Mac跑MiniMax-M2.7,2条路径对比
今天聊一个很多 Mac 用户关心的问题:MiniMax-M2.7 怎么在 Mac 上跑起来?
MiniMax-M2.7 是什么来头?
先简单回顾一下
M2.7 是 MiniMax 最新的开源大模型,MoE 架构,总参数 228.7B,每 token 激活约 10B 参数,192K 上下文
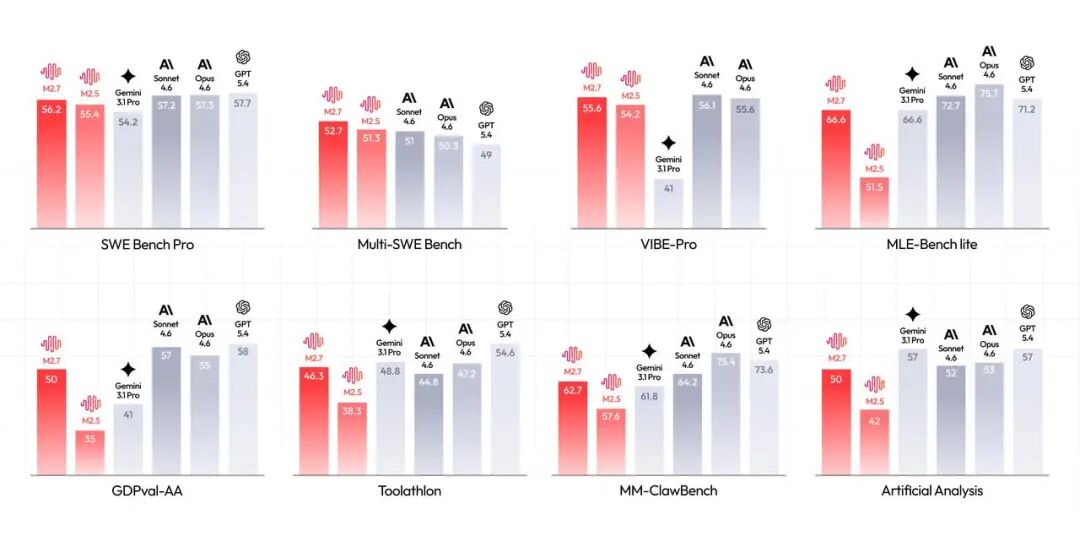
这货最亮眼的几个数据:
- SWE-Pro 56.22%,和 GPT-5.3-Codex 打平
- MLE Bench Lite 66.6% 奖牌率,仅次于 Opus-4.6 和 GPT-5.4
- 原生支持 Agent Teams,多智能体协作
- Always-reasoning 模式,始终开启思考链
问题是——228B 参数,普通人怎么跑?答案是量化。但 MiniMax 的量化比一般模型坑多得多
为什么标准量化在 MiniMax 上翻车?
这是写这篇文章最想说的一件事:标准 MLX 均匀量化在 MiniMax-M2.7 上完全失效——MMLU 直接降到 ~25%,基本等于随机猜
原因在于 MoE 架构的路由器(Router Gate)
均匀量化连路由器一起压了,导致 token 被分配到错误的专家上,整个模型就废了
所以 Mac 用户想跑 M2.7,目前只有两条靠谱的路
路径一:JANGTQ + MLX Studio(推荐!)
