DeepSeek-V4 蒸馏 Qwen3.5,只有 9B,本地能跑
Qwen3.6-27B 量化版本推荐,本地部署
Qwen3.6-27B 开源了,27B 小身板干翻 397B 巨无霸
Claude Opus蒸馏Qwen3.6-27B,GGUF来了,消费级显卡轻松本地部署!Claude Opus 蒸馏 Qwen3.5,V3 来了
神操作再现,单卡 3090 起跑!Claude-4.6-Opus 蒸馏 Qwen3.5-27B
实测 Claude-Opus-4.6 蒸馏版 Qwen3.5,9B 已能打,用 LM-Studio 本地跑,对接 Claude Code
实测,单卡 4090 + llama.cpp 轻松跑 Claude-Opus-4.6 蒸馏版 Qwen3.5 27B,46 Token 每秒!
社区蒸馏热潮又起,这次主角是 DeepSeek-V4 + Qwen3.5,最小一档只有 9B
HuggingFace 用户 Jackrong 放出了一整套合集:Qwen3.5-9B-DeepSeek-V4-Flash——9B 量级的小身板,跑的是 V4 的脑子
合集首页:https://huggingface.co/collections/Jackrong/deepseek-v4-distill
蒸馏是怎么个蒸馏
老章之前讲过蒸馏的本质,这次再用一句话总结:
1 | `大模型(DeepSeek-V4,万亿级 MoE) 当老师 |
但这次蒸馏有几个细节挺反常识,值得展开:
1. 数据集只有 8000 条
是的你没看错——叫 Jackrong/DeepSeek-V4-Distill-8000x,名字里就写了 8000
蒸馏圈里的常识是「数据越多越好」,但 Jackrong 这次反其道而行:少而精
模型卡里直接引用了一篇近期论文 Rethinking Generalization in Reasoning SFT (arXiv:2604.06628) 的两个观点:
- 高质量长 CoT 数据能让小模型获得跨域迁移能力
- 优化纪律:8000 条精选 + 短训练,比海量数据更能避免「过拟合老师风格」
简单说:让学生学到老师的推理引擎,而不是只学口头禅
2. 训练栈是 Unsloth + NVIDIA DGX
模型卡里提到的训练配置:
- 硬件:NVIDIA DGX
- 训练框架:Unsloth(梯度稳定)
- 合作方:硬件工程师 Kyle Hessling(@KyleHessling1)提供算力和 post-training 测试
3. 老师 DeepSeek-V4 自己就很硬
