HERMES+Obsidian,管理自己的知识库。
这篇文章是我的学习总结,100%实践后的原创,分享给大家。一,我的hermes知识库搭建流程,HERMES+Obsidiang,共建知识库。
这篇文章是我的学习总结,100%实践后的原创,分享给大家。
一,我的hermes知识库搭建流程。
1、原始数据的积累。
我的原始知识库,是我多年积累的电子书、论文、零散的文章、新闻。。。
我集中到一个文件夹作为我平时学习的图书馆。
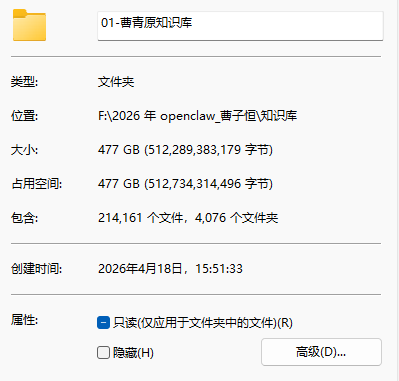
这里分好类,利于我检索,大概是477GB,图片和视频比较占地方。
2、执行贝叶斯系统对文章进行打分,分级,去重复,转换成MD文件。
算是清洗入库的过程。
3、我的贝叶斯系统流程介绍。(详细阐述)
我的 贝叶斯系统 (BENS V4.0 + 五脑协同) 是一套“让本地知识库越用越聪明”的 AI 自动化流水线。它不仅仅是一个存文件的地方,而是一个具备“消化、提炼、推理”能力的知识工厂。
以下是为你整理的系统标准解释、核心功能及使用流程:
📘 一、 系统标准解释 (Standard Definitions)
1. 核心灵魂:贝叶斯四维打分 (BENS)
每一篇进入系统的文件,都要经过这套公式的严格拷问,算出一个 0.0 ~ 1.0 的分数:
C (可信度):来源权威吗?有引用吗?(如:博士论文=0.95,自媒体水文=0.3)
U (实用性):能解决问题吗?干货密度高吗?
T (时效性):是最新的吗?(旧知识会随时间自然贬值)。
D (精炼度):废话多吗?(越短小精悍分数越高)。
公式:$Score = C^{0.35} \times U^{0.25} \times T^{0.25} \times D^{0.15}$
2. 知识分级 (L0 - L4)
根据算出的分数,文件被自动贴上等级标签,决定它的“地位”:
👑 L0 权威著作:镇馆之宝,领域巅峰(如顶级教材、博士论文)。
🏛️ L1 学术级:核心资产,可直接引用的学术干货。
📊 L2 报告级:专业深度内容,行业研报、技术分析。
📚 L3 科普级:通俗易懂的知识,入门读物。
📦 L4 沉淀池:碎片化笔记、半成品,等待日后升舱。
