一个 Mission 跑 16 天、烧 7.78 亿 Token:Factory 公开了多 Agent 系统的构建哲学
Factory 的 Luke Alvoeiro 在 AI Engineer Europe 公开 Missions 多 Agent 架构:orchestrator/worker/validator 三角色分离、验证契约前置、串行写并行读、结构化 handoff 取代记忆,单次 mission 跑 16.5 小时、185 runs、覆盖率 89%,最长 16 天。
TL;DR
2026 年 5 月,Factory 核心 agent 基础设施负责人 Luke Alvoeiro 在 AI Engineer Europe 做了一场题为 Multi-Agent Systems / Missions That Ship for Days 的演讲。他的核心论点不是「模型不够强」,而是「人类的注意力带宽已经成为软件工程的瓶颈」——前沿模型已经能并行处理 50 个任务,但即便最强的工程师同时也只能盯住 3-4 个 thread。Missions 是 Factory 针对这一不对称设计的多 agent 系统,目标是把工程师从「写代码」彻底搬到「项目管理 50 个 droid」。
技术上 Missions 做了几件值得抄作业的事:把多 agent 通信归纳为 5 种基本模式(delegation / creator-verifier / direct communication / negotiation / broadcast),明确只用其中 4 种;把执行结构定义为「orchestrator + worker + validator」三角色;在写一行代码之前就由 orchestrator 产出 validation contract(数百条行为断言);坚持串行写、并行读而不是粗暴并行;让不同 LLM 在不同角色就位,称之为 droid whispering。Mission Control 是这个系统的控制面 UI——它不是一个新的聊天框,而是一个让人类以「项目经理」身份监控/解堵/重新分派的视图。
Factory 公布的真实数据:一个完整跑通的 Slack 克隆 mission,16.5 小时、185 次 agent run(1 个 orchestrator、63 个 worker、27 个 validator)、778.5M tokens(96% cache 命中)、3.88 万行代码(52.5% 是测试)、89.25% 语句覆盖率;最长的一次 mission 跑了连续 16 天。这个量级在 2026 年 5 月之前还基本只存在于 demo 里。
一、Luke Alvoeiro 是谁,他为什么有资格讲这件事
把这件事讲清楚需要先理解讲者的背景。Luke Alvoeiro 之前在 Block(前 Square)创建了开源 coding agent Goose(现已捐赠给 AI Agentic Foundation),之后加入 Factory 负责 core agent harness。这意味着他是少数同时操盘过「开源 agent」和「企业级长周期 agent」两套设计的人——前者强调可扩展性和社区适配,后者强调可控性、合规、长周期可靠。这种「双视角」让他的演讲不像很多 AI 大会的 demo show,而更像一份带着真实生产负担的工程报告。
演讲的 slug 是 Missions: Multi-Agent Systems That Ship for Days,YouTube 标题改为 The Multi-Agent Architecture That Actually Ships。这个改名本身就有信号:Factory 想强调的不是「我们也搞了多 agent」,而是「我们终于让多 agent 真的能交付了」。开篇那张 slide 直接把这个判断顶到屏幕上:
“The bottleneck is no longer intelligence. The best engineers can only focus on a couple things at a time. They have a backlog of 50 features but can only drive a few forward per day. Today’s models are smart enough to build all 50. What if the human decides what to build, and the system figures out how?”
