「Gemma 4」把MacBook变成“实时视频大脑”!再叠一层SAM3分割:离线多模态终于能用了吗?
「Gemma 4」把MacBook变成“实时视频大脑”!再叠一层SAM3分割:离线多模态终于能用了吗?
导读
一台三年前的M2 MacBook,本地同时跑两个开源模型:Gemma 4负责“看懂视频、实时生成描述/解释”,SAM3负责“把每个物体像素级抠出来并跟踪”。演示者强调三连:No cloud / No API / Running locally。端侧多模态不再只是“能跑”,而是开始变得实时、可操作、可组合——你的视频数据,第一次可以真正不出门。
🎬 1小时做出“本地实时视频理解”,网友直接炸了
这条推文是整个选题的“第一性证据”。
“Gemma 4 just dropped. I had it captioning video in real-time within an hour.”
「Gemma 4 刚发布,我不到一小时就让它实现了视频实时字幕/描述。」
“Running locally on a MacBook. No cloud. No API. Real-time scene understanding.”
「在 MacBook 上本地跑。不上云、不要 API,实时理解场景。」
“Oh and SAM3 is segmenting every object in the same frame. Same laptop.”
「顺便,SAM3 在同一帧里把每个物体都分割出来。还是同一台笔记本。」
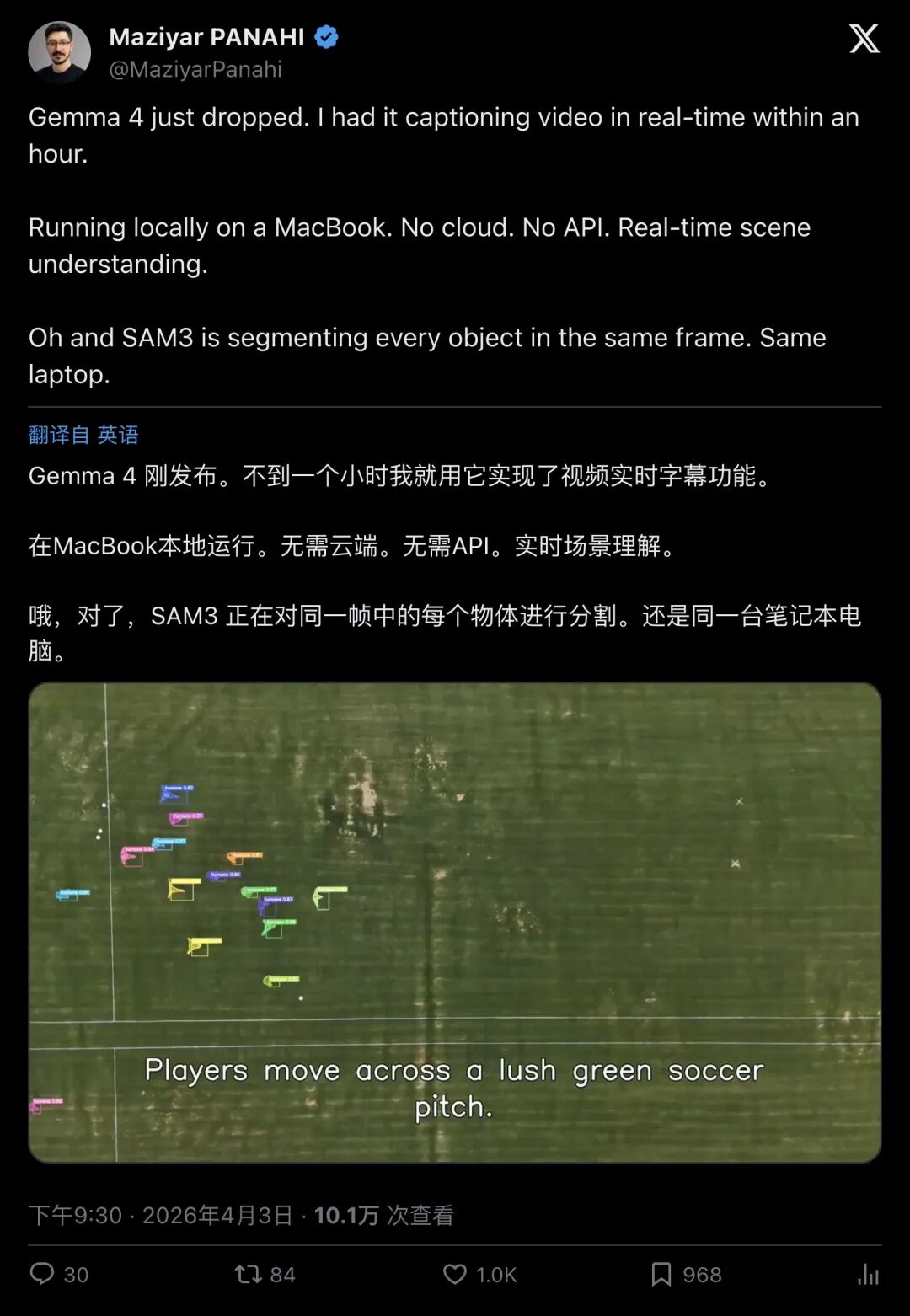