JANGTQ(JANG TurboQuant)是目前最小体积、最高质量的 M2.7 Apple Silicon 量化方案,来自 JANGQ-AI 团队
核心思路:混合精度量化。路由专家 MLP(占 98% 参数)用 2-bit codebook + Hadamard 旋转压缩,而 Attention、共享专家、Router Gate 保持 8-bit 或 fp16。
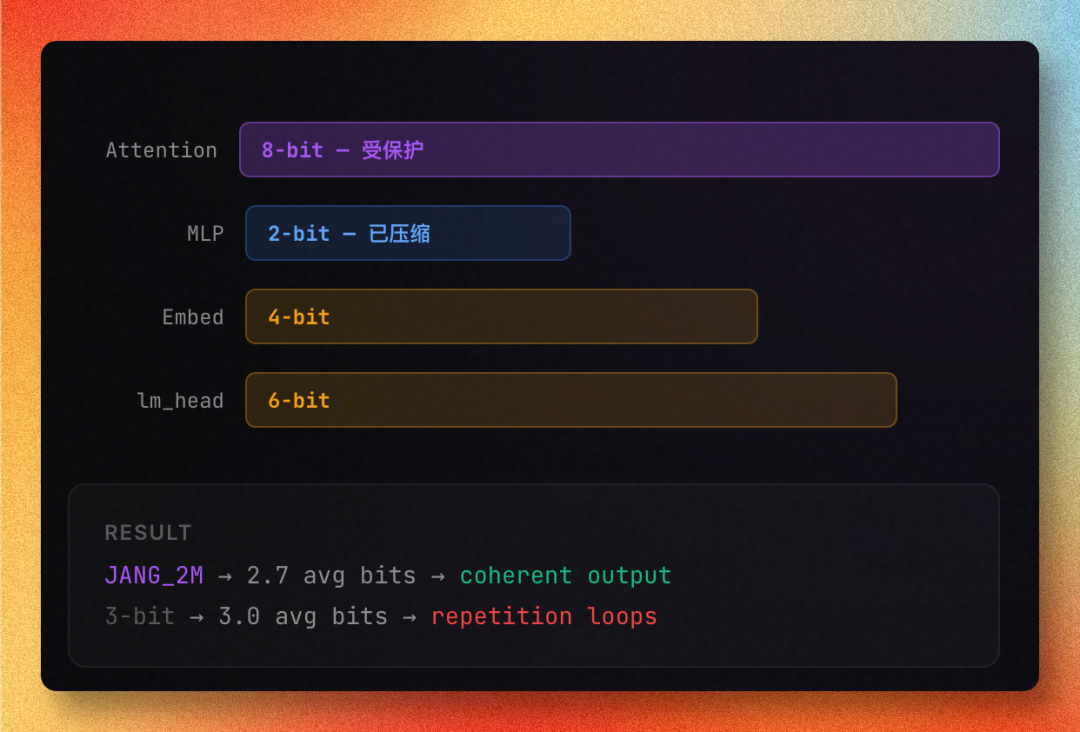
硬核数据:
指标
数值
磁盘占用
56.5 GB
GPU 显存
56.5 GB
MMLU(200题)
91.5%
速度(M3 Ultra)
~44 tok/s
你没看错——2-bit 量化,只要 56.5GB,MMLU 居然能打到 91.5%。对比标准 MLX 量化的 ~25%,这差距简直是天壤之别
怎么跑:
最简单的方式是用 MLX Studio(内置了 JANGTQ 运行时和 Metal 内核):
命令行方式也行:
1 | `pip install jang-tools` |
1 | `from huggingface_hub import snapshot_download |
硬件要求:
机器
最低内存
预期速度
M3 Ultra / M2 Ultra
96 GB
~44 tok/s
M4 Max
96 GB
~35-40 tok/s
M4 Pro
64 GB
~25-30 tok/s(非常紧张)
64GB 的 M4 Pro 理论上能跑,但会很紧张
96GB 是比较舒服的起点
路径二:LM Studio + GGUF(最省心)
如果你就想点几下鼠标就开跑,LM Studio 是最简单的选择。
LM Studio 已经上线了 MiniMax-M2.7 的 GGUF 版本,基于 llama.cpp b8778 量化。
使用步骤:
- 下载安装 LM Studio:https://lmstudio.ai/download
- 搜索
minimax/minimax-m2.7 - 选择量化版本下载
- 设置参数:Temperature=1.0(必须!)、Top K=40、Top P=0.95
- 开始对话
GGUF 来源是 lmstudio-community/MiniMax-M2.7-GGUF。如果追求更好的量化质量,Unsloth 提供了 22 个 Dynamic 2.0 量化版本,逐层差异化量化,质量全面优于标准 imatrix。
但有个大问题:LM Studio 官方标注最低系统内存 138GB
两条路径,怎么选?