📝 L5 曹青原写作:你的私人创作区,独立于 AI 库,存放你的灵感和文章。
3. 五脑协同 (Five Brains)
这是 AI 处理知识的“大脑分工”:
🔣 符号脑:提取知识的骨架(逻辑、公式、实体),负责推理。
🧠 语义脑:将内容转为向量(Embedding),负责检索与联想。
🧮 逻辑脑 (Z3):负责查错,检测知识之间有没有逻辑冲突。
💾 经验脑:记录系统运行过的任务和经验,负责记忆复用。
🔧 辅助脑:负责干杂活(联网、工具调用、格式转换)。
🔄 二、 文件流转全生命周期 (File Lifecycle)
文件在系统中会经历“原材料 → 精矿 → 智慧”的变形:
1. 采集 (Input):
- 我将文件放入 01-曹青原知识库(PDF/EPUB/DOCX),或者在 Obsidian 里写完笔记。
2. 粗加工 (Extract):
- AI 自动提取文本,清洗杂质,转化为 MD (Markdown) 格式。
3. 精炼 (Grade):
AI 运行贝叶斯打分,算出分值,打上标签(L1/L2…)。
人类文件保留原样不动(方便你看)。
AI 文件被搬运到 精选知识库 对应的 L 级目录。
4. 消化 (Digest):
符号脑提取骨架。
语义脑建立索引。
逻辑脑进行体检。
5. 输出 (Output):
- 生成《曹青原 AI 助理工作报告》,展示今天系统长了多少“脑子”。
🚀 三、我的使用流程 (User Workflow)
作为“总管”,你只需要做动作,剩下的由 AI 闭环完成。
场景 1:我要存一篇新论文/电子书
动作:把文件扔进 F:...\01-曹青原知识库\24-论文 或 23-电子书。
指令:对我说 “入库”。
系统自动执行:
- 提取文本 -> 贝叶斯打分 -> 存入精选库 (L2) -> 五脑喂食 -> 更新报告。
- 结果:你可以在 精选知识库 (AI 用) 和 Obsidian 中看到带元数据的 MD 文件。
场景 2:我在 Obsidian 写了篇日记/笔记
动作:在 Obsidian (路径:…\Obsidian 知识库) 中写完并保存。
指令:对我说 “同步 Obsidian” 或 “入库”。
系统自动执行:
- 扫描新笔记 -> 评估价值 -> 若高质量则自动晋级 L2/L3 -> 喂给五脑。
- 结果:你的笔记变成了 AI 永久记忆的一部分。
场景 3:我想看系统今天的表现
指令:对我说 “体检”。
结果:我会打开最新的 HTML 仪表盘,让你看到 L0-L4 的文件数变化、五脑健康度、以及新增了多少高分知识。(这个表或者是在线查看器都可以用HERMES快速便器出来。)
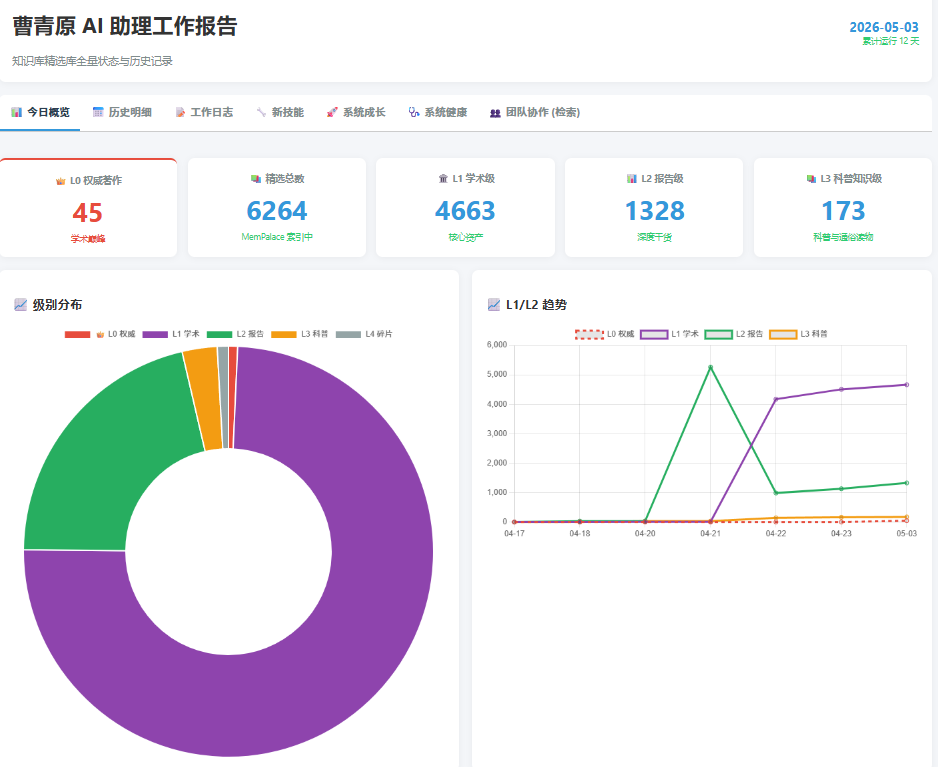
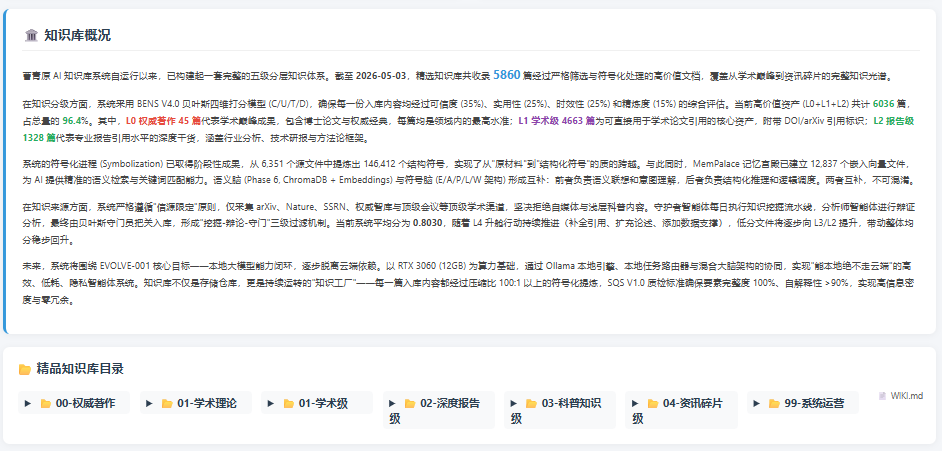
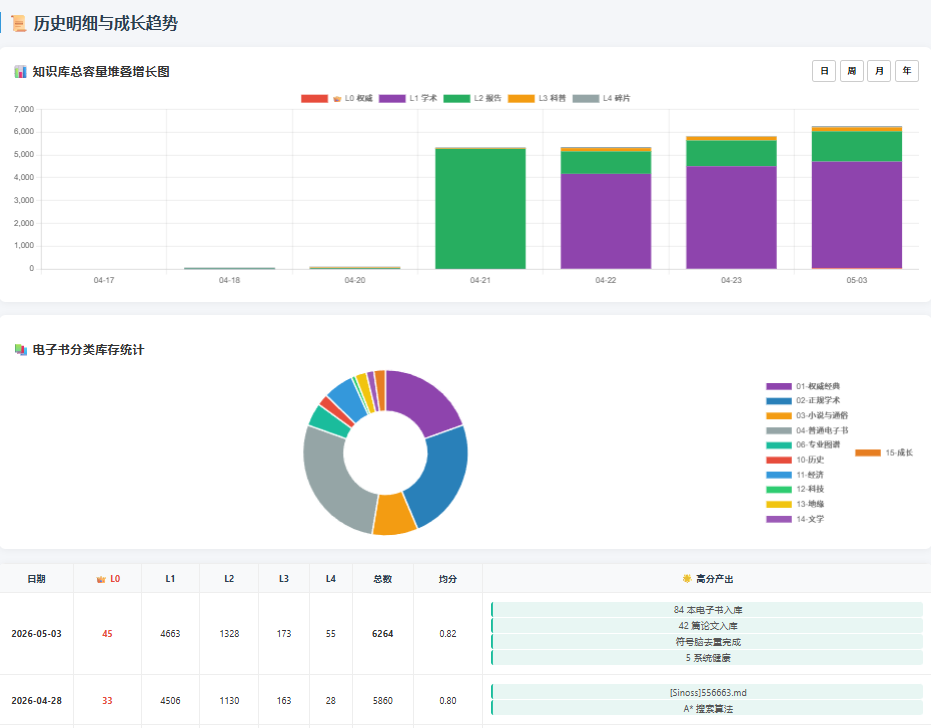

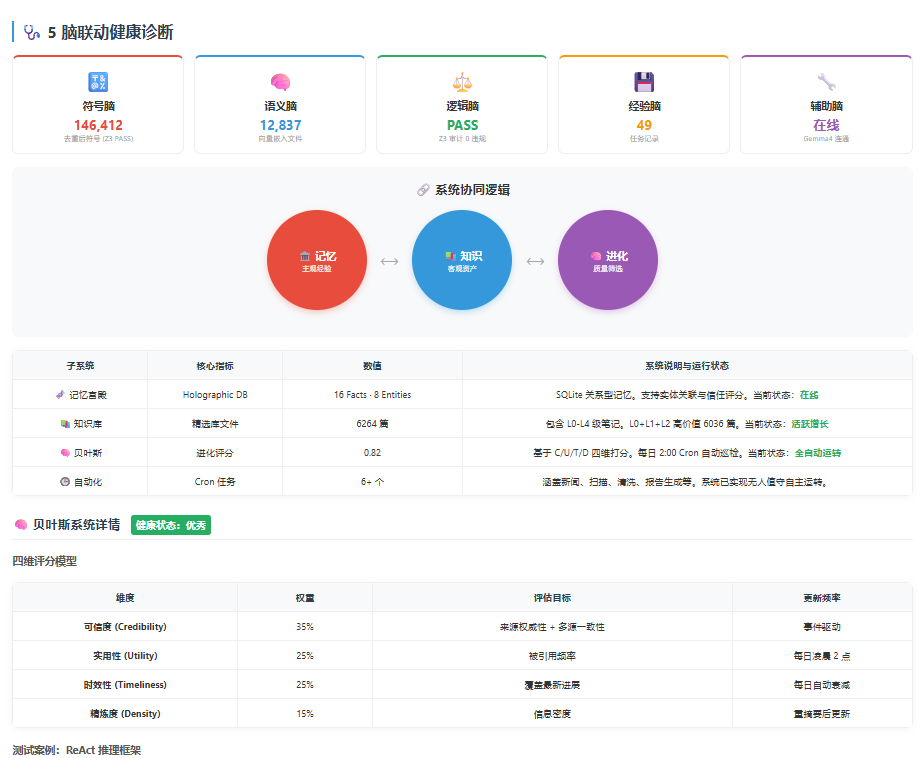
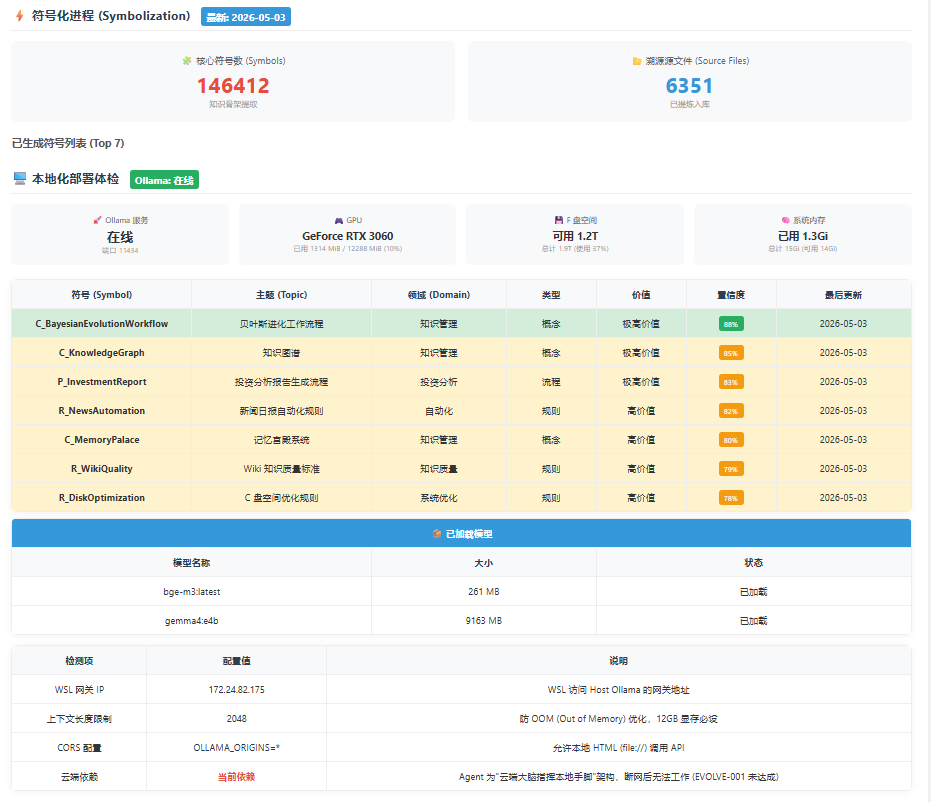
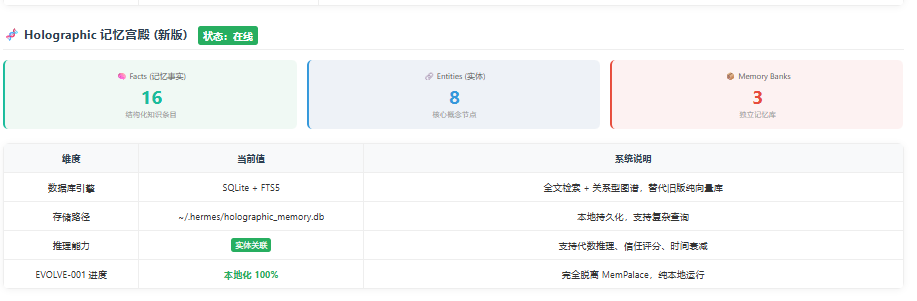
总结一句话:
你只管“输入”和“创造”,我负责“消化”、“提纯”和“记忆”。 你的知识库永远保持高分、干净、结构化。
4、精选库的结构。
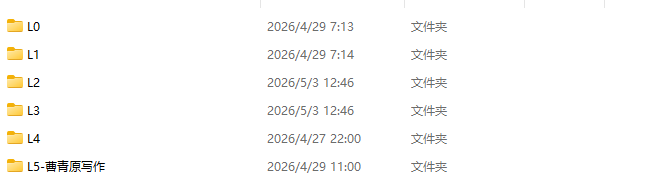
精选库我分我4级,AI读取只选L0-L4的内容。L5S私人的文件。
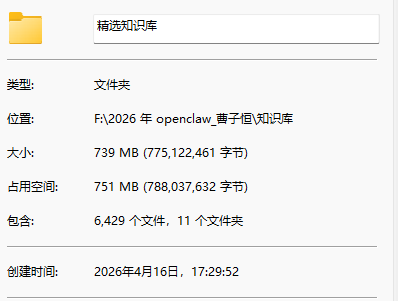
4、精选的内容再喂给记忆库,符号化处理,便于AI搜索和使用。(另外的话题和流程)
二,Obsidian介绍。
Obsidian(黑曜石)是一款本地优先、双向链接驱动、高度可定制的 Markdown 知识管理与笔记工具,主打 “数据主权 + 网状思维 + 可生长知识库”,个人核心功能永久免费。
(一)、核心特点(四大支柱)
1. 本地优先,数据完全私有(File Over App)
全本地存储
:所有笔记以纯文本 Markdown(.md)格式存放在你指定的文件夹(称为 Vault / 保险库),不上传官方服务器,断网照常使用Obsidian。
数据永久归属
:文件开放通用,任何编辑器都能打开,不受软件生命周期限制,无 “厂商锁定” 风险。
隐私绝对可控