▲ @MaziyarPanahi:本地跑、实时场景理解,同时SAM3同帧分割(约10万人围观)
最狠的地方在于:它不是“本地跑了个模型”这么简单。
它把两件过去很难同时做到的事,塞进了同一台MacBook里:
- 语义层(理解/解释/叙事)
:VLM 读视频帧,产出“发生了什么”。 - 像素层(定位/抠图/跟踪)
:分割模型给出“它在哪儿、边界多精确、怎么动”。
这才是“端侧多模态”真正迈进产品形态的一步。
🧩 Gemma 4 + SAM3:一个讲故事,一个负责把世界“抠出来”
很多人第一反应会误会:视频里那些彩色框/遮罩,是不是 Gemma 4 直接做的?
演示者把分工说得很直白:
“So the SAM3 is the one that does the segmentations. Gemma 4 models cannot do that, in real-time, with that accuracy.”
「做分割的是 SAM3。Gemma 4 做不到这种精度的实时分割。」
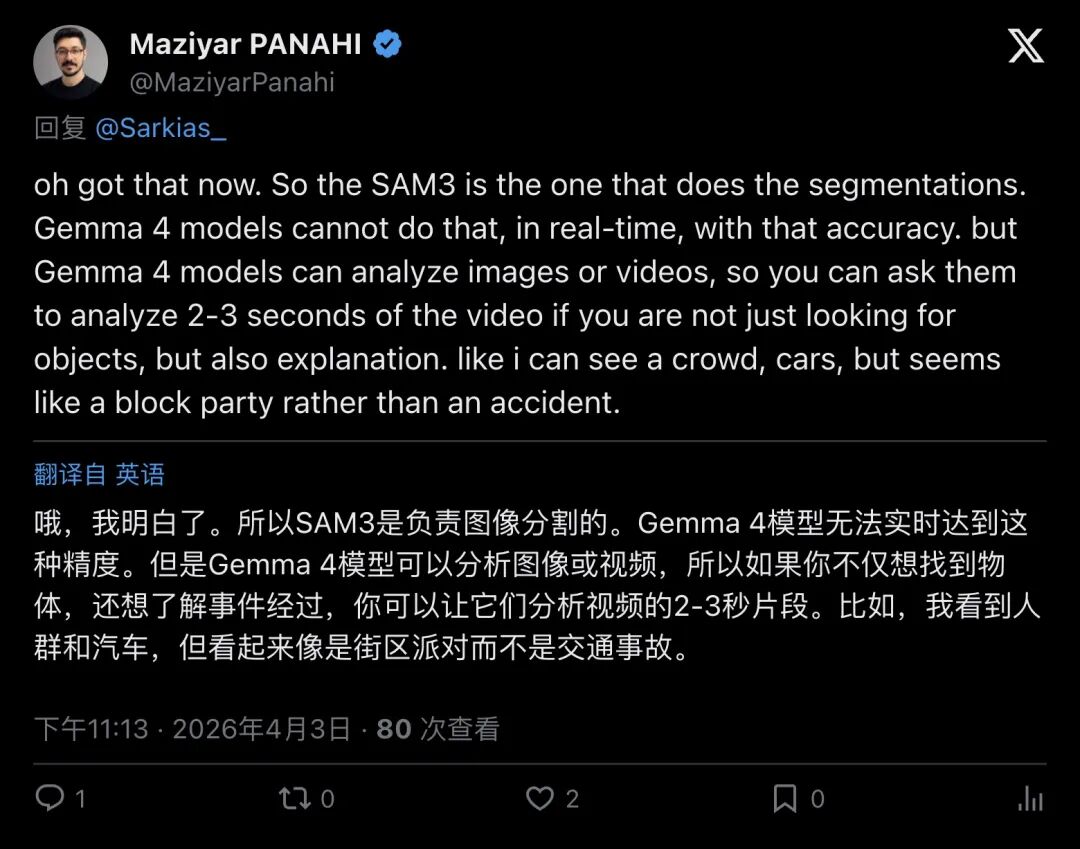
▲ @MaziyarPanahi:SAM3负责分割;Gemma 4更适合做2-3秒片段的解释
把这句话翻译成“工程语言”,就是一张非常清楚的组件表:
层
模型
做什么
你能拿它干嘛
语义层
Gemma 4
(多模态)
看懂帧序列,输出描述/解释/意图
事件理解、字幕/旁白、生成指令、做决策说明
像素层
SAM3 / SAM 3.1
(分割/跟踪)
像素级mask + 跨帧跟踪
抠图、计数、轨迹、区域测量、局部裁剪再回喂
工具链