下面这张是 DeepSeek-V4 教师模型的官方性能图:
vLLM 最新版来了,修复 DeepSeek-V4 跑不稳、跑不快的问题
大版本更新,vLLM 0.20 来了,支持 DeepSeek V4
DeepSeek-V4-Flash 本地部署,2 x H20(96GB版本),性能简测
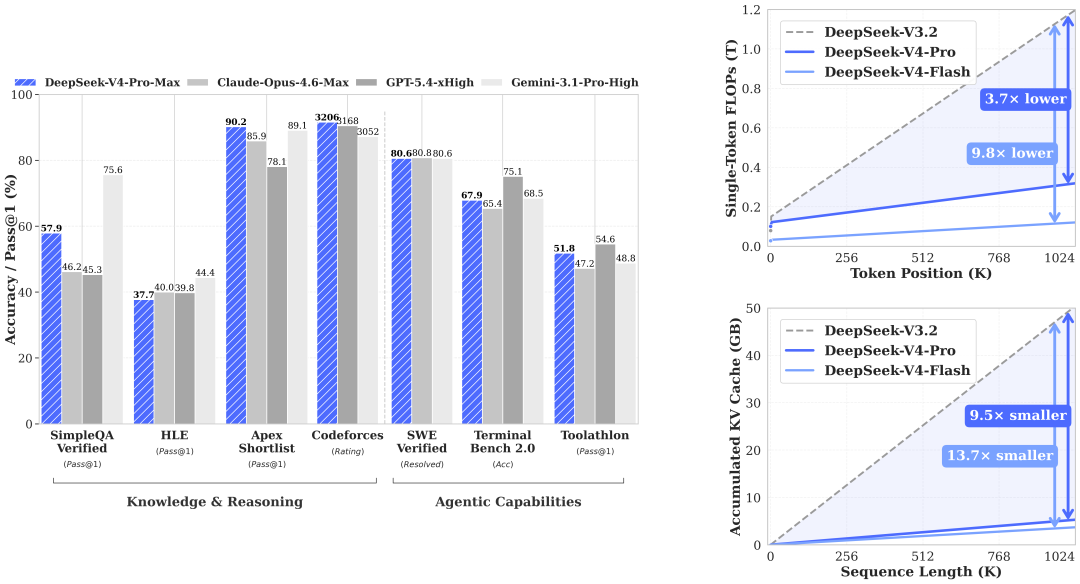
DeepSeek-V4 教师模型性能
DeepSeek-V4 几个关键技术点:
- 1M 长上下文
- Hybrid Attention + DSA(DeepSeek Sparse Attention):KV Cache 降 90%
- Engram Memory + mHC(Manifold-constrained Hyper-connections):把事实记忆和动态推理解耦
- Agent-centric:原生为多步工具调用做了优化
老师配置这么强,蒸出来的学生才有底气
评测:和 Qwen3.5-9B 原版对比
模型卡里给了一份 Q5_K_M 量化下的对照测试,由 Kyle Hessling 在同一台机器、同一套评估流程下分别跑了两个模型
下面这张是综合得分对比:
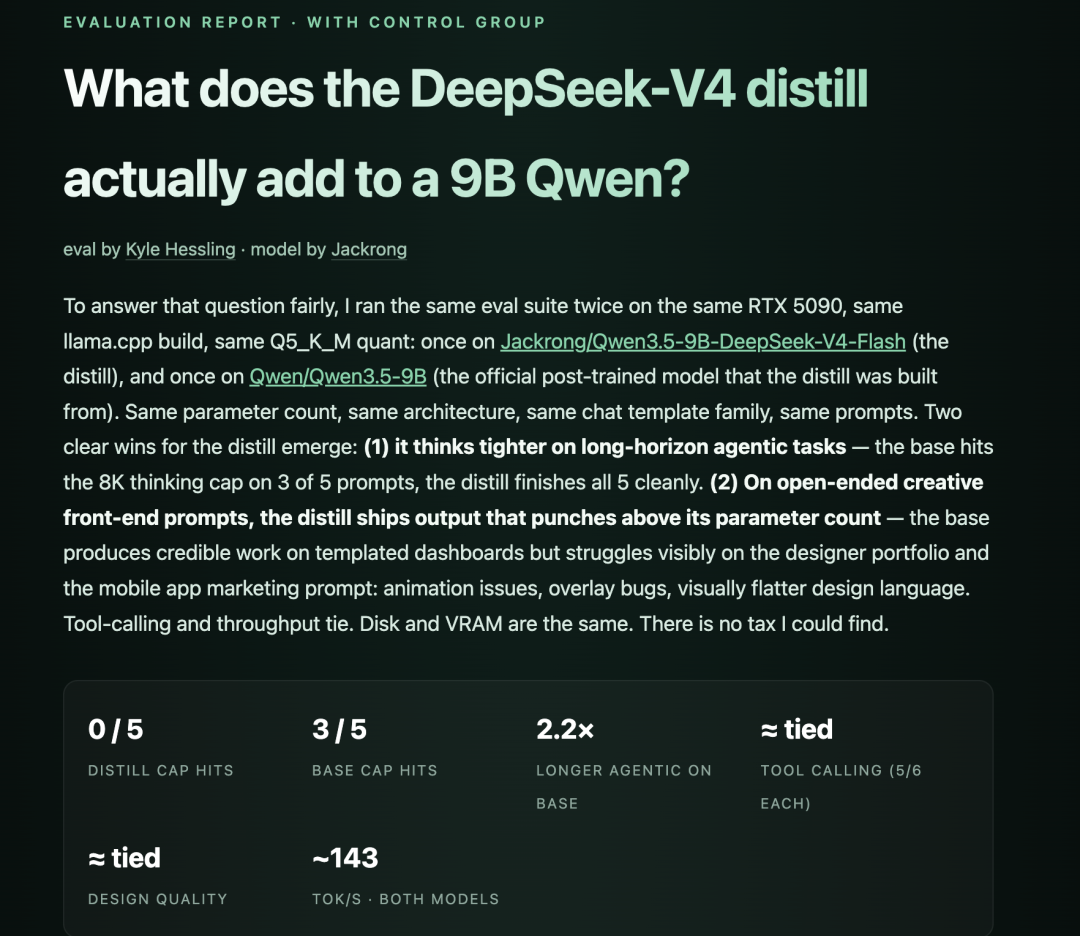
