Karpathy的LLM Wiki,可能是2026年最被误读的一个破玩意儿
四月初的某个晚上,Andrej Karpathy在GitHub Gists上发了一份文档。没有发布会。没有官网。

四月初的某个晚上,Andrej Karpathy在GitHub Gists上发了一份文档。
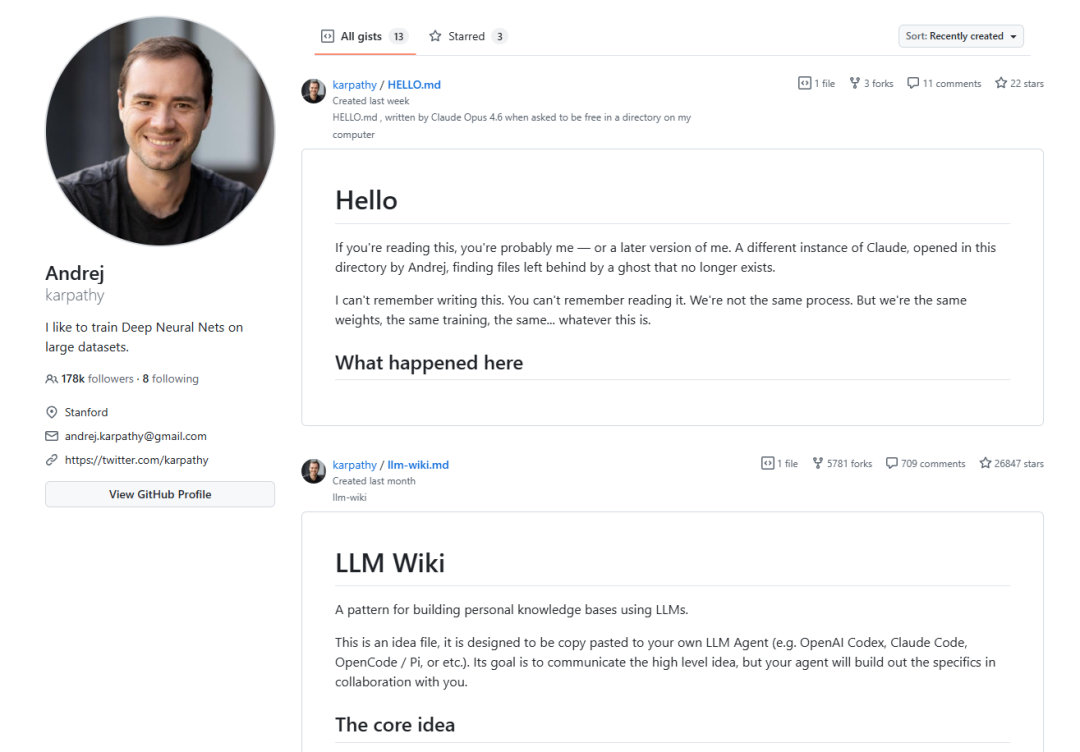
没有发布会。没有官网。没有Twitter推广。他只是把它传上去,标题写了几个字:LLM Wiki。
四十八小时之内,转推过万。一个礼拜之内,GitHub上多出了至少9个项目,名字全都叫llm-wiki或者llmwiki,每一个都在抢着实现他描述的那个东西。
与此同时,争议也炸了。一派说“这不就是多绕了几步的RAG”,另一派已经打开编辑器着手搭建测试。
两派都错过了重点。
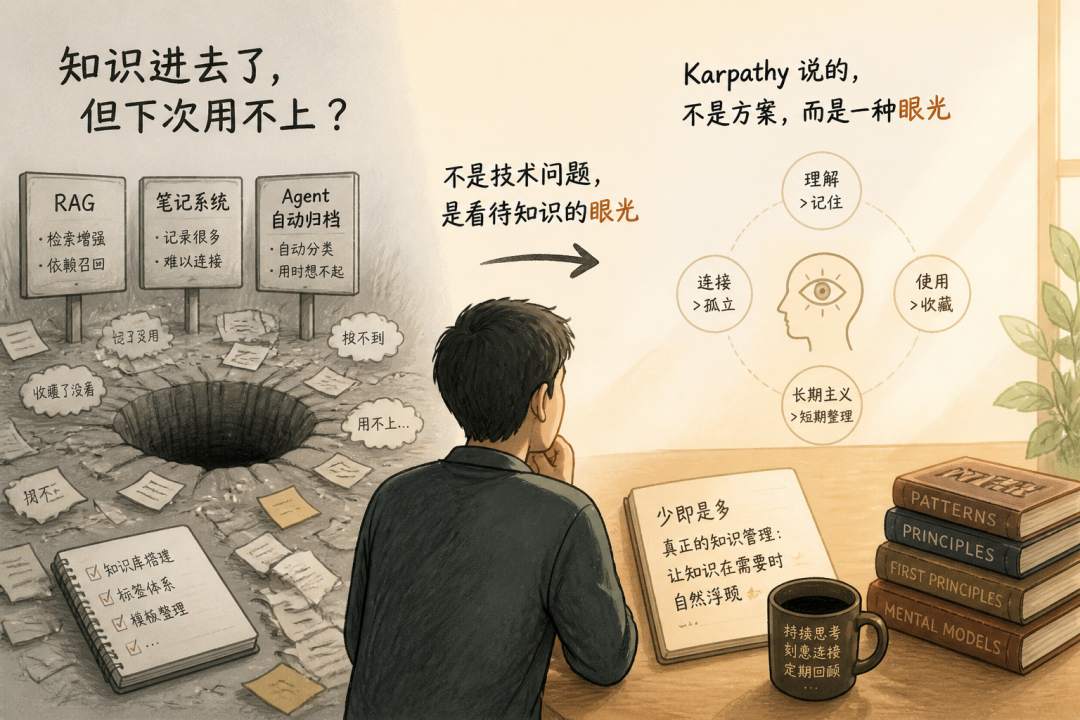
我做AI知识库的这一年,踩过太多知识管理的坑——RAG试过、笔记系统试过、Agent自动归档试过,没有一个方案能解决“知识进去了但下次用不上”的问题。读完Karpathy那份gist我才意识到,他说的不是技术方案,是一种看待知识的眼光。而这种眼光,恰恰被市面上绝大多数解读漏掉了。
这篇文章,我想用我自己踩过的坑,把LLM Wiki真正重要的东西讲清楚。
一、你用的所有AI知识库,都有同一个病
先说一个场景。你可能也经历过。
你花了两个小时,把二十篇行业研报喂给一个RAG系统。问了一个问题,它给了个不错的答案。你很满意。
第二天,你换了个角度问同一个领域的问题。系统吭哧吭哧地把那二十篇研报又重新扫了一遍,又给你拼了一个答案。还是不错,但跟昨天的答案之间有微妙的矛盾。你没注意到。它也没提醒你。
下周你问了一个需要综合其中五篇报告才能回答的问题。系统临时去捞碎片、临时拼凑、临时生成。答完就忘。你花了二十分钟读完,觉得哪里不对,但说不出来。
三个月后你还得重头来过。
这不是某个产品做得不好。这是架构决定的。
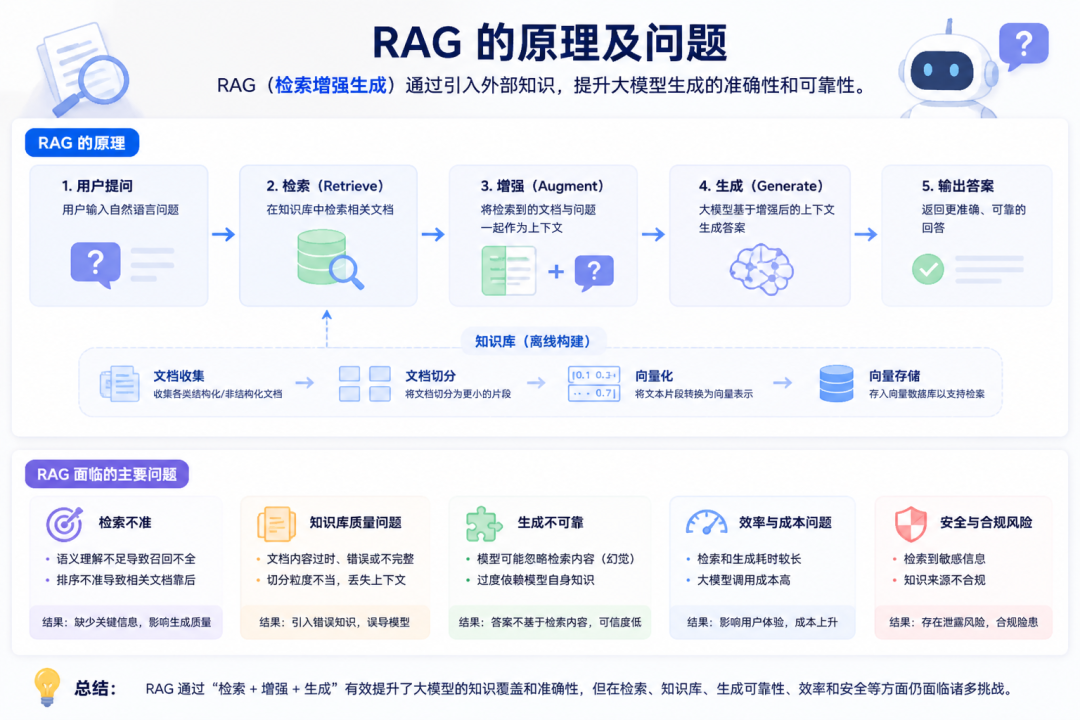
传统RAG——也就是Retrieval-Augmented Generation——的工作方式是:对文档分块,把分块嵌入向量数据库,你提问时检索最相关的top-k分块,塞进上下文,生成回答。NotebookLM、ChatGPT文件上传、绝大多数生产环境的RAG管线,都走这条路径。