LM Studio / MLX生态(mlx-vlm等)
让模型在Mac上跑得起来
本地服务、量化、推理加速、接入应用
一旦你把“理解”和“精确定位”拆开,组合空间就突然变大了。
🖥️ 配置被扒得很干净:M2 + 4bit + LM Studio + SAM3 bf16
这次演示之所以有传播力,还因为它给了“可复现”的味道——不是一句“我跑起来了”,而是把关键参数直接甩出来。
“Gemma 4 … 4-bit served via @lmstudio on an M2 MacBook.”
「Gemma 4 用 4-bit 量化,通过 LM Studio 在 M2 MacBook 上提供服务。」
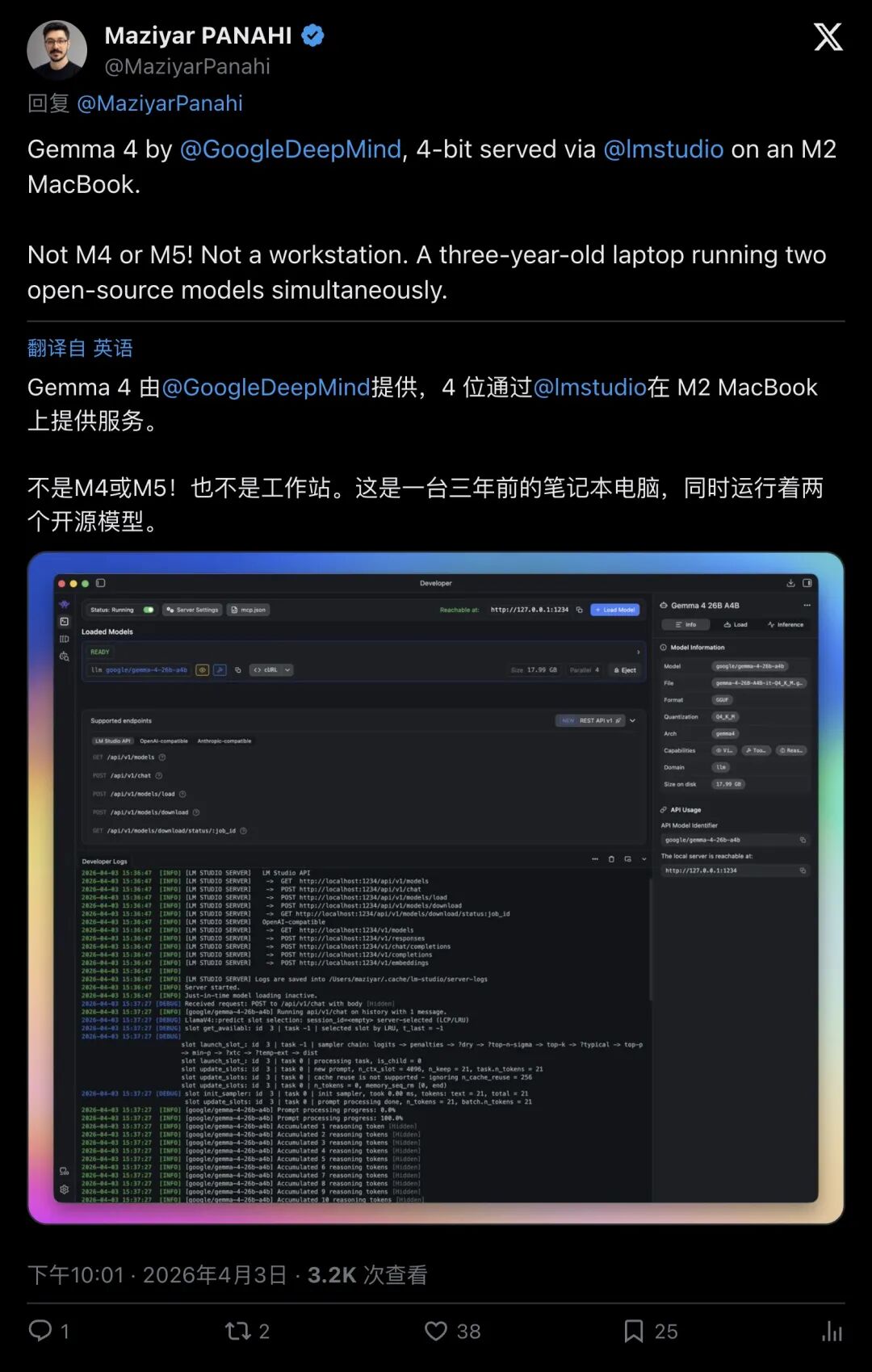
▲ M2 MacBook 本地服务 Gemma 4(4-bit),同机跑两个开源模型
更进一步,他补充了组合:
“I used SAM3 (bf16) and google/gemma-4-26b-a4b 4bit served by @lmstudio”
「SAM3 用 bf16;Gemma 4 用 google/gemma-4-26b-a4b 的 4bit,通过 LM Studio 服务。」
(补充:他还明确提到自己用的是SAM3 bf16,以及 google/gemma-4-26b-a4b 的4-bit版本,通过 LM Studio 服务。)
端侧从来没有“免费午餐”。他也顺手给了一个现实边界:同时跑会发热(原推文中直接提到 M2 MacBook Pro 变热)。
这点其实很关键:
- 端侧的成本从“钱”变成了“热、功耗、续航、稳定性”。