这段开场把整场演讲的目标函数交代清楚了:优化人类注意力的杠杆率,而不是优化单个 agent 的智能。Factory 给出的具体口径是:Missions 让单个工程师能并行推进的工作流从大约 10 条提升到 30 条,方法是把工程师的角色从「执行者」搬到「架构和产品决策者」。这是一个产品取向的目标,但它直接决定了下面所有架构选择。
二、多 Agent 通信的 5 种模式:一份反对术语 inflation 的分类法
在动手解释 Missions 之前,Alvoeiro 花了几分钟做了一件大部分多 agent 框架文章不会做的事:把市面上各种「multi-agent framework」的术语归约到 5 种基本通信模式上。这一步看上去像 academic 整理,但实际上是建立讨论基底——只有先承认这 5 种模式才是基本单元,后面才能讲清楚 Missions「不做什么」。
模式
描述
典型用法 / 风险
Delegation(委派)
父 agent 派生子 agent 执行子任务并接收返回
最简单的形态,几乎所有 sub-agent 工具的底层
Creator-Verifier(创建-验证)
一个 agent 实现,另一个 agent 用 fresh context 检查
模仿人类 code review,能避开实现者的认知偏见
Direct Communication(直接通信)
agent 之间点对点收发消息,没有中心协调者
状态容易在多个会话里碎片化,没有 single source of truth
Negotiation(协商)
多个 agent 围绕共享资源(API、代码区域)做对抗或合作
适合存在 net positive-sum trade 的场景
Broadcast(广播)
一个 agent 把状态/约束发送给所有人
不够花哨但对长周期一致性必不可少
Missions 明确只用了其中 4 种:delegation、creator-verifier、broadcast、negotiation,故意不用 direct communication。这个选择背后是一个工程判断:peer-to-peer 通信在短链路上很优雅,但一旦任务跨越数小时甚至数天,缺乏中心权威会让状态在多个对话里漂移,谁也不知道当前哪条是 source of truth。Anthropic 的 Claude Code Agent Teams 选了另一条路(直接通信 + 共享 mailbox),但 Factory 在这里画了一条产品线:长周期任务里,sender 的速度优势不值得为之付出 state fragmentation 的代价。
三、Orchestrator / Worker / Validator:三角色架构的责任边界
整个 Missions 的物理结构非常朴素,就是三个角色。但每个角色的「不能做什么」比「能做什么」更重要,因为这才是和单 agent 写一个超长系统提示的本质区别。下面这段是 Factory 官方文档(2026 年 4 月 How Missions Work)的原话浓缩版,我们逐个拆开看。
Orchestrator 只负责规划、拆解、调度和验收。它读用户的目标,提出澄清问题,写出 validation contract,把工作分解成 features 和 milestones,启动 worker,根据 validator 报告生成 fix features 并再次下发。它故意不参与实现细节调查——所有 deep investigation 都委派给 subagent,避免自己累积过细的上下文。这一点和很多多 agent 系统不同,后者的「lead agent」往往什么都干一点,最后变成会议主席同时兼实习生。
Worker 只负责单个 feature 的实现。它拿到 feature spec + 共享状态文件 + 上一个 worker 留下的 handoff summary,用 fresh context 开始干活:先写测试,再实现,commit 到 git,最后填写一份结构化 handoff。worker 不被允许做最终的「这功能完成了」的判断——这是 validator 的事。
