一个 `.claude` 文件夹凭啥两个月冲到 55k stars?
故事是这么开始的2026 年 2 月初,一个叫 Matt Pocock 的英国开发者在 GitHub 上建了个

故事是这么开始的
2026 年 2 月初,一个叫 Matt Pocock 的英国开发者在 GitHub 上建了个仓库,名字很朴素,就叫 skills。简介更朴素,一句话: “Skills for Real Engineers. Straight from my .claude directory.”(给真工程师用的技能。直接来自我的 .claude 文件夹。)
翻译过来就是:哥们我就是把自己电脑里给 Claude Code 用的配置文件夹打包扔上来了,没干别的。
结果到了 4 月底,这个仓库冲到了 45,289 stars ;又过了几天,数字滚到 55.1k stars , 4.6k forks , 463 万点开看过的眼球。一个号称”没干别的”的项目,就这么把”AI 辅助编程怎么不变成灾难”这件事,给捅到了开源社区的中央。
它到底解决了啥?
Matt 在 README 里直接点名了 AI 编程的 四大失败模式 :
- 代理没做你想要的(需求对不齐)
- 代理啰里啰嗦(吐 token 像不要钱)
- 代码跑不起来(看着挺像那么回事)
- 越改越像泥球(俗称 ball of mud ,想象一下你家厨房三个月没收拾)
业界现在很火的玩法叫 vibe coding ——意思是你跟 AI 说”嗨,搞个登录页”,看着它输出代码,感觉对了就提交。听起来很潇洒,但 Matt 觉得这玩意儿就像吃饭不洗手,迟早要拉肚子。他给出的药方叫 Real Engineering(真工程) :用一系列结构化的”技能”(Skills),把工程师重新拉回掌控位。
一行命令装上
1 | `npx skills@latest add mattpocock/skills` |
跑完之后再来一句 /setup-matt-pocock-skills ,它会问你:你们用 GitHub 还是 Linear?triage 标签叫啥?文档放哪?回答完,全套技能就在你电脑里待命了。
先认识”四大核心档案”
工程类技能不是孤零零跑的,背后靠四类文档撑着,用来”喂”给 AI:
档案
通俗解释
例子
CLAUDE.md
给 Claude 看的”员工手册”,告诉它项目怎么工作
“我们用 GitHub Issues,bug 标签叫 needs-triage”
CONTEXT.md
项目的”字典”,定义领域术语,避免词义打架
“订单 = Order,不是 Bill”
docs/adr/
“重大决策档案”,记录当初为啥选 A 不选 B
“为什么用 PostgreSQL:因为我们要 JSON 列”
.out-of-scope/
“拒绝理由档案”,记录哪些需求被明确拒绝过
“不支持微信支付:目标用户只有支付宝”
其中 ADR(架构决策记录)有个有意思的”克制原则”——只有同时满足 3 个条件 才写:难以逆转、缺了上下文会让人困惑、真实权衡过的结果。Matt 不希望它沦为日记本。
12 个技能,全收下
仓库目前对外暴露 12 个技能 ,可以分成五大类。下面挨个过一遍,常用的多说几句,简单的一笔带过。
一、对齐需求:让 AI 别乱跑(4 个)
1. /grill-me — 让 AI 反过来烤你
这个名字直译叫”烤我”,意思是—— 关掉 AI 写代码的能力,打开它的提问能力 。
平时你说”做个购物车”,AI 大概率刷刷就开干了。但 Matt 的逻辑是:99% 的项目翻车不是 AI 笨,是你自己没想清楚。所以 /grill-me 这把火直接架你身上烤,一个问题一个问题问到你怀疑人生:
“购物车要不要支持游客模式?” “如果用户在 A 设备加车、B 设备登录,要合并吗?” “优惠券和限时折扣同时存在,谁优先?”