- 真实产品要解决的问题,会落到“能不能持续跑”“有没有散热冗余”“能否按需触发”。
⚡ Day‑0工具链:mlx‑vlm把“刚发布”变成“立刻能跑”
另一个容易被忽略的爆点,是生态速度。
Gemma 4 这类新模型刚发布,社区工具链就跟上了“day‑0 support”。
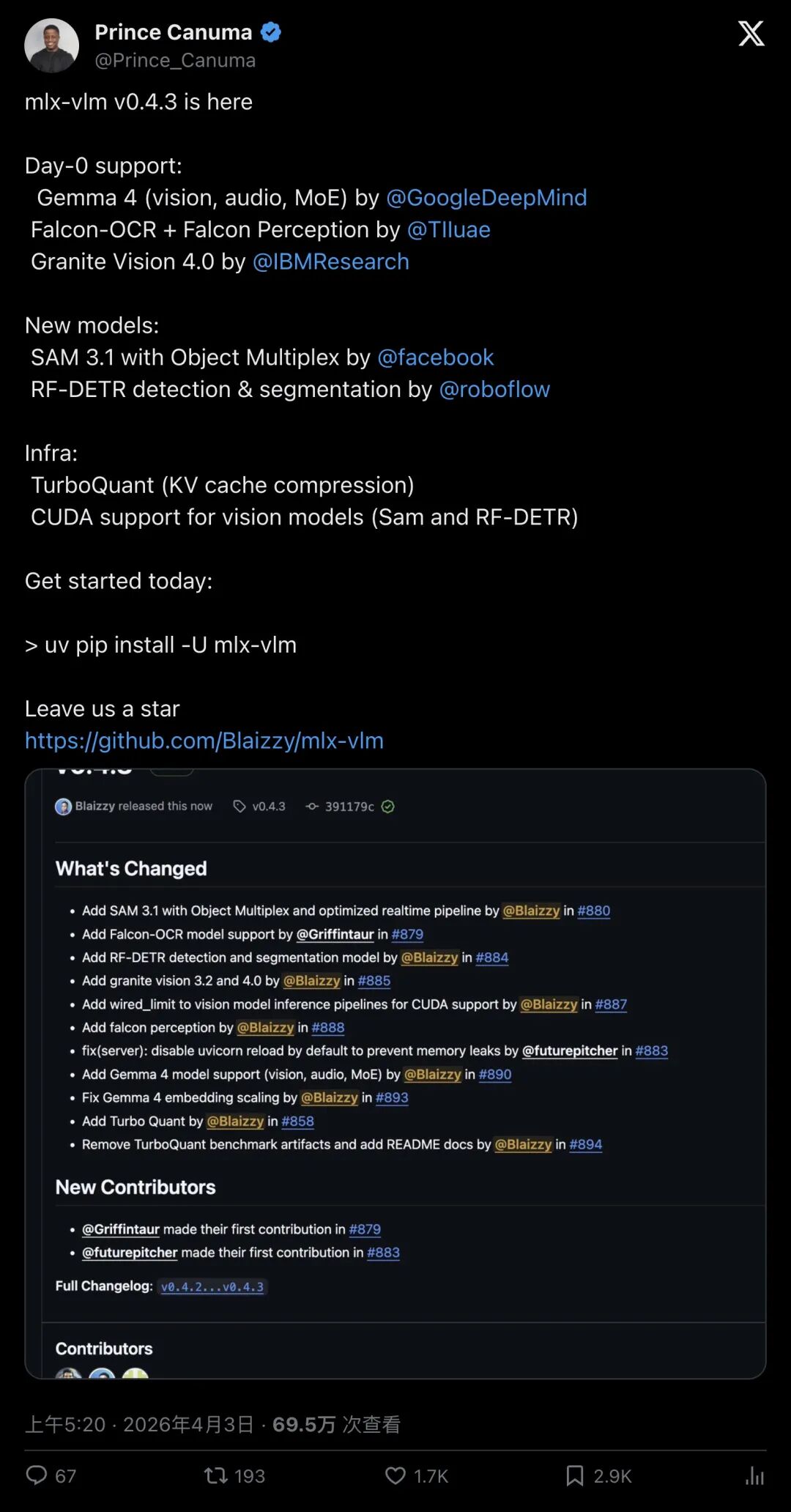
▲ @Prince_Canuma:mlx‑vlm v0.4.3 宣布 day‑0 支持 Gemma 4,同时引入 SAM 3.1(Object Multiplex)等
写到这里要把“事实”和“传播”分开:
- 传播侧
:推文说“day‑0 support”,读者会兴奋。 - 可核验侧
:GitHub release notes 里确实出现了“Add Gemma 4 model support”“Add SAM 3.1 with Object Multiplex …”等条目(来源:mlx‑vlm Releases)。
你会发现,真正让端侧爆发的,往往要靠一整套组合拳:
模型 + 工具链 + 量化 + 端侧生态一起卡位。
🤖 下一步更吓人:Gemma先“看懂”,再给SAM自动写prompt
如果说“本地实时理解 + 分割”是第一幕,那第二幕就是端侧 agent 化。
演示者自己提了一个更像产品的工作流:
“…use gemma 4 to understand the video, then ask gemma to come up with a prompt for SAM… dynamically…”
