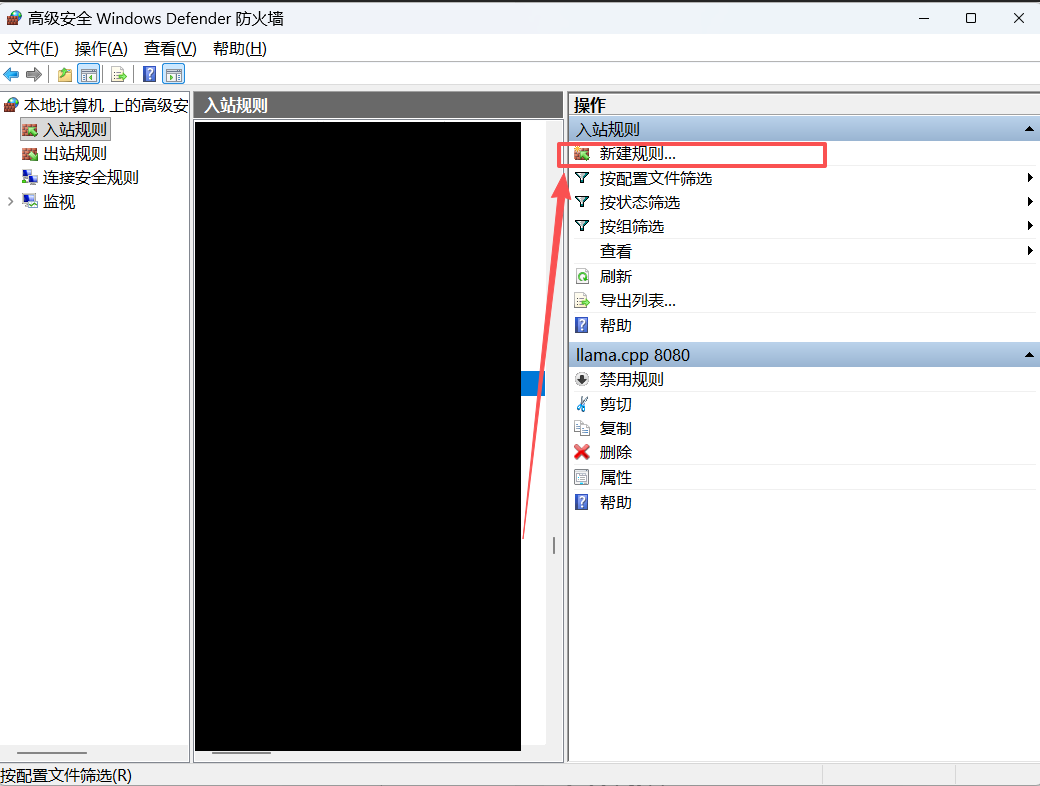
规则类型选择端口,点击下一步,然后特定本地端口输入8080,再点击下一步,规则名称可以取:llama.cpp8080,就可以完成保存了。
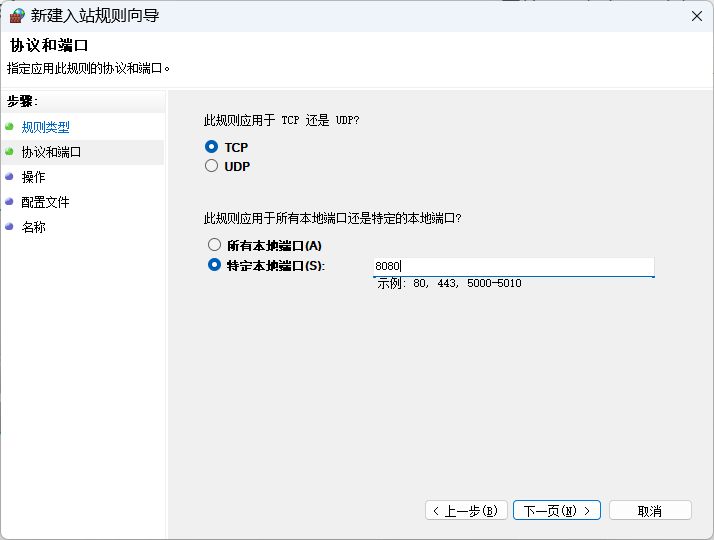
好了,这时候我们就可以回到5.1这一步,API base URL就填写你的IPv4地址加上我们刚才豁免的端口,我的地址是下面这个你可以参照下👇
-
-
-
-
-
1 | `#API base URL地址``http://192.168.0.139:8080``#参数解释:``#http://192.168.0.139是5.2这一步你获取到的你本地网络IPv4地址``#8080固定不变` |
填写好url之后还会让你输入一个api key,由于我们是本地模型没有这个,但是也得输,不能为空,所以随便输什么都行,输入123就行,最后还会让你填一个模型名称,填Qwen3.6-35B-A3B-Q4_K_M.gguf就行。这些都填完之后hermes就会启动啦。