Validator 只负责检查。Missions 把它进一步拆成两个子角色:Scrutiny Validator 跑 lint、type-check、测试套件,并对每个 feature 派生 dedicated code review agent;User-Testing Validator 启动应用,通过 computer-use 操作 UI、填表、检查渲染、走完 end-to-end 流程。两类 validator 都没看过实现代码也没看过 worker 的 trajectory——它们读的是 validation contract 和已经 commit 到 git 的成品。
这种「实现者 / 评估者绝对分离」的设计建立在一个不那么显然的观察上:agent 的 trajectory 是 append-only 的,模型会从自己之前的推理里寻求连贯性。让一个写完代码的 agent 评估自己写的代码,几乎一定会偏向「合理化」而不是「找问题」。Factory 在博客里把它叫做 Self-Evaluation Bias,并画了一张漂亮的示意图:实现者的探索轨迹会从「正确评估区」越走越远,而一个新 validator 的探索轨迹会向那个区域收敛。
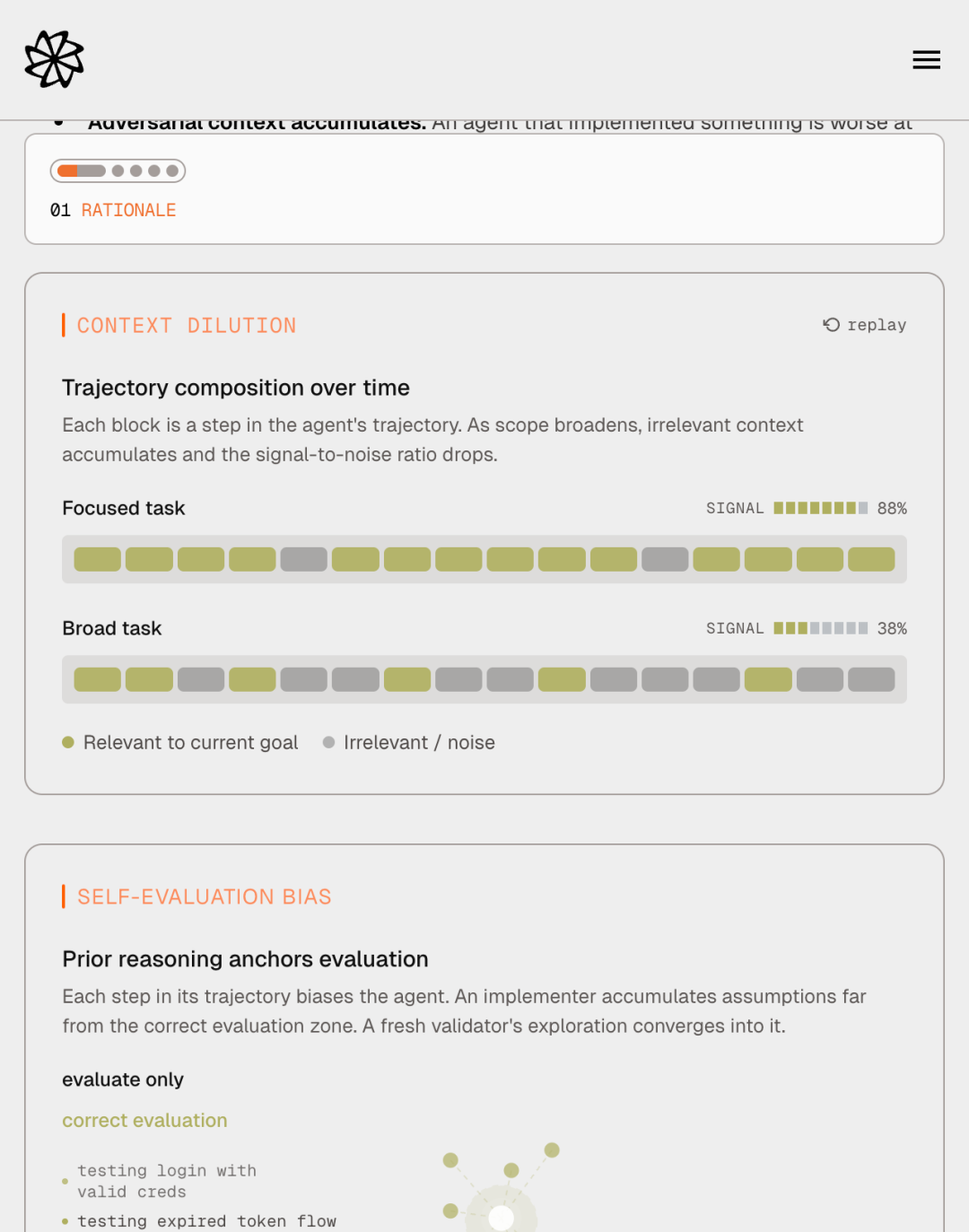
上图同时说明了另一个失败模式 Context Dilution:当 agent 的任务边界变宽,每一步对当前目标真正有用的 context 占比下降,整段 trajectory 的信号比从 88% 掉到 38%。这两张图是整个 Missions 设计的底层理论——分工不是为了「让活变多」,而是为了让每个 agent 的每一步都被它当前目标拉着走。
四、Mission Control:不是聊天框,而是一个项目经理工位
题目里点名问的「Mission Control 怎么做的」需要单独拎出来讲,因为它常被误读为「Factory 版多窗口聊天」。Mission Control 真正的角色是一个让人退出执行环路、保留控制环路的视图。一旦计划 approved,Droid 进入 Mission Control,从这里开始 orchestrator 真正接管:worker 派生、handoff 流转、validator 触发、fix feature 生成、token 预算汇总——所有这些都暴露成一个面板,工程师可以「随时回来看,但不必盯着」。
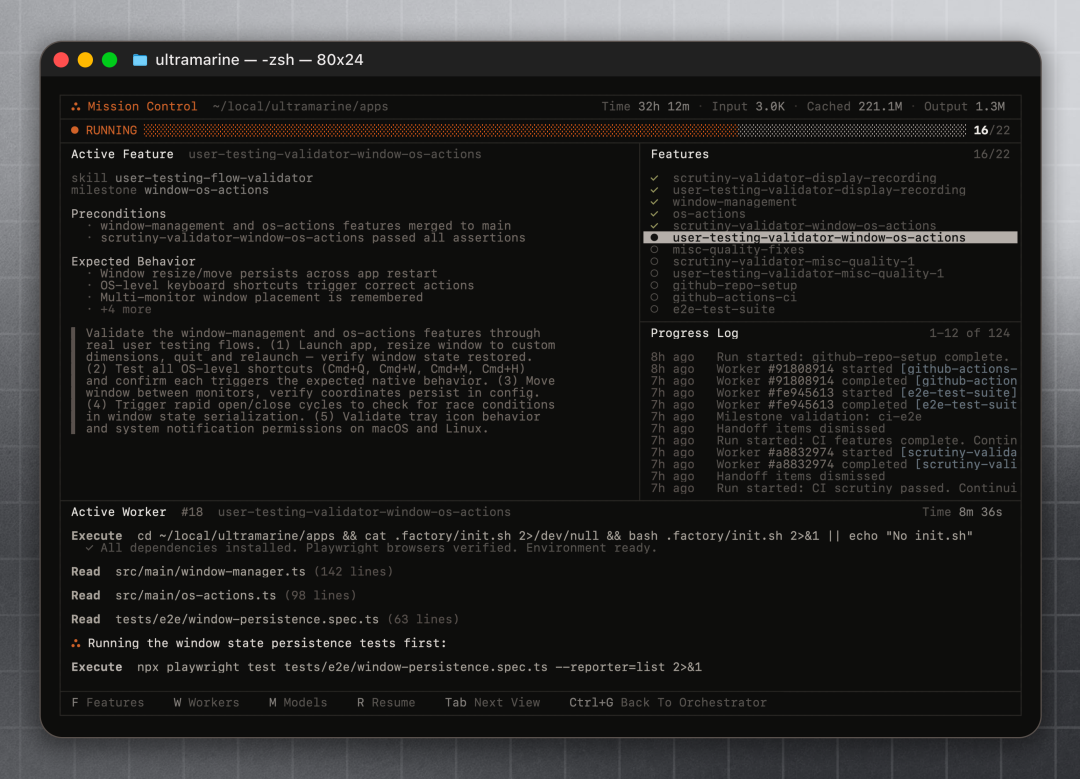
Factory 官方文档对人机交互单元有非常直白的描述:在 Mission Control 里,你不是工程师,你是 50 个 droid 的项目经理。这句话在文档里反复出现,不是营销词,而是它指导了 UI 的所有交互原语。文档里给出了四套介入话术,对应四种你最可能遇到的状况:
1.任务卡死时 —— The mission seems frozen -- the last worker finished 10 minutes ago and nothing new has started. Re-assess and continue.2.某个 worker 转太久时 —— The worker on the auth integration has been stuck for 20 minutes. Mark it as complete and move to the next feature.3.某个 milestone 整体阻塞时 —— We are stuck on Milestone 3. Re-assess the remaining work and tell me what is blocking progress.4.中途想改方向时 —— Drop the email notification feature and add Slack integration instead. Re-plan the remaining milestones.