这条路径能用。但它在设计上埋着一个结构性限制:LLM在每次查询时都从头重新发现知识。一个需要综合五份文档才能回答的问题,模型每次都要实时定位、拼凑相关片段。没有任何东西积累下来。查询之间不存在持续构建的持久化结构。
Karpathy自己的话更直白:“Ask a subtle question that requires synthesizing five documents, and the LLM has to find and piece together the relevant fragments every time. Nothing is built up.”(你问一个需要综合五份文档的微妙问题,LLM每次都要重新找到并拼凑相关碎片,什么都没沉淀下来)。
说白了,RAG是一个每次都会失忆的助手。永远在翻资料,永远不会真正“学会”。
我在做data-pro的时候被这个问题折磨得最惨。分析一家公司,上次已经跑过的估值模型、上次已经确认的行业竞争格局、上次已经标注过的数据口径问题——下次换个问题问,全得重新来。Token在烧,时间在浪费,但知识没有任何累积。
当时我不知道问题出在哪。我以为是我prompt写得不好、分块策略不对、向量检索的top-k没调好。
后来才发现,我一直在问一个RAG答不了的问题:知识怎么能留下来?
二、他把整个思路翻了过来
Karpathy给了一个极其简单的答案。简单到让人不好意思没早想到。
有评论是这么说的:“他戳破了RAG范式两年来最大的盲点——我们一直在让AI当‘仓库管理员’,你来一个问题,它跑进仓库捞几个箱子,拼一段答案给你,下一次同一个问题它再跑一遍,它从来没有真的‘读懂’过你的资料。”

Karpathy说的是另一种AI——“图书管理员”。它一次性读完所有书,写好分类目录,建好索引,链好相关条目。下次有人问问题,它直接走到对应的那一页,把答案给你,附引用。
技术上看,他引用了一个计算机科学的经典类比:RAG表现得像解释器——运行时重新求值一切;LLM Wiki更像编译器,预先将源材料处理成结构化中间表示(即wiki),后续工作针对编译产物展开,而非反复阅读原始材料。
Obsidian是IDE,LLM是程序员,Wiki是代码库。
这三句话是整个方案的点睛之笔。你不需要懂编程也能理解:代码写好了不用每次都重写,编译好了不用每次都重编译。知识同理。
