Qwen3.6 27B FP8 火了:本地长上下文推理开始进入实用区
Qwen3.6 27B FP8 火了:本地长上下文推理开始进入实用区

Qwen3.6 27B 本地长上下文推理总览
这次不是“能不能跑”,而是“跑得像不像个人”
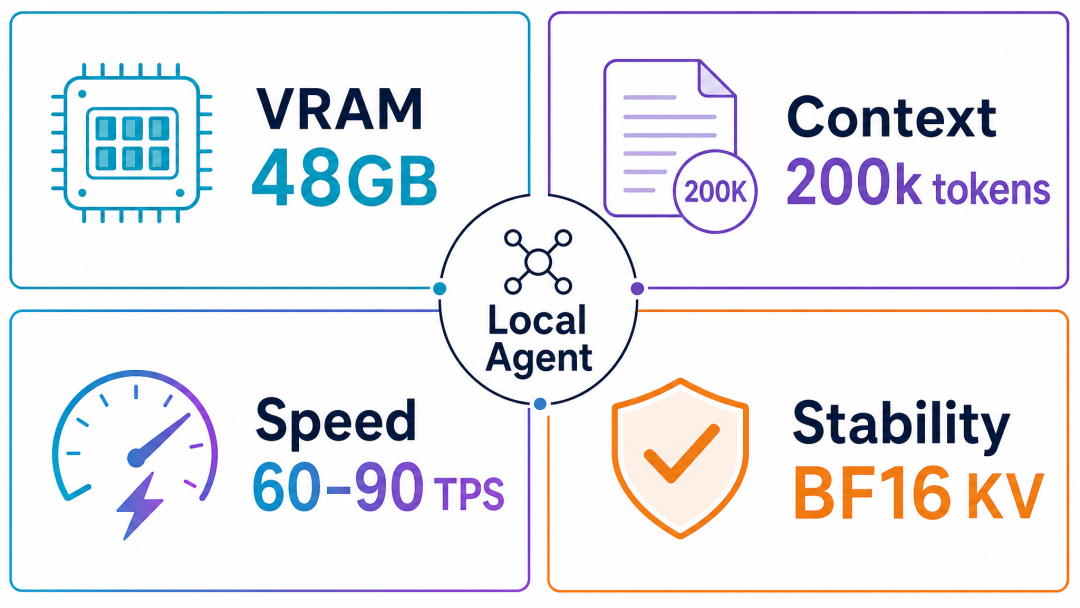
2026 年 5 月 5 日,Reddit 的 r/LocalLLaMA 社区冒出一个挺有意思的帖子:有人用一张 RTX PRO 5000 Blackwell 48GB ,把 Qwen3.6 27B FP8 跑到了 约 200k tokens 的 BF16 KV Cache ,日常写代码时输出速度大概 60-90 TPS 。
如果只看标题,这像是又一个“我有贵显卡,我很快乐”的硬件炫技帖。
但真正值得聊的不是炫卡,而是一个信号:本地大模型的竞争,正在从“塞进显存”转向“长上下文下还能稳定高速干活”。
几个数字先摆桌上
这次 Reddit 原帖给出的核心配置是:
- 模型: Qwen/Qwen3.6-27B-FP8
- 推理框架: vLLM 0.20.1
- CUDA: 12.9
- 显卡:单张 RTX PRO 5000 Blackwell 48GB
- 上下文长度:设置到 196,608 tokens ,也就是接近 200k
- KV Cache:使用 BF16 ,不是 FP8 KV
- 生成速度:写代码场景下约 60-90 TPS
- 并发:原帖提到约 1.09x concurrency
Qwen 官方模型卡也能对上关键背景:Qwen3.6 27B 是 27B dense multimodal model ,原生上下文为 262,144 tokens ,并声称可扩展到 1,010,000 tokens 。官方 FP8 版本采用细粒度 FP8 量化,block size 为 128 ,并表示性能指标接近原始模型。
换句话说,这不是网友随手把一个模型硬魔改到离谱长度,而是踩在 Qwen3.6 本身“长上下文 + FP8 权重 + MTP”这套设计上做的本地推理尝试。
真正的主角:不是 FP8,而是 KV Cache

FP8 权重与 BF16 KV Cache 的显存分工
很多人一听 FP8,第一反应是:哦,模型量化了,所以跑得快。
这只说对了一半。
FP8 权重量化主要解决的是“模型本体怎么塞进显存、矩阵计算怎么吃到硬件加速”。但长上下文场景里,另一个显存大户是 KV Cache 。上下文越长,KV Cache 越像滚雪球:每多读一段历史,都要留下可供后续注意力机制查询的 Key / Value 状态。
所以这次最关键的点,其实是原帖作者没有把 KV Cache 也压到 FP8,而是选择 BF16 KV Cache 。
这意味着它想保留更高精度的上下文记忆,尤其是面向“agentic coding”这种容易被上下文污染、循环输出、旧信息干扰的场景。
原帖作者也提到,他试过 --kv-cache-dtype fp8,但在简单测试中曾遇到生成约 10k tokens 后重复输出同一 token、陷入循环的问题。这个反馈不能当成严谨论文结论,但很适合作为内容里的真实社区观察:KV Cache 量化并不是免费午餐。
为什么本地 AI 玩家会兴奋?
过去一年,本地大模型社区经常讨论的是:“ 24GB 显存 怎么跑 27B?”
答案通常是各种量化:Q4、Q5、Q8、GGUF、KV Cache 也一起压。这个路线很实用,也很有黑客精神,但代价是:你很难同时要“长上下文、稳定输出、高速度、低损耗”。
这次 Reddit 原帖的吸引力就在这里:它把问题换了个解法。
不是继续问“怎么把 27B 挤进 24GB”,而是问:“如果我用一张 48GB 专业卡 ,能不能把 27B 跑成一个足够舒服的本地开发助手?”