每个问题它还自己先给个推荐答案,你只需要点头或者反对。整个过程下来,你嘴巴说的不是”我要做购物车”,而是”我要做一个 支持游客模式、跨端合并、券后价优先 的购物车”。

2. /grill-with-docs — 边烤边写字典
/grill-me 的进化版。区别在于: 它会一边追问,一边把答案沉淀到 CONTEXT.md 和 ADR 里 。
比如你嘴里同时蹦出”账户”和”用户”两个词,它会立刻打断你:”等下,这俩到底是不是一个东西?”——确认之后立刻写进字典。下次再聊到,AI 直接复用,不会再问第二遍。这就是 Matt 反复强调的 shared language(共享语言) ,是从领域驱动设计(DDD)那边搬过来的。
3. /to-prd — 一键生成 PRD
聊完需求, /to-prd 把当前对话直接转成产品需求文档(PRD),扔到 issue tracker 里。最关键的一点: 它不再采访你 ,只综合已经聊过的内容。
PRD 模板很完整:问题陈述、解决方案、用户故事、实现决策、测试决策、不在范围内的部分、其他备注。Matt 还专门强调一条—— 不写具体文件路径或代码片段 ,因为这些会快速过时。
4. /to-issues — 把计划切成”小道菜”
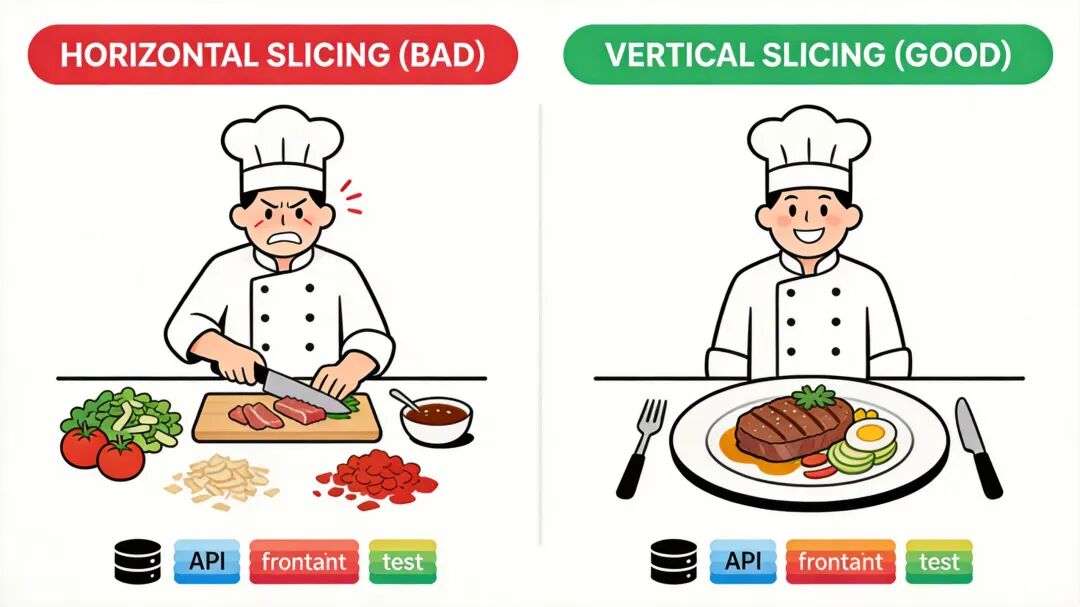
PRD 太大没法干? /to-issues 把它切成一个个独立可领的 GitHub Issue。
切的方式有讲究,叫 垂直切片 。 Matt 用做菜来类比: 水平切片(错) :先切完所有菜、再炒完所有菜、再摆完所有盘——做完之前一口都吃不到; 垂直切片(对) :先完整做一道菜,切+炒+摆盘走一遍,做完先吃上。
代码里也一样—— 每个切片都包含数据库 + API + 前端 + 测试 ,能独立跑通。配套还有一个标记: AFK(Away From Keyboard) = AI 可独立完成; HITL(Human In The Loop) = 必须人工介入。
二、写代码与调试(3 个)
5. /tdd — 红绿重构循环
/tdd 是 Matt 安利得最重的一个,用经典的 红绿重构 三步走:写测试 → 看它失败(红)→ 写最少代码让它通过(绿)→ 重构。
它强调一个铁律: 测试要验证”行为”,而不是”实现细节” 。坏的测试长这样:去 mock(伪造)内部协作者、测试私有方法。Matt 打了个比方—— 就像为了测试厨房好不好,去拆灶台看火苗颜色 。
还有个被他写进流程的小招式叫 Tracer Bullet(示踪弹) :先发一发最简单的测试上去,确认整条链路能跑通——测试框架、调用栈、部署流程,都没问题——再开始正经写。就跟打仗时先发个曳光弹试探距离一样。规则也很硬: RED 状态绝不重构 ,必须先变绿才能动手。
6. /diagnose — 严格调试六步走
调试 Bug 也有标准流程,整整六个阶段,一步不能跳:
阶段
干啥
Phase 1 — 反馈循环
整套技能的核心:搞个”按一下就知道 Bug 在不在”的工具
Phase 2 — 复现
确认 Bug 真的能稳定复现
Phase 3 — 假设
生成 3-5 个可证伪的假设,先给用户看再测
Phase 4 — 验证
一次只改一个变量,所有 debug log 必须打 [DEBUG-xxx] 标记
Phase 5 — 修复 + 回归测试
修完后写”防止再犯”的测试
Phase 6 — 清理 + 复盘
删 [DEBUG-] 日志,思考”什么能预防这个 Bug”
最关键的是 Phase 1 的反馈循环 ——Matt 形容它像”修自行车的打气筒,按一下立刻知道有没有气”。 没有反馈循环,绝不进入假设阶段 。性能回归也一样:先测量(profiler、query plan),再修复,禁止”凭感觉优化”。
7. /zoom-out — 一键拉远镜头
打开一段陌生代码,看不懂为啥这么写? /zoom-out 就像 GPS 的”缩小地图”按钮,拉远视角告诉你:
- 这个模块被谁调用?
- 它又调用了谁?
- 它属于哪个业务上下文?
输出一张关系图,让你瞬间知道自己站在系统的哪个位置。和后面要讲的 /improve-codebase-architecture 不同—— /zoom-out 只 了解 ,不 改进 。
三、维护代码库(2 个)
8. /improve-codebase-architecture — 给代码做体检
这是对抗 ball of mud(泥球) 的杀手锏。Matt 推荐 每隔几天跑一次 。
它的核心目标是发现”浅模块”并把它们改造成”深模块”——
- 深模块(好) :用法很简单,但里面做了很多事。就像自动洗衣机,按一个按钮,洗漂脱全搞定。
- 浅模块(坏) :用法复杂,里面没干啥。就像
validateEmail()却要传 5 个参数,最后只做一个正则判断。
它还提供了一个判断神器,叫 Deletion test(删除测试) :想象删掉这个模块,复杂度是消失了,还是分散到各处?消失了 = 这是个好模块;分散了 = 凉拌。Matt 还特别强调: 一个 adapter = 假想的 seam,两个 adapter = 真实的 seam 。意思是只有一个实现的时候别瞎抽象,等出现两个实现再上接口。
9. /triage — Issue 分拣流水线
Issue 进来太多没人管? /triage 让 AI 当预审员,读 Issue、贴标签、尝试复现、追问信息。
每个 Issue 两类标签:
- Category(类型) :
bug/enhancement - State(状态) :
needs-triage/needs-info/ready-for-agent/ready-for-human/wontfix
最有意思的是 ready-for-agent 这个状态——意思是 这个 Issue 已经准备好让 AI 直接干 ,工程师可以撒手不管。Matt 还规定, 所有 triage 评论必须以一句声明开头 :” This was generated by AI during triage. “ 透明度拉满,避免甩锅。
四、生产力调节(2 个)
10. /caveman — 让 AI 像原始人说话
这个技能的脑洞我特别喜欢。
我们都知道 Claude 这种模型说话特别礼貌:” Sure! I’d be happy to help you with that. The issue you’re experiencing is likely caused by… “ 一句话八个虚词,token 哗哗烧。
/caveman 模式打开之后,画风秒变:
Bug in auth middleware. Token expiry check use
<not<=. Fix:
冠词砍掉,客套话砍掉,连接词砍掉,只留代码、术语、错误原文。Matt 在文档里写明节省约 75% 的 token ,效果立竿见影。
更绝的是它的 持久性 ——一旦触发, 每轮回复都生效 ,直到你说 stop caveman。但又留了几个”自动例外”:遇到安全警告、不可逆操作确认、多步骤序列时,会临时切回正常模式,免得砍得太狠你看不懂出事。聪明又克制。
11. /write-a-skill — 教你造新技能
想自己造一个 skill? /write-a-skill 给你模板和指导。
它强调一个理念叫 Progressive disclosure(渐进披露) :常用功能放 SKILL.md 前面,复杂场景链接到 REFERENCE.md,别一上来就把人砸蒙。还有一条很硬的要求—— description 字段是 AI 选择 skill 的唯一依据 :最多 1024 字符,第三人称,第一句说”做什么”,第二句必须以” Use when [具体触发词]”开头。
五、初始化配置(1 个)
12. /setup-matt-pocock-skills — 一切的开始
工程类技能跑之前必须先跑一次它。它会问你三个问题:
- Issue tracker 用啥? GitHub / GitLab / Local markdown / Other
- Triage 标签怎么映射? 五个标准状态 → issue tracker 实际 label
- Domain docs 怎么布局? 单上下文(一本字典)/ 多上下文(多部字典 + 总目录)
回答完,会自动往 CLAUDE.md 里塞一段 ## Agent skills 配置块。Matt 反复强调 每个仓库跑一次就够了 ——不跑,后面所有工程技能都缺上下文。
推荐启动顺序
Matt 在 README 里给了一个标准工作流,照着用就行:
1 | `1. /setup-matt-pocock-skills # 首次配置 |
注意一个常见陷阱: 跳过 step 1 直接跑后面的工程技能 ,会因为缺少 issue tracker / label 上下文而报错。
同行们怎么看?
这事儿不孤立。Matt 这个仓库火起来的同时,另一个叫 obra/superpowers 的同类项目已经冲到了 174,000 stars 。Anthropic 自己在 2026 年 3 月发的《Agentic Coding Trends Report》里也写了一句:” 重心已经决定性地转向 agentic engineering 。”
社区的反应也分两派。喜欢的人觉得这是把”野生 AI 编程”驯化成”工业流水线”的及时雨;不感冒的人觉得仪式感太重,写个小脚本你也搞 PRD、ADR、grilling,至于吗?
Matt 自己倒是没争辩,他还顺手开了个叫 Claude Code for Real Engineers 的训练营,关联他那个 AI Hero newsletter 一起做。商业归商业,开源归开源,倒也利落。
一些花絮
- 仓库的主语言显示是 Shell 100% ——因为里面装的全是 markdown 和 SKILL.md 配置文件,没啥真代码。
- 仓库还顺便提供了一个
/git-guardrails-claude-code技能,专门拦截 Claude Code 想跑git push --force、git reset --hard、rm -rf这种危险命令,相当于给 AI 装了个”防误删保险”。 - 那句 README 里的引用,来自《务实程序员》经典老书:” Always take small, deliberate steps. The rate of feedback is your speed limit. “(永远小步谨慎前进。反馈速度就是你的速度上限。)二十多年前的话,今天看依然成立。
- 单上下文 vs 多上下文怎么判断?Matt 给了个流程图:项目有多个完全不同的业务领域吗?没有 → 单上下文;有 → 多上下文(monorepo 常见)。
写在最后
mattpocock/skills 这个项目本身的代码量其实不多,55k stars 不是因为它技术多炫,而是因为它替很多人喊了一句: AI 越能干,工程师越得较真。
至于这是不是 AI 编程的未来,有人会觉得这只是把传统软件工程那套”重流程”换了个皮重新塞回来,也有人会觉得这才是 AI 时代真正的”基础设施”。无论站哪边,仓库就在那里,clone 下来花半小时就能体验,剩下的判断交给你自己。
毕竟,工具是给人用的,不是给人膜拜的。
💬 本文评论区已开启,但暂无读者留言。
本文转载自微信公众号,如有侵权请联系删除。
- 标题: 一个 `.claude` 文件夹凭啥两个月冲到 55k stars?
- 作者: lxiol
- 创建于 : 2026-05-06 19:55:58
- 更新于 : 2026-05-12 16:07:04
- 链接: https://blog.lxiol.cn/2026/05/06/一个-claude-文件夹凭啥两个月冲到-55k-stars/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。