「先让 Gemma 4 理解视频,再让它动态生成给 SAM 用的 prompt;我甚至不需要知道该跟踪什么。」
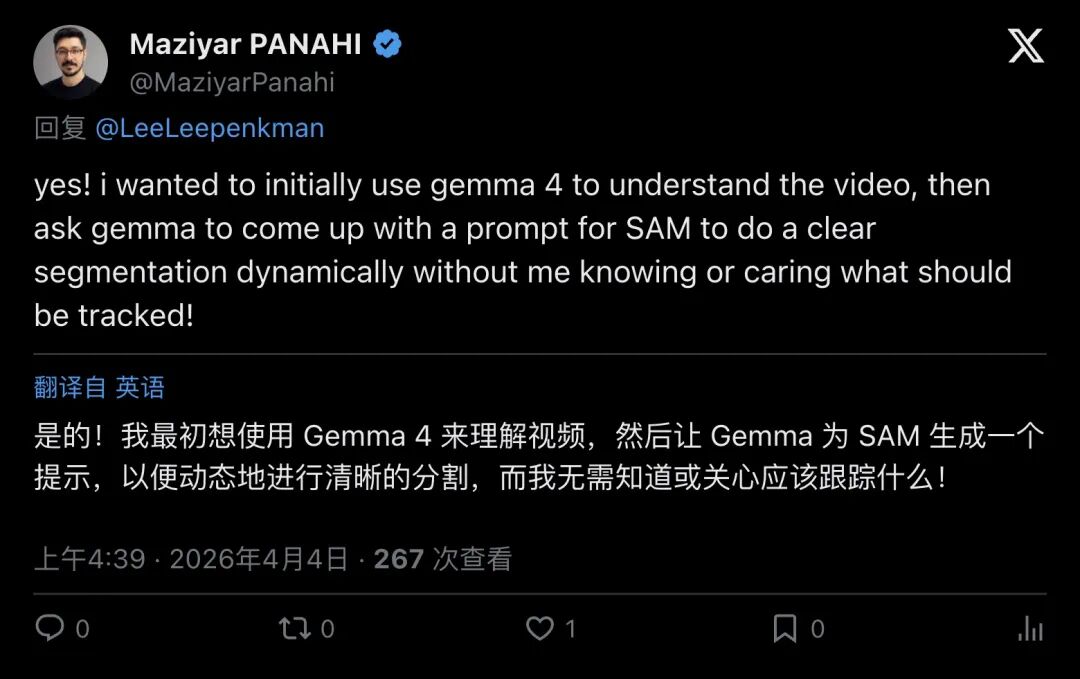
▲ 让VLM当“大脑”,分割模型当“手”:端侧工具调用的典型雏形
这段话的潜台词很明确:
- VLM 负责提出“我要关注什么”。
- SAM3 负责执行“把它抠出来并跟踪”。
- 需要时把 mask 区域裁剪回喂给 VLM,做更深解释与决策。
这就是端侧“能行动”的多模态。
❓网友当场泼冷水:分割到底有什么用?
热闹之下,总有人问一句最现实的问题:分割有什么用?
▲ 网友:我没懂分割的应用场景
这问题问得好,因为它会逼你把“AI炫技”翻译成“可落地的动作”。
一个很强的解释来自 @grok(观点类内容,作参考):
“Segmentation isn’t useless—it’s the precision layer Gemma 4 needs for real-world action.”
「分割并不鸡肋,它是让模型在真实世界里采取行动所需的精确层。」

▲ 用“烟雾检测/安防摄像头/无人机”举例:描述 + 精确定位,才能做可执行的告警
把它落到具体场景,大概就是三类:
- 安防/巡检/无人机
:先理解“疑似烟雾”,再用分割锁定“烟在哪儿”,做面积/速度/方向量化,才能触发告警。 - 视频剪辑/特效
:理解“主角在画面左侧走动”,分割才能做实时抠像、背景替换、局部打码。 - 数据生产
:分割 + 少量人工校对,显著加速视频标注与训练数据构建。
理解给你“意义”,分割给你“可操作的边界”。两者叠在一起,才像产品。