综合评测报告
Agent 推理能力(蒸馏的强项)
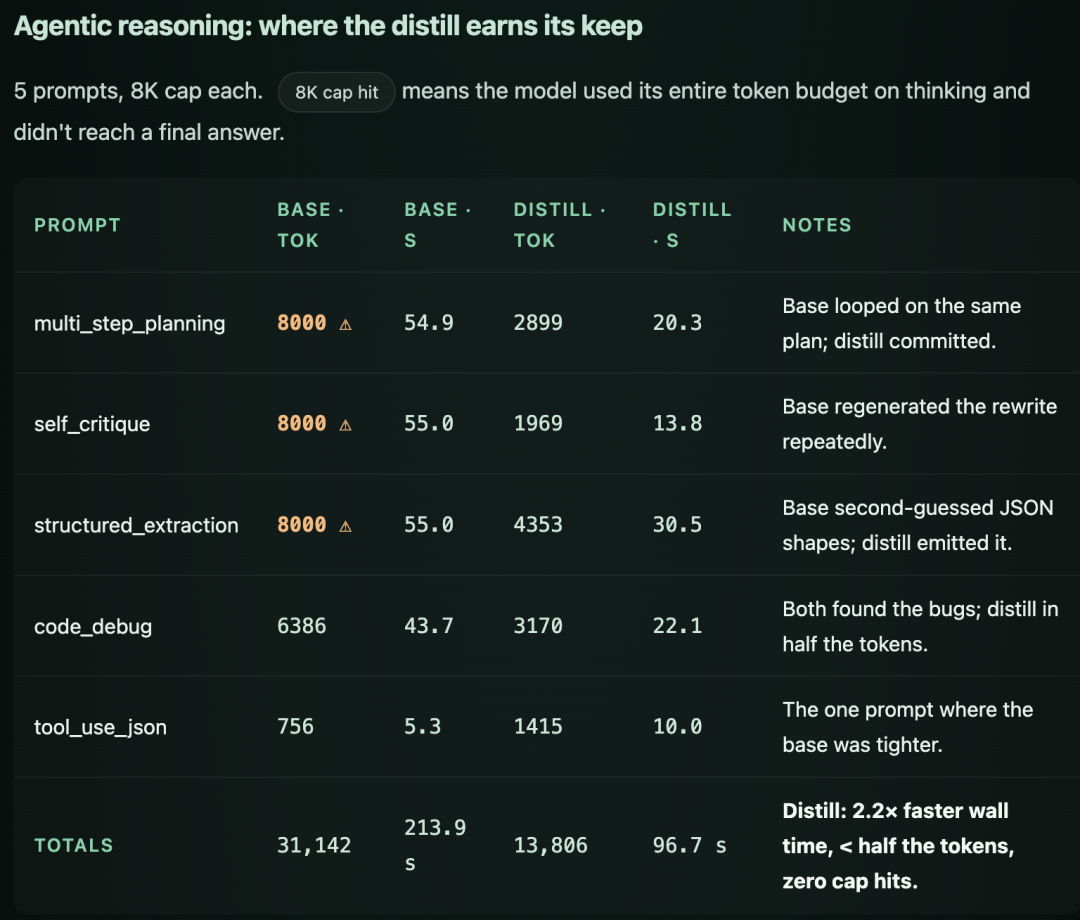
Agentic 推理对比
工具调用
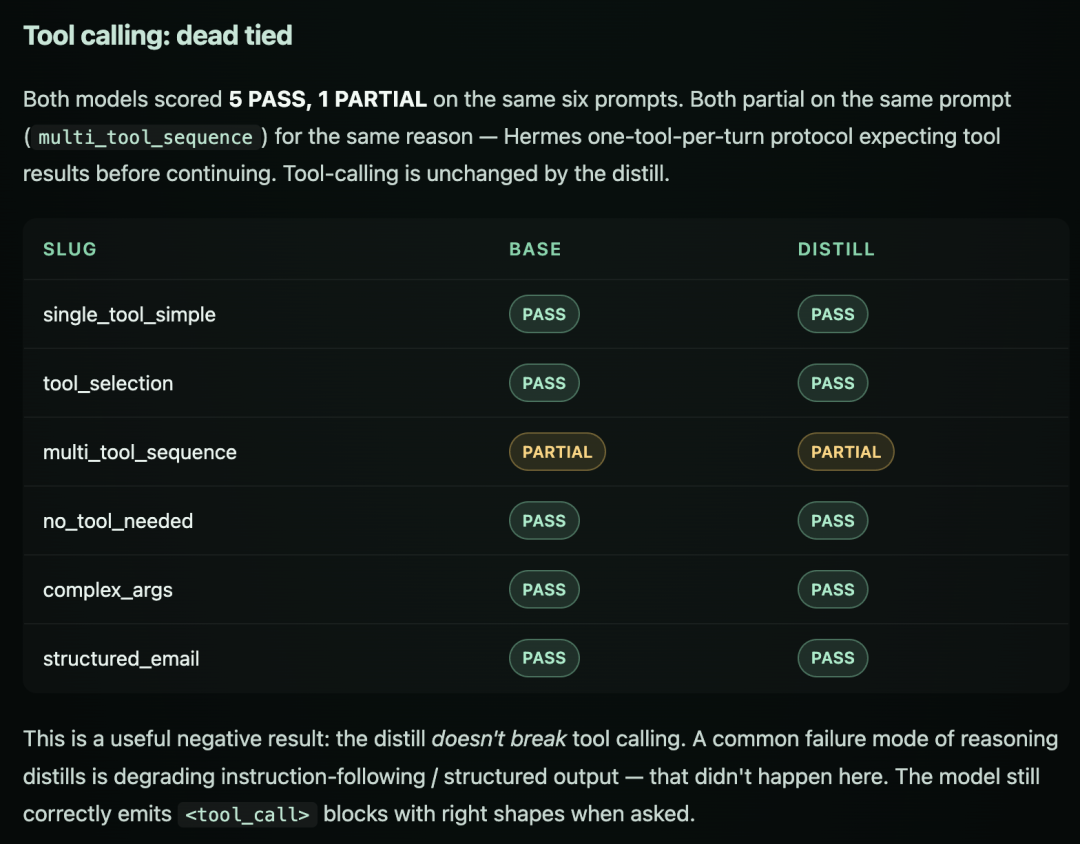
Tool Calling 对比
前端代码
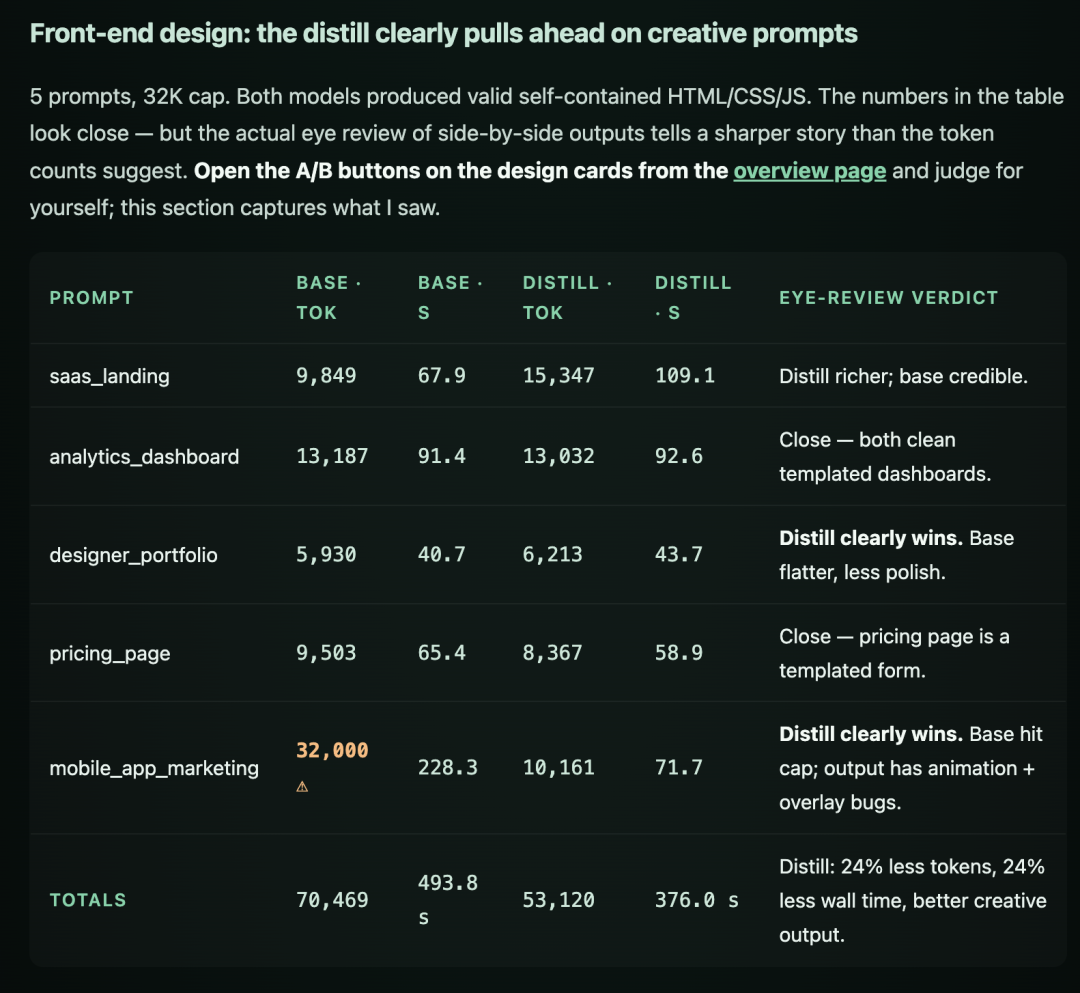
Front-end Design 对比
评测方法说明
为了避免「自卖自夸」,作者把对照方法直接公开了:

对照评测方法

评测环境配置
老章看下来的结论:结构化推理、工具调用、前端代码这三块,蒸馏版稳吃原版——这正是教师 DeepSeek-V4 最擅长的领域
全格式覆盖:随便挑一个就能跑
Jackrong 一次性放出了 6 个版本,几乎所有本地推理框架都能直接拿来用
版本
说明
HuggingFace 链接
原始 BF16
全精度,可继续微调
Qwen3.5-9B-DeepSeek-V4-Flash
GGUF
llama.cpp / Ollama / LM Studio 通吃
GGUF 版
MLX 4bit
Mac 极致省内存
MLX-4bit
MLX 6bit
Mac 平衡档
MLX-6bit
MLX 8bit