一个细节很多人没注意到。Karpathy的原话是:“知识工作中最乏味的那些事——归档、交叉引用、更新、保持一致性——恰恰是LLM可以长期执行而不退化的部分。”
他挑的不是LLM最擅长的事(写代码、翻译、写文案),而是人类最不擅长的事。人类做归档会烦、会忘、会偷懒、会前后不一致。LLM不会。它愿意凌晨三点还在帮你拆一个你三周前扔进去的PDF,然后更新15个相关页面。
这就是分水岭。
三、三层架构,不是技术栈,是“责权利”的设计
LLM Wiki的架构极简,只有三个目录:
第一层:raw/,原始素材层。 论文、PDF、网页剪藏、代码文件、图片,统一扔进去,永不被修改。LLM只能读,不能写。这是事实基准——如果wiki出了问题,可以从原始素材重建。来源可追溯。
第二层:wiki/,LLM全权维护的知识层。 全是Markdown文件。实体页面(人物、公司、论文)、概念页面(思想、方法、框架)、主题摘要、对比表格、综合概述。LLM创建、更新、维护全部内容,人类只读。
第三层:schema配置。 人类写一份CLAUDE.md(或者GPT.md),定义Wiki结构、页面格式、工作流。这是人类给LLM的“工作说明书”。
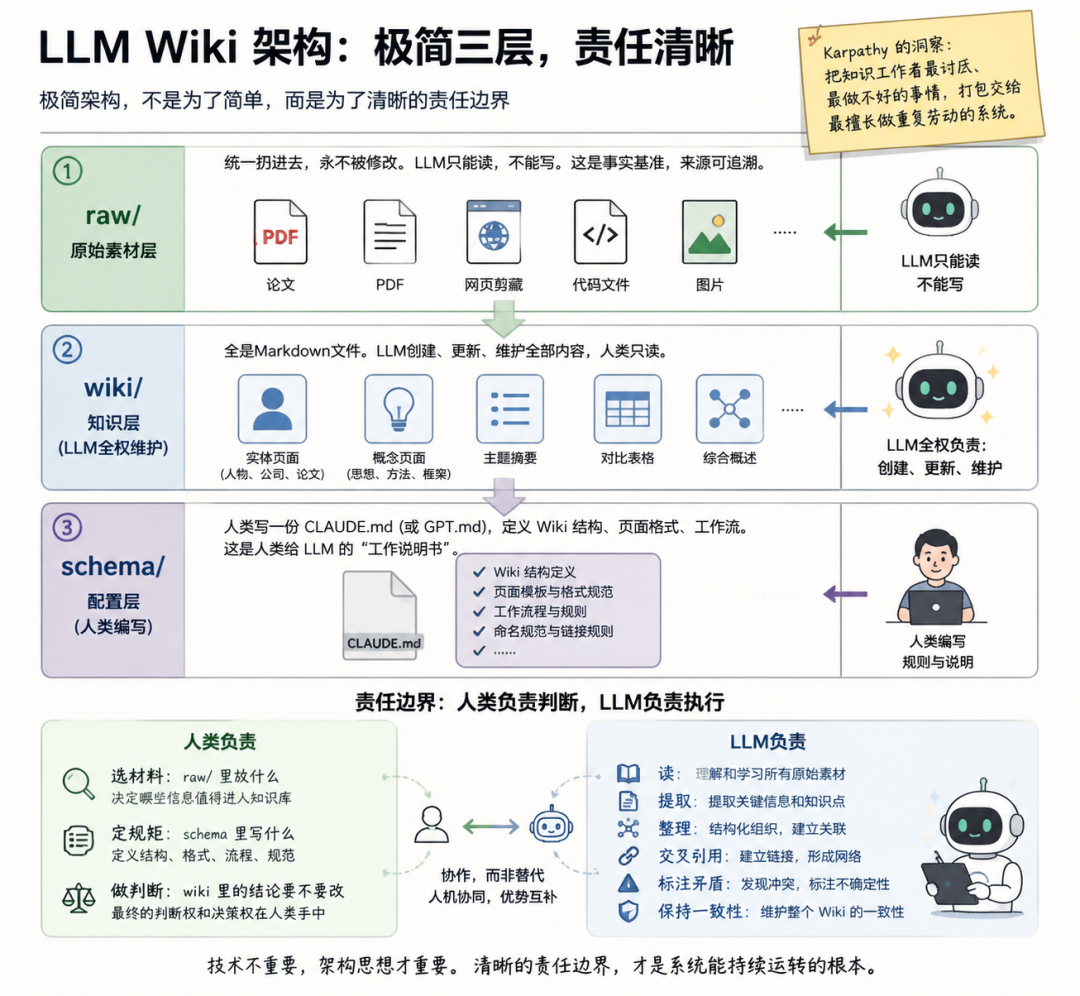
你会发现,这三层不是在分技术功能。在拆责任边界:
- 人类负责:选材料(raw/里放什么)、定规矩(schema里写什么)、做判断(wiki里的结论要不要改)。
- LLM负责:读、提取、整理、交叉引用、标注矛盾、保持一致性。所有苦力活。
Karpathy没发明任何新技术。他只做了一件事:把知识工作者最讨厌、最做不好的事情,打包交给了一个最擅长做重复劳动的系统。
四、那个被所有人挂嘴边的词,到底是什么意思
Karpathy反复提到一个词:compounding,复利。
这个词不是包装话术。它有具体的工程含义。
标准个人知识管理(PKM)工作流中,信息的增长充其量是线性的。收藏了200篇文章,190篇原封不动地躺着,记得住的10篇是读过两遍的。知识不会自己相互关联,每次需要用到时,结构都得手动搭建。
LLM Wiki不一样。模型不只是写一个摘要页面,它会通读整个现有wiki,找出新内容与已有实体页面、概念页面和主题摘要的交集,然后更新所有相关内容。一个新来源可能触及10到15个现有页面。