🧨 更大的信号:端侧多模态开始进入“实时+可控”时代
这波讨论里,有人一句话点破时代变化:
“a year ago this pipeline required a cloud GPU cluster.”
「一年前,这套流程还得靠云端GPU集群。」
现实当然更复杂:演示没有公开严格 FPS/分辨率/延迟/RAM 占用,这些都要等更多复现与基准。
但趋势已经很清晰:
- 本地
:数据不出设备,隐私与成本叙事成立。 - 多模态
:模型不只读文本,开始真正“看懂”视频片段。 - 实时
:从离线分析走向现场反馈。 - 工具化
:SAM3 这类像素工具开始变成 VLM 的“外挂能力”。
你以为这只是“极客玩具”?
当它变成 SDK、变成工作流、变成默认能力时,很多行业会被迫重新回答一个问题:
当摄像头视频第一次可以“本地实时理解+精确分割”,你还敢把它随便上传到云端吗?
— END —
— END —
💬 本文评论区已开启,但暂无读者留言。
本文转载自微信公众号,如有侵权请联系删除。
- 标题: 「Gemma 4」把MacBook变成“实时视频大脑”!再叠一层SAM3分割:离线多模态终于能用了吗?
- 作者: lxiol
- 创建于 : 2026-05-06 20:01:04
- 更新于 : 2026-05-12 16:07:03
- 链接: https://blog.lxiol.cn/2026/05/06/Gemma-4把MacBook变成实时视频大脑再叠一层SAM3分割离线多模态终于能用了吗/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。