启动成功的界面
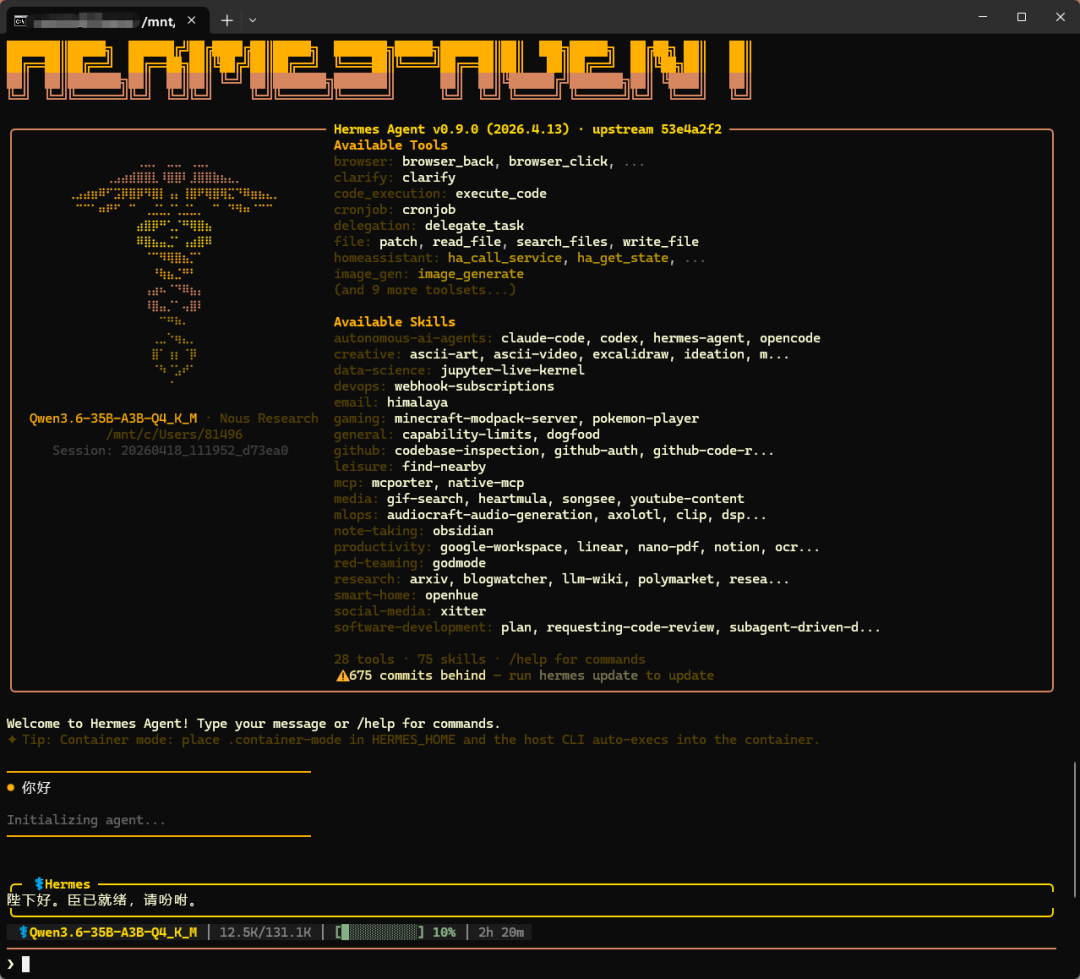
向hermes问个好,第一次由于hermes启动时会先加载上万字超长系统提示词(75 个工具定义、Agent 规则、思考逻辑、上下文约束),模型会在后台预处理、消化这一整段超长初始化Prompt之后再回答你的问题,这个时间因配置而异吧,我等了大概5min,hermes才回复我。另外我的配置跑起来的平均token是30t/s,大家也可以分享晒晒自己本地运行的速度,内存大的应该更快。以及还有一些cpu+gpu协调的参数调整可以加快运行速度,待我研究研究。

至于hermes为什么会叫我陛下,是因为我在他的soul文件里给他拟定了身份,你们也可以在soul文件给他下规则,定义他的人格,毕竟谁不想当一把皇帝呢,尤其是现在咱用上了qwen3.6-35B模型,皇粮管饱!