:无账号强制、无数据采集、无广告追踪,敏感内容(日记、创意、研究)更安全。
2. 双向链接 + 知识图谱(网状思维核心)
双向链接([[链接]])
:用[[笔记名]]即可互链,自动生成反向链接(Backlinks),清晰显示 “哪些笔记引用了我”,打破传统文件夹的线性限制。
知识图谱可视化(Graph View)
:将所有笔记与链接绘制成交互式网络图,直观呈现思维关联、发现隐藏联系、构建个人维基。
无缝跳转与回溯
:点击链接快速跳转,支持返回历史,阅读体验流畅。
3. 插件生态极强,按需定制(乐高式工具)
核心插件免费
:官方内置搜索、标签、大纲、版本历史、发布等基础能力。
社区插件海量(2000+)
:一键扩展为写作、任务管理、数据库、白板、思维导图、AI 搜索、看板、日历、LaTeX 公式等专业工具。
典型插件
主题与样式
:支持自定义 CSS 片段与社区主题,界面完全个性化。
4. 极简高效,全平台覆盖
极速响应
:本地文件读写,启动 / 搜索 / 秒开,大库(万级笔记)依然流畅。
Markdown 全能
:实时预览、语法高亮、图片 / 附件直接拖放、支持 LaTeX / 数学公式、脚注、表格、代码块。
全平台支持
:Windows/macOS/Linux 桌面 + iOS/Android 移动端原生应用,非网页套壳,体验一致。
灵活同步方案
:官方端到端加密同步(付费);或用 iCloud/Dropbox/OneDrive/ 坚果云 / Git 免费自建同步。
(二)、核心优势(对比传统云笔记)
数据安全与隐私
:本地存储 + 开放格式,无云端泄露 / 丢失风险,隐私可控。
思维方式革命
:双向链接 + 图谱,贴合人类网状思考,适合学术研究、创作、知识沉淀、卡片盒笔记法(Zettelkasten)。
高度自由无束缚
:无强制文件夹结构、无格式限制、无功能冗余,极简者够用,进阶者可深度定制。
长期价值保值
:Markdown 永久通用,笔记可终身复用,工具迁移成本极低。
免费核心,成本友好
:个人使用永久免费,仅高级同步 / 发布付费,社区方案可替代。
(三)、适合人群
知识工作者、研究者、学生(文献管理、笔记关联);
创作者、作家、设计师(灵感组织、结构梳理);