原帖作者的判断很直接:一台主机、一张 RTX PRO 5000 Blackwell、 64GB RAM 、普通 CPU / 主板,就可能构成一个“桌边小型推理站”。安静、功耗相对可控,不用多卡 3090 那种热风呼呼、线缆横飞的 DIY 战场。
这个叙事很适合公众号:本地 AI 不再只是极客玩具,它开始靠近“可长期使用的生产力设备”。
但别急着喊革命
本地长上下文推理的四个约束
这条帖子热度高,但我们写的时候要克制,不能把它包装成“人人都能拥有本地 Claude”。
第一, RTX PRO 5000 Blackwell 48GB 不是便宜玩具。评论区有人开玩笑说“现在只差找到 1 万美元了”。虽然实际单卡价格不一定到 1 万美元,但整机方案对普通玩家依然不低。
第二, 60-90 TPS 是原帖作者在“写代码”场景下的体感和初步结果,原帖也明确说“real benchmark numbers to follow”。也就是说,严谨 benchmark 还没完全补齐。
第三,vLLM 参数堆得不少:FlashInfer、MTP speculative config、CUDA Graph、prefix caching、async scheduling……这不是“下载模型,点一下就起飞”。它更像是熟手玩家调出来的一套菜谱。
第四,社区里也有人质疑原帖格式像 AI 生成,甚至怀疑帖子本身“bot 味”比较重。这不必当成定论,但作为内容风险要提一嘴:我们引用它时,应该写成“社区案例”和“趋势信号”,而不是“已被权威验证的性能结论”。
Qwen3.6 27B 为什么适合这个故事?
Qwen3.6 27B 本身也有话题性。
官方定位里,它不是一个巨无霸 MoE,而是一个 27B dense 模型,重点打“agentic coding”。官方资料显示,它支持视觉 + 文本输入,采用混合架构,包含 Gated DeltaNet、Gated Attention,并训练了 MTP,也就是 multi-token prediction 相关能力。
更重要的是,Qwen3.6 27B 官方就强调长上下文:原生 262k tokens ,可扩展到 1010k tokens 。vLLM recipe 里也写到,FP8 版本可在单张 40GB GPU 级别硬件上服务 262k 上下文;INT4 则可下探到单张 24GB GPU 。
所以这次 Reddit 案例之所以成立,不只是因为显卡强,而是模型、框架、硬件三件事刚好接上了:
- 模型端:Qwen3.6 27B 原生长上下文,并有官方 FP8 权重
- 框架端:vLLM 对 Qwen3.6、FP8、MTP、长上下文服务有 recipe 支持
- 硬件端:Blackwell 专业卡提供更适合 FP8 / 新精度计算的土壤
这就是它值得写的地方:不是单点炫技,而是“本地推理栈”开始整体成熟。
这一仗,争的其实是本地 Agent 的记忆力
如果只是普通聊天,几十 k 上下文已经够用。
但如果你把大模型当 coding agent,让它读仓库、改文件、记住历史讨论、持续 debug,那上下文很快就会变成刚需。
短上下文像短期记忆强的人:临场反应快,但很容易忘前面说过什么。长上下文像项目老员工:未必每句话都惊艳,但知道这个坑昨天已经踩过。
所以“200k tokens + BF16 KV Cache + 80 TPS”这组数字背后,真正的内容角度不是跑分,而是本地 Agent 的体验门槛正在变化:
以前大家关心的是“能不能跑起来”;
现在开始关心“能不能长时间、不失忆、不抽风地跑下去”。
这对开发者、自媒体创作者、隐私敏感团队都有意义。尤其是代码、文档、企业知识库这些场景,本地长上下文推理天然有吸引力。
可以怎么判断这件事?
我的判断是:这不是大众消费级 AI PC 的胜利,但它是本地工作站 AI 的一个清晰信号。
如果你只有一张 24GB 消费卡,量化路线仍然非常现实;如果你愿意投入一台接近专业工作站的机器,那么 27B dense + FP8 weights + BF16 KV + 200k context 这种组合,开始具备“认真干活”的样子。
它不会立刻替代云端 Claude、GPT 或 Gemini,但会让一部分开发者重新思考:
当本地模型不仅能跑,还能带着长记忆高速跑,我们到底还需要把多少工作流交给云端?
这大概就是这条 Reddit 帖子真正值得写的地方。
原始链接与参考资料
- Reddit 原帖: https://www.reddit.com/r/LocalLLaMA/comments/1t46klu/qwen36_27b_fp8_runs_with_200k_tokens_of_bf16_kv/
- Qwen3.6 27B 官方博客: https://qwen.ai/blog?id=qwen3.6-27b
- Qwen3.6 27B FP8 Hugging Face: https://huggingface.co/Qwen/Qwen3.6-27B-FP8
- vLLM Qwen3.6 recipe: https://recipes.vllm.ai/Qwen/Qwen3.6-27B
- NVIDIA Developer Forum 相关讨论: https://forums.developer.nvidia.com/t/whats-the-best-speed-we-can-get-with-qwen-3-6-27b-without-quantizing/367561
💬 本文评论区已开启,但暂无读者留言。
本文转载自微信公众号,如有侵权请联系删除。
- 标题: Qwen3.6 27B FP8 火了:本地长上下文推理开始进入实用区
- 作者: lxiol
- 创建于 : 2026-05-06 19:55:15
- 更新于 : 2026-05-12 16:07:04
- 链接: https://blog.lxiol.cn/2026/05/06/Qwen36-27B-FP8-火了本地长上下文推理开始进入实用区/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。