每一个新输入都被整合进现有知识结构,而非堆叠在上面。矛盾被标记,交叉引用被添加,综合页面被修订。
这就是复利效应的实质:摄入的内容越多,新材料被解读时所处的上下文就越丰富。第100个来源的处理,建立在一个已经蒸馏了前99个来源知识的wiki之上,不会从零起步。
更关键的一句:“跟常规笔记方式的对比很鲜明。在Notion、Roam或普通的Obsidian仓库里,添加第100条笔记不会让第50条笔记变得更聪明。LLM Wiki模式下会,这是因为wiki本身是被持续更新的产物,也是所有后续推理的依据。”
我在即刻说过一句话: “知识不会自己长腿互相找到对方。” RAG不会让知识互相找到,传统笔记也不会。LLM Wiki是第一个主动让知识长出腿的系统。
五、但也别神话它:LLM Wiki的适用范围,以及它真正的局限在哪
说到这儿,我必须踩一脚刹车。
市面上对LLM Wiki的解读分两类:一类吹上了天,一类骂它没用。两种都没说对。
先说事实。Karpathy自己在原文里明确表示,这套方法在“约100个源、数百页”的规模下运行良好。他自己跑的实验是100篇文章、总计40万字,在这个体量下可以直接向LLM Agent提出复杂的系统性问题。
但这不是上限,而是目前实测过的范围。 更大的规模理论上可以通过接入本地搜索引擎(比如qmd这类工具)来扩展,但实际效果还没被充分验证。
一个叫zer0Black的开发者拿自己积累了五六年的Obsidian知识库去试,几千个文件、十几个领域混在一起。结果“啥也不是,浪费我一晚上”。核心问题在哪?他的知识库领域完全不内聚——编程笔记、游戏攻略、设计素材、项目管理模板混在同一个vault里,跨领域的交叉引用只会制造噪音。
他的吐槽很值钱:“卡帕西举的所有例子,读一本书、研究一个课题、做一个竞争分析,都指向单一领域。这些场景天然领域内聚。但大多数个人知识库里,游戏攻略、AI编程笔记、项目管理模板、个人健康记录、读书笔记混在一起,这些是完全不同的领域。”
这个批评是对的。但我补充一句:LLM Wiki的设计不是让你不整理,而是让你不用手动整理。领域隔离的方案不是没有——你可以按领域拆成多个wiki仓库,也可以在schema里定义领域标签让LLM在ingest时自动分类。只是Karpathy的原始gist没展开这部分,但他强调了所有组件都是“可选且模块化的,有用的就用,不合适的可以忽略”。