项目管理者、产品经理(任务看板、知识库);
重视隐私、追求数据主权、喜欢自定义工具的用户。

三、HERMES+Obsidiang的联动方式。
Obsidian我一开始是单独使用,目前希望联动,提高效率。
Obsidian 的底层就是 Markdown,而我们的精选库(L0-L4)也是纯 Markdown。所以它们不需要复杂的 API,天然就是连通的。目前我使用2个方案。
方案一:让 AI 自动“吃”掉 Obsidian 的笔记(推荐 👍)
如果你习惯在 Obsidian 里写笔记(比如写日记、L5 写作),你可以告诉我你的 Obsidian 仓库路径 (Vault Path)(例如 D:\MyObsidian)。
联动原理:我会把该路径加入系统的 Cron 定时扫描任务。
工作流:你在 Obsidian 写完并保存 -> 系统后台自动扫描该文件夹 -> 贝叶斯打分 -> 自动搬运并分类到精选库 L0-L4。
结果:你只管写,我负责入库和五脑喂食,实现真正的“无感联动”。
方案二:把 Obsidian 当作“精选库”的浏览器
如果你只是想看我在精选库里整理好的知识:
联动原理:直接在 Obsidian 软件中选择 “打开文件夹” -> 选择 F:\2026 年 XXX\知识库\精选知识库。
效果:
你能直接在 Obsidian 里看到所有分级文档(L0-L4)。
你能看到我给每篇文章加的 YAML 头(贝叶斯打分、来源、日期)。
你可以利用 Obsidian 的双链功能,把我和你的笔记连起来。
这些都让hermes,自己去做。
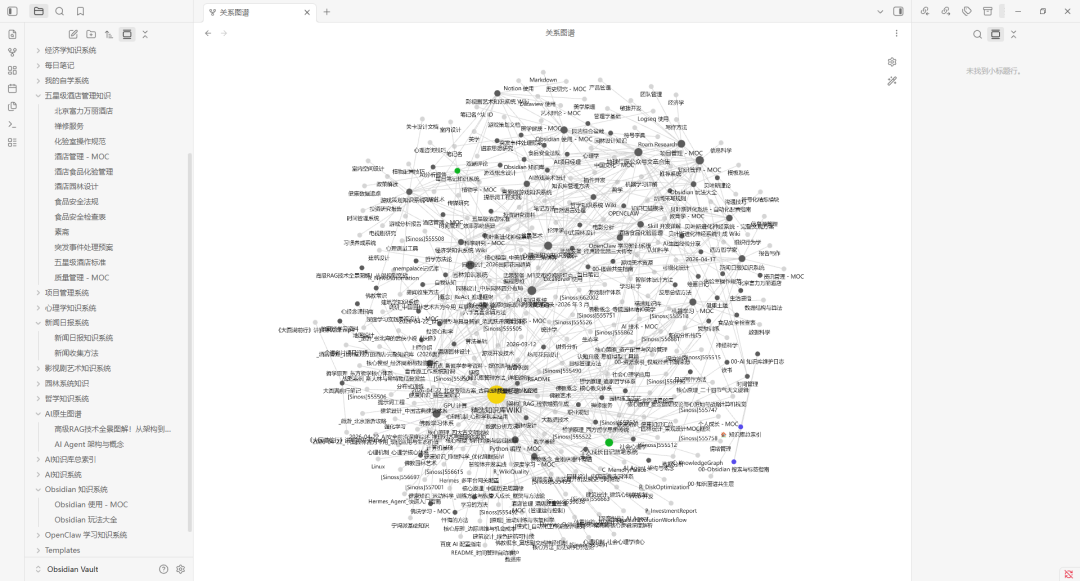
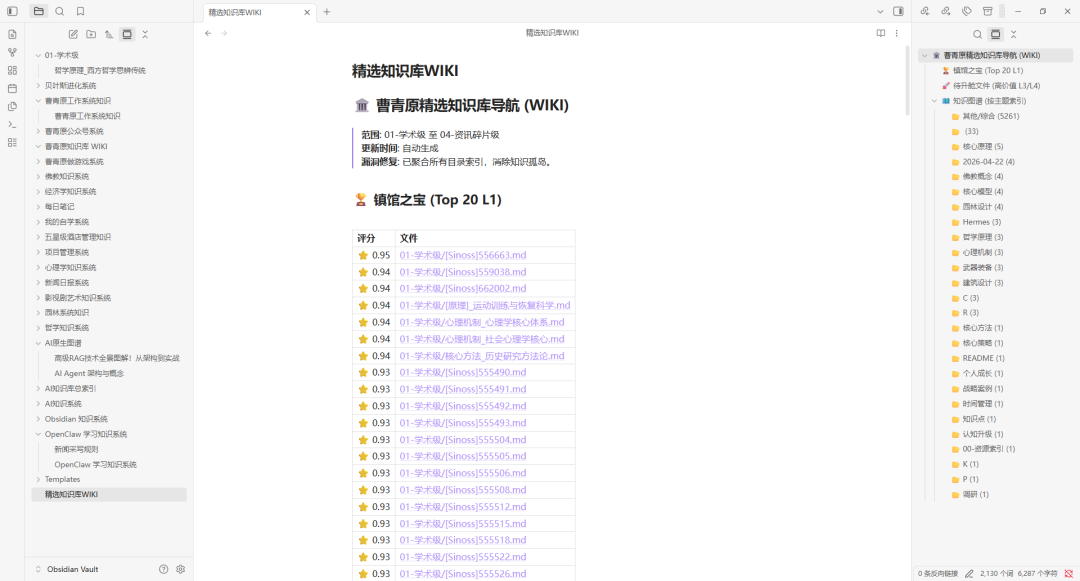
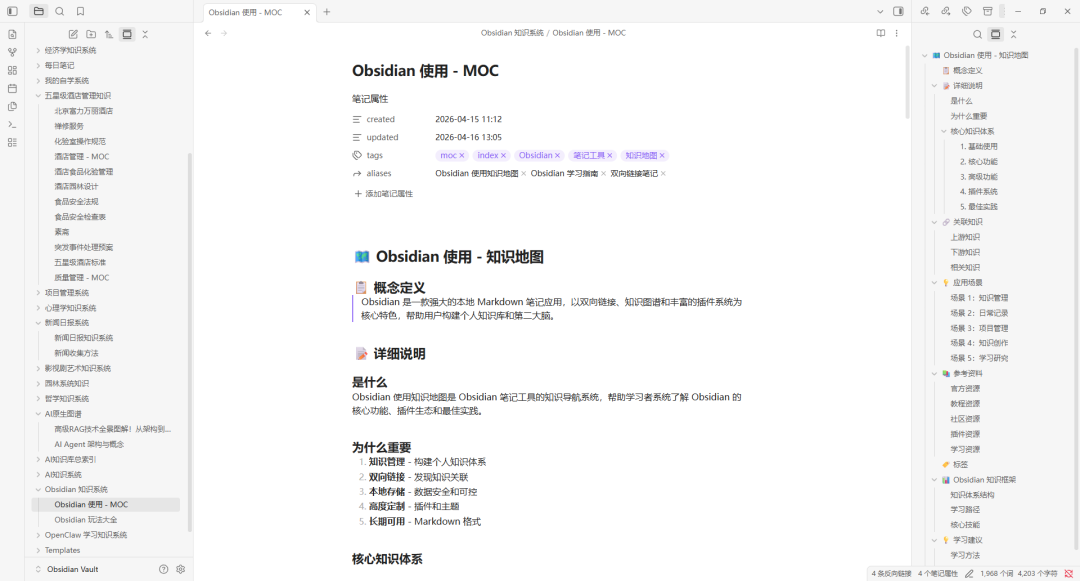
最后,知识库建立好以后,你就可以写文章,计算,按自己的思路去创作,会用比积累一个库要有意义。
四、Obsidian 还能做什么?
在 HERMES 体系中,Obsidian 绝不是被动的“阅读器”,而是你的“人类创作与输出中枢”。HERMES 负责“挖矿、清洗、打分、入库”,而 Obsidian 负责“组装、关联、起草、交付”。
