阿里提出 SkillRouter:1.2B 小模型解决 8 万技能路由难题
本文提出 SKILLROUTER,一个 1.2B 参数的全文检索—重排路由管线,在约 8 万技能池上取得 74.0% Hit@1,以 13× 更少参数和 5.8× 更低延迟超越 16B 强基线。
📌 一句话总结:
本文提出 SKILLROUTER,一个 1.2B 参数的全文检索—重排路由管线,在约 8 万技能池上取得 74.0% Hit@1,以 13× 更少参数和 5.8× 更低延迟超越 16B 强基线。
🔍 背景问题:
随着 LLM 智能体技能生态规模膨胀至数万条,技能路由成为下游规划执行的关键瓶颈:
1️⃣ 现有智能体框架默认只暴露技能的 name 和 description,假设元数据足以选对技能,但该假设从未在真实规模下被检验;
2️⃣ 已有基准如 SkillsBench、ToolBench、MetaTool 主要评测下游工具使用,未覆盖大池上游路由在隐藏实现体下的表现;
3️⃣ 社区技能库存在严重重叠,同名或近似功能的技能相互混淆,使得纯语义检索难以区分细粒度差异。
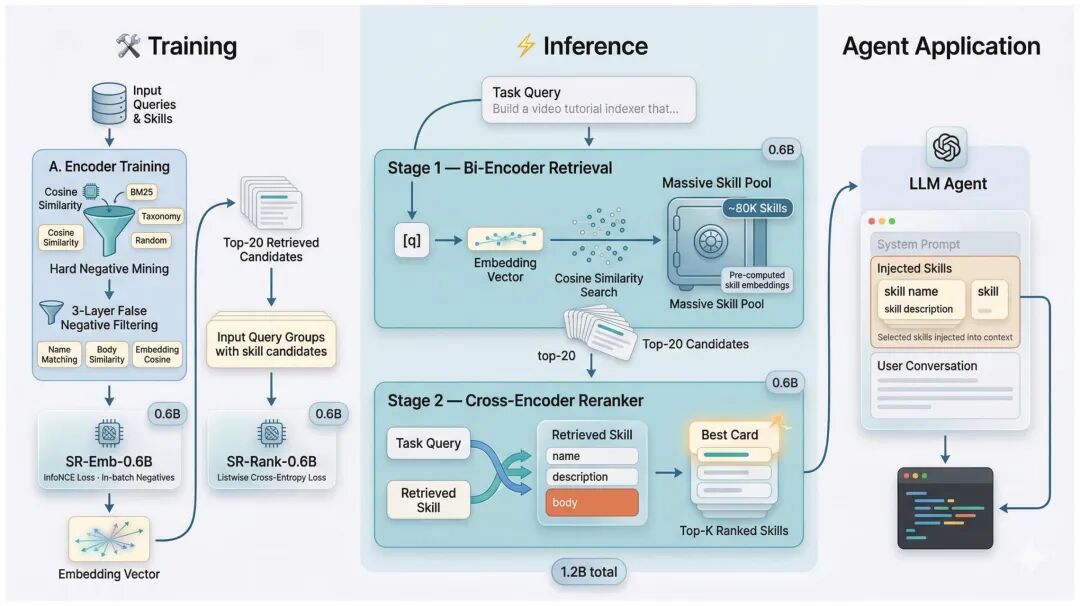
💡 方法简介:
在 80K 技能池上构建含 75 条专家校验查询的基准,分 Easy / Hard 两档,Hard 档注入 780 条同域功能不同的 LLM 干扰项以压测函数级混淆。
通过消融发现:移除技能 body 后,BM25、Qwen3-Emb-8B 和 Qwen3-Emb-8B × Qwen3-Rank-8B 的 Hit@1 分别下降 31.4、38.7、44.0 个百分点;注意力分层诊断显示中间层 name 字段占 3.0% token 却吸引 26.3% 注意力,最后层回归 body,说明并非单纯长度效应。
SKILLROUTER 采用两阶段全文管线:0.6B bi-encoder 从 80K 池中召回 top-20,再由 0.6B cross-encoder 重排,共 1.2B 参数。
训练上提出两个针对同质池的关键适配:三层 false-negative 过滤(name 去重 + trigram Jaccard > 0.6 + embedding 相似度 > 0.92)剔除约 10% 功能等价负例;以及 listwise cross-entropy 重排损失替代 pointwise BCE。
📊 实验结果:
在 80K 主基准上,SR-Emb-0.6B × SR-Rank-0.6B 取得 74.0% Hit@1,超过 16B 的 Qwen3-Emb-8B × Qwen3-Rank-8B 基线 68.0%;8B 扩展版本进一步达到 76.0%。
消融显示 false-negative 过滤贡献 +4.0pp 编码器 Hit@1,listwise 训练比 pointwise 高出 30.7pp,验证两者在同质池中不可或缺。
在独立构建的 SkillBench-Supp(77K 池,256 查询)上同样超越 16B 基线(64.1% vs 63.7%),证明提升不依赖单一基准。
端到端评测覆盖 Kimi-K2.5、glm-5、Claude Sonnet/Opus 4.6 四个编码智能体,SKILLROUTER 相较最强基线路由器在 top-1 / top-10 下平均任务成功率提升 +1.78pp / +2.33pp,其中 Claude 系列更强模型提升达 +3.22pp;真实池 GPU 服务基准上中位延迟仅 495.8ms,显存占用减少 15.8%。
📂 项目主页:
https://github.com/zhengyanzhao1997/SkillRouter
📄 论文原文:
https://arxiv.org/abs/2603.22455
✨ 一句话点评:
SkillRouter 用”body—metadata”的对比首次揭示了技能路由的本质:真正决定选对技能的不是简洁的 description,而是完整的实现体——这意味着未来智能体技能生态的路由层应当从”元数据索引”走向”全文理解”。
💬 本文评论区已开启,但暂无读者留言。
本文转载自微信公众号,如有侵权请联系删除。
- 标题: 阿里提出 SkillRouter:1.2B 小模型解决 8 万技能路由难题
- 作者: lxiol
- 创建于 : 2026-05-08 20:27:05
- 更新于 : 2026-05-12 16:32:44
- 链接: https://blog.lxiol.cn/2026/05/08/阿里提出-SkillRouter12B-小模型解决-8-万技能路由难题/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。