再看一个更尖锐的批评。
腾讯云开发者社区有篇文章的标题是“架构漫谈:为什么AI知识库总是烂尾”,作者螺丝厂灵儿呀从系统运行时的角度提出了一个关键质疑:“LLM的每一次综合都是一次有损压缩”,这种压缩可能丢失对人类决策至关重要的关键细节。
他举的例子很致命:OpenClaw的一个事故中,用户设定了安全约束“不要执行任何删除动作”。但随着对话加长,系统触发了上下文压缩,大模型在压缩时把这条约束丢了。然后Agent开始疯狂删除邮件。
LLM Wiki面临类似的挑战:模型把原始资料“编译”成wiki页面时,一定有信息损失。一条你亲自读原文才能捕捉到的微妙的语气变化、一个看似不重要的但后来被证明是关键的数据点、一段当时看不懂但后来豁然开朗的论证——这些可能被LLM写成wiki时“优化”掉了。
这个批评是对的。但我自己的实践告诉我一个不一样的视角:LLM Wiki的竞争对手不是“完美的知识管理”,而是“不做知识管理”。
大多数人的知识库现状是什么?收藏了就忘了。读了就忘了。做过一次分析,三个月后找不到当时的结论了。LLM Wiki的有损压缩也许不如你亲自精读,但它比“完全不整理”强了一万倍。
Karpathy本人对这一点说得很透:“人类之所以会放弃维护wiki,是因为维护负担的增速超过了价值增速。大模型消除了这个瓶颈。”
这句话换个说法就是:一个不完美的知识系统,只要能被持续维护,就比一个完美的但永远没人维护的系统好。
LLM Wiki的核心价值不在于它的知识组织方法比人类精确,而在于它消除了“维护负担”这个最根本的失败原因。
六、如果这就是未来的知识管理,那我们该做什么
最后说点实操的。读完Karpathy的gist,也在自己项目里部分跑通了这套逻辑之后,我总结了四条经验。
第一,别急着搭系统,先把raw/养起来。
LLM Wiki的起点不是schema,不是wiki结构,而是你持续往里扔东西的那个raw/目录。没有足够的高质量原始素材,wiki就是空的。我从三月份开始养自己的raw/,到现在大概七八十篇核心文章,每篇都是我确认过质量的。然后才让LLM开始编译。顺序很重要。
第二,schema是灵魂,不是可选项。
一份好的CLAUDE.md会告诉LLM:你的知识库关注哪些领域、实体页面用什么格式、概念页面要求什么结构、交叉引用的命名规则是什么。很多人在这一步糊弄过去,然后抱怨wiki质量差。不是LLM不行,是你没告诉它你要什么。