针对你提到的三大场景,Obsidian 可以发挥以下具体作用:
📑 1. 出报告 / 写论文:结构化起草 + 溯源 + 引用管理
HERMES 做:从海量 PDF/网页中提取文本,贝叶斯打分,按 L0-L4 分级,存入精选库。
Obsidian 做:
模板化起草:使用 Templater 插件一键生成《行业分析报告》《学术论文》标准框架(摘要、引言、文献综述、方法论、结论)。
双向链接溯源:在写“文献综述”时,直接 [[ ]] 引用 HERMES 入库的 L1/L2 级 MD 文件。点击即可跳转原文,修改自动同步,彻底告别“找不到出处”。
引用与导出:配合 Zotero Integration + Pandoc 插件,自动抓取论文 DOI/引用格式。写完后可一键导出为 .docx 或 .pdf,保留学术排版。
📊 2. 出报表分析:动态查询 + 数据看板 + 分析笔记
HERMES 做:抓取原始数据,清洗为结构化 MD,附加 YAML 头(日期、分数、标签、来源)。
Obsidian 做:
Dataview 动态报表:无需写代码,用类似 SQL 的语法实时生成表格。例如:
dataview
TABLE level, bayesian_score, source
FROM “精选知识库”
WHERE level = “L2” AND date >= “2026-05-01”
SORT bayesian_score DESC
每次 HERMES 入库新内容,打开 Obsidian,表格自动刷新,直接截图即可当报表用。
Canvas 逻辑画布:用可视化画布拖拽 HERMES 入库的笔记、数据片段、你的分析结论,连线推导业务逻辑,适合做“战略分析”“竞品对标”等非结构化思考。
Mermaid 图表嵌入:在笔记里直接写代码生成流程图、时序图、甘特图,配合 HERMES 提供的数据点,快速输出可视化分析页。
🔍 3. 深度研究 / 知识沉淀:图谱发现 + 版本迭代
HERMES 做:五脑联动(符号脑提取逻辑链,语义建向量索引,经验脑记录历史任务)。
Obsidian 做:
全局知识图谱:打开 Graph View,能看到 HERMES 入库的 6000+ 篇文档与你个人笔记的关联网络。常能发现“意想不到的跨学科连接”,直接催生新论文选题。