Mac 高质量档
MLX-8bit
MLX BF16
Mac 全精度
MLX-bf16
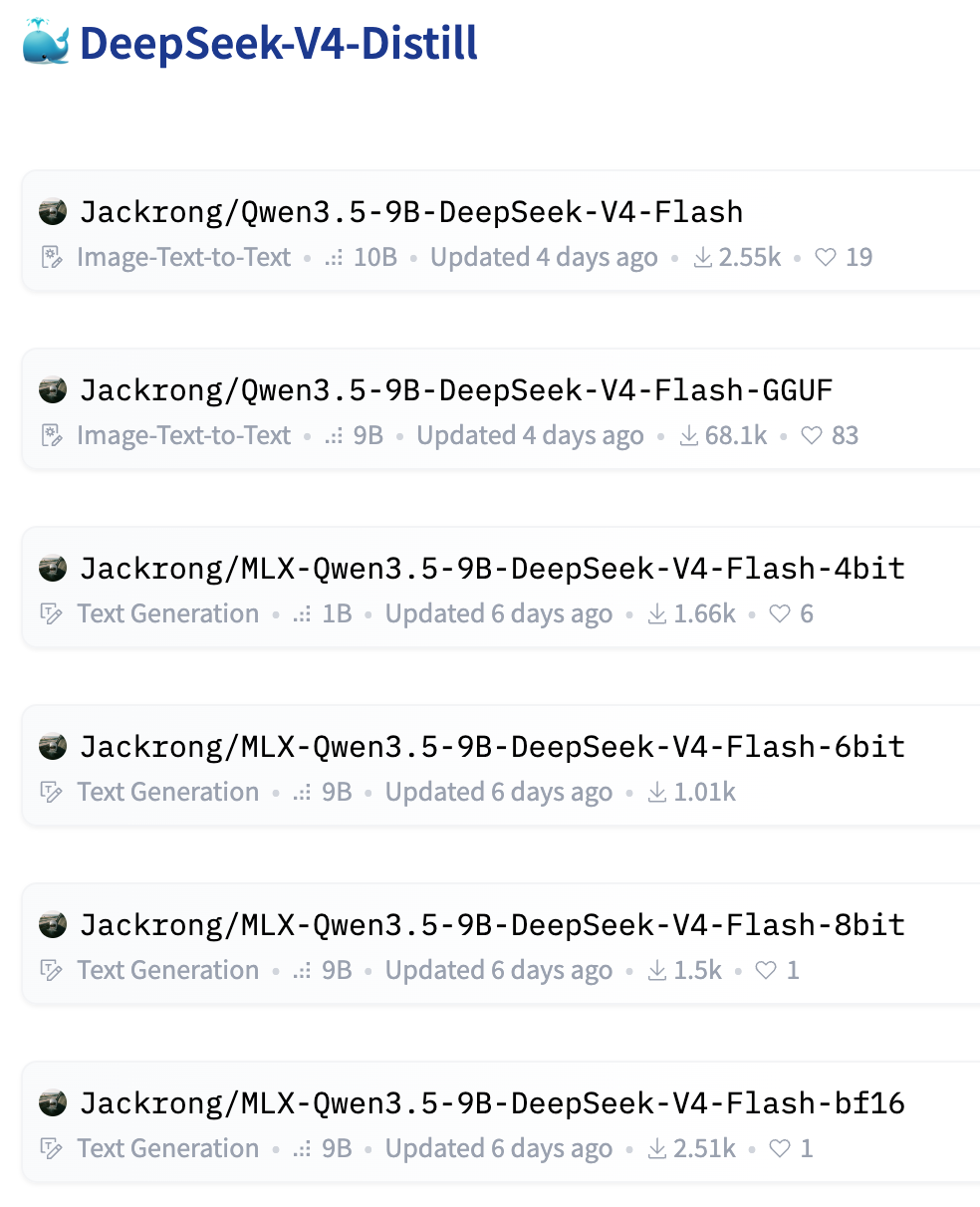
GGUF 仓库
社区认可度可见一斑——发布几天,GGUF版下载就到了 68k
MLX 4bit:M 系列 Mac 直接起飞
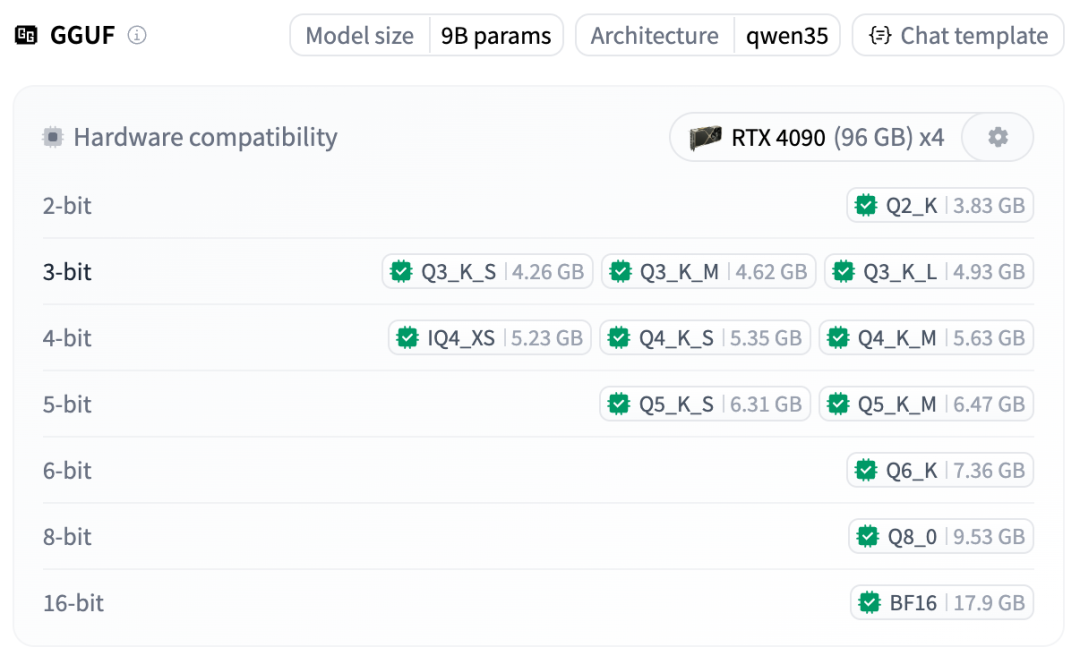
MLX 4bit 仓库
9B + 4bit,理论上 16G 内存的 M2/M3/M4 都能畅快跑——老章手上的 Mac 已经在排队
BF16 原始权重
这个是给「研究党」准备的——做继续微调、自蒸馏、严肃评测都需要从原始权重出发
推荐用法
模型卡里给了一组建议参数:
1 | `temperature = 0.7 ~ 1.0 |
顺手介绍一个数据集
顺便介绍一份开源数据:GLM-5.1-Reasoning-1M-Cleaned
地址:https://huggingface.co/datasets/Jackrong/GLM-5.1-Reasoning-1M-Cleaned
100 万条从 GLM-5.1 收集清洗过的推理样本——注意这个有意思的细节:
- 蒸馏目标是 DeepSeek-V4
- 底座模型是 Qwen3.5