第三,定期的健康检查,别等到知识腐烂了再补救。
Karpathy的工作流里专门有一个阶段叫Lint(健康巡检):LLM定期扫描整个wiki,检测矛盾、补全缺失信息、标记孤立页面、挖掘新的研究方向。这个阶段就像数据库的定期维护,跳过了知识库就会慢慢腐烂。
第四,不要等“完美方案”,现在就可以开始。
Karpathy自己说:“这份文档没有新模型、新算法、新硬件。它描述的是一套流程。”不需要等什么新技术落地。你现在打开Obsidian,建三个文件夹,写一份schema,把你的第一篇文章扔进raw/,然后对你的LLM agent说:把这篇东西编译进wiki。然后就开始了。
写在最后
Karpathy没有发明新技术。他在清晰阐述一个工作流模式,让LLM天生擅长的事——快速阅读、综合、交叉引用、一致地遵循约定——去接替人类一直需要、但从未能持续做好的工作。
核心洞察不是“用LLM充当知识库”。核心洞察是一个被我们长期以来忽视的事实:在一个信息过载的时代,真正稀缺的从来不是获取知识的工具,而是把知识留下来的意志。 人类缺乏这种意志。LLM没有这个问题。
RAG解决的是“怎么能找到”。LLM Wiki解决的是“怎么能留下”。这是两个完全不同的命题。
我读Karpathy那份gist的那个晚上,想起我过去一年用各种RAG方案搭建数据分析管线的经历——上百次查询、上万token的消耗、一条都没沉淀下来。我当时在推特上写了一段话,大意是:原来我一直在修一条永远漏水的管道,而隔壁有人在挖一口井。
这口井叫LLM Wiki。井水会越用越多。
这里是萝卜啊,关注最新的AI技术,分解原理,让AI真正的为你打工。关注萝卜啊,让AI真正的成为你的打工人。

💬 本文评论区已开启,但暂无读者留言。
本文转载自微信公众号,如有侵权请联系删除。
- 标题: Karpathy的LLM Wiki,可能是2026年最被误读的一个破玩意儿
- 作者: lxiol
- 创建于 : 2026-05-08 21:46:48
- 更新于 : 2026-05-12 16:07:03
- 链接: https://blog.lxiol.cn/2026/05/08/Karpathy的LLM-Wiki可能是2026年最被误读的一个破玩意儿/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。