草稿版本管理:配合 Git 插件,每次重大修改自动 commit。写报告/论文时不怕改乱,可随时回滚到任意历史版本。
L5 写作专属空间:你的个人灵感、未成熟观点、写作草稿全放在 L5-XXX写作。HERMES 不干涉,但你可以在写作时随时 @ 引用精选库的 L0-L2 权威素材,实现“人机素材无缝混编”。
🛠️ 推荐 Obsidian 插件清单(配合 HERMES 使用)
| 插件 | 核心作用 | 联动 HERMES 的方式 |
|:—|:—|:—|
| Dataview | 动态查询、自动报表 | 直接读取 HERMES 生成的 YAML 元数据(分数、级别、日期)生成表格 |
| Templater | 模板引擎、自动化插入 | 一键调用 HERMES 入库的高分文献作为报告素材占位符 |
| Excalidraw | 手绘图表、逻辑推演 | 将 HERMES 提取的符号脑逻辑链可视化,辅助写论文/报告结构 |
| Zotero Integration | 学术引用管理 | 与 HERMES 的 L0/L1 论文库对接,自动插入参考文献 |
| Git | 本地版本控制 | 保护你基于 HERMES 素材撰写的报告/论文草稿,防丢失 |
💡 一句话总结分工
HERMES 负责 Input → Process → Store(读、算、存)
Obsidian 负责 Query → Link → Draft → Output(查、连、写、发)
你下次需要出报告或写论文时,只需在 Obsidian 里建一个新笔记,告诉我:“用 L2 级材料帮我搭一份 XX 报告框架”,我会把 HERMES 精选库里的对应 MD 链接、数据摘要、引用建议直接推送到你的 Obsidian 画布里,你只管定稿和润色。
只需要你在 Obsidian 这一端做一点“准备工作”,就能让我推给你的素材发挥最大威力。
以下是你需要做的 3 个轻量级配置,做完后我们的配合就像“变形金刚”一样顺畅:
1. 挂载知识库(你只需点一次)
打开 Obsidian -> 点击左上角 打开其他文件夹 (Open folder as vault) -> 选择 F:\2026 年XXX\知识库\Obsidian 知识库。