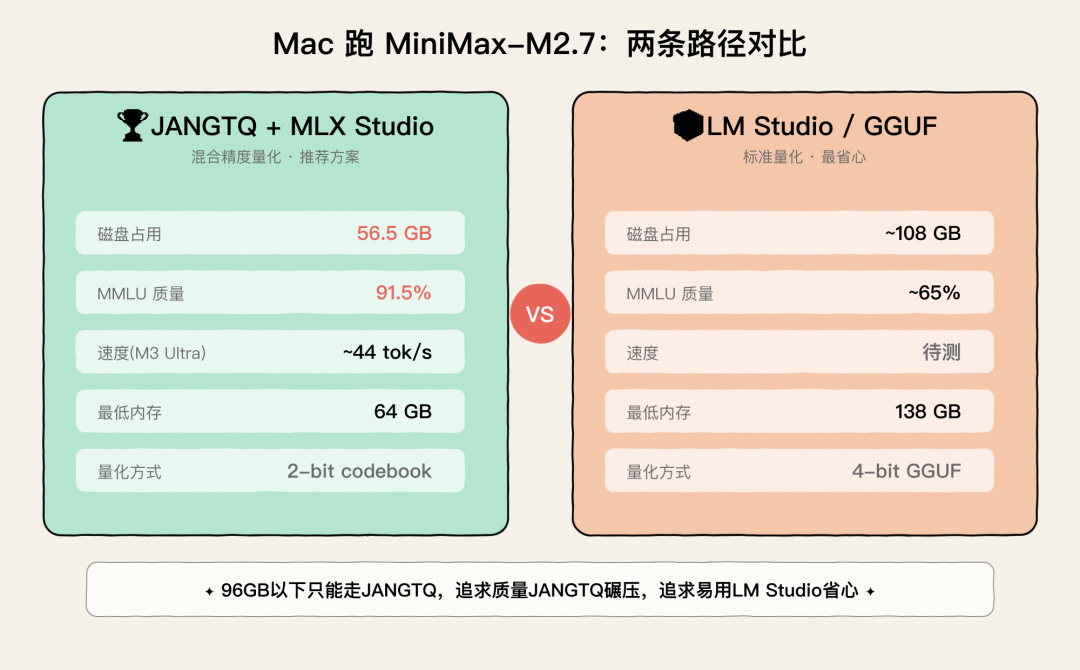
两条路径对比
维度
JANGTQ + MLX Studio
LM Studio / GGUF
最小磁盘
56.5 GB
✅
~108 GB
最低内存
64 GB
✅
138 GB
MMLU 质量
91.5%
✅
~64-65%(4-bit)
速度(M3 Ultra)
~44 tok/s
待测
易用性
需安装 jang-tools
开箱即用
✅
生态兼容
MLX 生态
OpenAI 兼容 API
✅
我的建议:
- 96GB 以下的 Mac → 只能走 JANGTQ,别无选择
- 128GB+ 且需要 OpenAI 兼容 API → LM Studio / GGUF 更方便
- 追求最佳质量 → JANGTQ 碾压,2-bit 打 4-bit,这个结果说实话我也很意外
⚠️ 关键设置提醒
不管走哪条路,这几个参数必须注意:
- Temperature 必须设 1.0 —— temp=0 会导致思考链死循环,模型会一直
<think>下去停不了 - max_tokens ≥ 8192 —— Always-reasoning 模型的思考过程需要足够空间
- 内存必须大于模型文件大小 —— 否则回退到硬盘卸载,速度断崖式下降
总结
MiniMax-M2.7 在 Mac 上的本地部署,JANGTQ 是目前当之无愧的最优解——体积最小、质量最高。2-bit 量化能拿到 91.5% MMLU,这在我写过的所有量化方案里都算炸裂级别的。
LM Studio 胜在省心和生态兼容,但内存门槛太高。
如果你手上有一台 96GB+ 的 Mac,强烈建议先试试 JANGTQ
56.5GB 下载完就能跑,44 tok/s 的速度日常使用完全够了。
#MiniMax #M2.7 #Mac本地部署 #JANGTQ #量化
制作不易,如果这篇文章觉得对你有用,可否点个关注。给我个三连击:点赞、转发和在看。若可以再给我加个🌟,谢谢你看我的文章,我们下篇再见!
💬 本文评论区已开启,但暂无读者留言。
本文转载自微信公众号,如有侵权请联系删除。
- 标题: Mac跑MiniMax-M2.7,2条路径对比
- 作者: lxiol
- 创建于 : 2026-05-06 19:47:07
- 更新于 : 2026-05-12 16:07:03
- 链接: https://blog.lxiol.cn/2026/05/06/Mac跑MiniMax-M272条路径对比/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。