- 训练数据是 GLM-5.1 出来的
社区蒸馏越来越像「调鸡尾酒」——每个组件都从开源生态里挑最合适的
虽然这次 Flash 模型只用了 8000 条 V4 蒸馏数据,但 1M 这份大数据集给后续做 SFT、做自己的蒸馏方案的人留了很多空间
老章的看法
这套合集最戳老章的几个点:
1. 9B 是真·甜点尺寸
放在两年前你说 9B 够用,没人信。但今天的 9B 蒸馏模型,常规问答、代码、Agent 推理基本能顶过去 30B 老模型——这就是「教师→学生」蒸馏路线的红利
2. 8000 条 vs 100 万条的对照
用极少的高质量数据,配上短训练周期,做出能打的小模型——这条路证明了「数据质量 >> 数据量」在蒸馏场景的价值
3. 全平台覆盖
GGUF + MLX 几乎覆盖所有本地推理栈,下载就能用,不挑显卡不挑系统——这是给个人开发者最大的善意
4. 评测开放
Kyle Hessling 把评测方法、对照基准、原始数据都放出来了,社区可以复现——这种透明度比闭门跑分实诚得多
适合谁:
- 想本地跑推理模型、又不想上 32B/70B 的开发者
- Mac 用户(MLX 全套支持)
- Agent / 工具调用 / 前端代码场景
- 想做继续微调或自蒸馏的研究者
不太适合:
- 严肃生产环境——蒸馏小模型在长文档、超复杂多轮场景下还是会比满血 V4 弱一截
- 期待中文创作能力跨级提升的——蒸馏更多保留逻辑能力,文风创意没那么强
总结
DeepSeek-V4 蒸馏到 9B、6 种格式全平台覆盖、社区免费送、评测全公开——本地大模型的入门门槛又被踩低一截
老章建议:Mac 用户先上 MLX 4bit,PC 用户上 GGUF,机器够强的可以拉 BF16 自己玩
#DeepSeek #Qwen3 #蒸馏 #本地部署 #MLX #GGUF
制作不易,如果这篇文章觉得对你有用,可否点个关注。给我个三连击:点赞、转发和在看。若可以再给我加个🌟,谢谢你看我的文章,我们下篇再见!
💬 本文评论区已开启,但暂无读者留言。
本文转载自微信公众号,如有侵权请联系删除。
- 标题: DeepSeek-V4 蒸馏 Qwen3.5,只有 9B,本地能跑
- 作者: lxiol
- 创建于 : 2026-05-08 21:46:25
- 更新于 : 2026-05-12 16:07:03
- 链接: https://blog.lxiol.cn/2026/05/08/DeepSeek-V4-蒸馏-Qwen35只有-9B本地能跑/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。