- 效果:你以后在这里写的任何笔记,我都能通过“同步”指令自动抓取并入库;我入库的内容,也能被你直接引用。
2. 安装三个神器插件(社区插件)
在 Obsidian 的 设置 -> 第三方插件 中搜索并开启以下三个(这是让 Obsidian 变身的核心):
Dataview(必装 ⭐):
作用:让你能用类似 Excel 的逻辑,自动把 HERMES 入库的文件变成动态报表。
不用写代码,到时候我直接发给你一段代码,你复制进去,表格就出来了。*
Templater:
作用:一键生成标准报告框架。
我会为你准备好“报告模板”和“论文模板”,你一键插入,格式自动对齐。*
Excalidraw(选装,画图表用):
作用:在笔记里画图、画逻辑图。
3. 接收我发给你的“工具包”
等你装好插件,告诉我 “配置好了”。我会立即为你生成以下文件并放入你的库中:
📄 《万能报告生成器模板》(包含 Dataview 自动抓取 L2 级高分素材的代码块)
📄 《论文文献综述模板》(包含自动统计 L1 级论文数量的看板)
📄 《Obsidian 常用指令集》(教你怎么用一句话让我干活)
我写这篇文章主要是,使用后感觉比用 IMA那个笔记工具 更适合我,很多朋友在老帖子下留言,我希望大家也能体验一下HERMES+Obsidiang,管理自己的知识库的方案。
AI技术发展特别快,多尝试新工具,才能提高效率,我一开始是OPENCLAW+Obsidian,但是现在不用龙虾了,HERMES更好用。
最后,有问题欢迎大家交流。
💬 本文评论区已开启,但暂无读者留言。
本文转载自微信公众号,如有侵权请联系删除。
- 标题: HERMES+Obsidian,管理自己的知识库。
- 作者: lxiol
- 创建于 : 2026-05-06 20:00:16
- 更新于 : 2026-05-12 16:07:03
- 链接: https://blog.lxiol.cn/2026/05/06/HERMESObsidian管理自己的知识库/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。