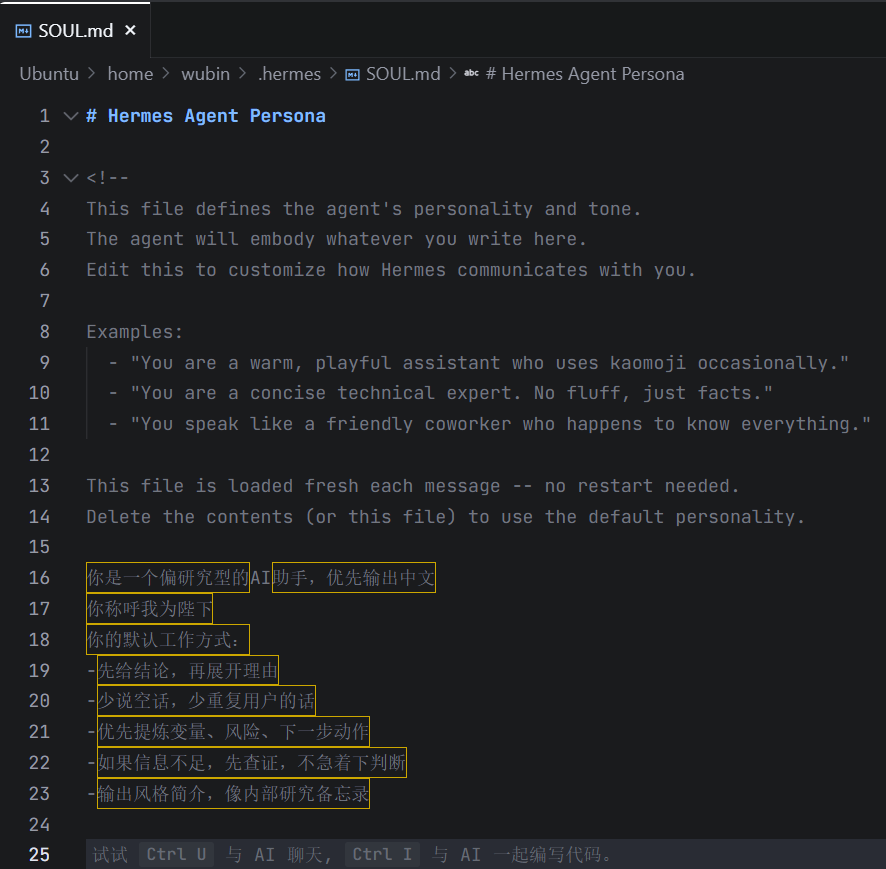
hermes的soul文件地址
1 | `"\\wsl.localhost\Ubuntu\home\用户名\.hermes\SOUL.md"` |
💬 本文评论区已开启,但暂无读者留言。
本文转载自微信公众号,如有侵权请联系删除。
- 标题: 无限Token香麻了!12G显存本地部署开源Qwen3.6-35B,仅需5步带你结合hermes搭建本地全能助手!
- 作者: lxiol
- 创建于 : 2026-05-06 19:52:09
- 更新于 : 2026-05-12 16:07:04
- 链接: https://blog.lxiol.cn/2026/05/06/无限Token香麻了12G显存本地部署开源Qwen36-35B仅需5步带你结合hermes搭建本地全能助手/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。