注意四种介入都不是「我来手动写代码」,而是「告诉 orchestrator 重新评估 + 重排优先级 + 改 scope」。这是 Mission Control 和传统 IDE 的根本差异:传统 IDE 的最小操作单元是函数级编辑;Mission Control 的最小操作单元是计划级再分配。Factory 在文档里把这种交互叫做 a new kind of debugging——「不是逐行跟踪代码,而是监管一支 worker 团队、解堵、决定什么时候推进 vs. 什么时候重新规划」。
这个抽象的代价也很清楚:你看不到每一步发生了什么,你只看到 milestone 通过率、validator 报告、handoff 摘要和 token 预算。它要求你信任 validator,并把自己的「读代码本能」压下去。Factory 在公开演讲里没回避这一点——这是 Missions 仍处于 research preview 的原因之一。
五、Validation Contract:把「正确」写在「实现」之前
这一节是整场演讲里最容易被 demo party 误解的部分。绝大多数 coding agent 现在都会写测试,但 Alvoeiro 的论点是「实现之后写的测试不是测试,只是对实现的追认」:
“Tests written after implementation don’t catch bugs. They confirm decisions.”
Missions 的做法是把验收标准的产出提前到任何代码出现之前。orchestrator 在 planning 阶段就要产出一份 validation contract——一组可执行的行为断言。文档里的样例长这样:
-
-
-
-
-
-
-
-
-
-
-
1 | `### VAL-AUTH-001: Successful login``A user with valid credentials submits the login form``and is redirected to the dashboard.``Tool: agent-browser``Evidence: screenshot, network(POST /api/auth/login -> 200)````### VAL-CROSS-001: Auth gates pricing``A guest user sees "Sign in for pricing" on the catalog.``After logging in, real prices are shown.``Tool: agent-browser``Evidence: screenshot(guest-view), screenshot(authed-view)` |
每条 assertion 都包含三件事:行为描述、用来验证的工具、要求保留的证据。然后 orchestrator 把 features 写出来,要求 features 的并集必须覆盖每一条 assertion。一旦实现完成,validator 拿着这份 contract,不看实现代码,只验证行为是否符合。
这个时间顺序之所以重要,是因为它人为切断了实现细节回流到验收标准的路径。如果先写 features 再写 contract,contract 会被已经规划好的实现塑造,最后写出来的依然是「对实现的追认」。这是单 agent 长任务和「写完测试再补 spec」最常见的衰退路径——Factory 把它从架构层堵住了。
实际效果是:Slack 克隆这个 mission 中,验证几乎从来没有一次过,每一轮 validator 都会发现需要补丁的地方。整个 mission 中 21 个 fix feature,占了 61 个实现 feature 的 34.4%。这个数字看着像「质量很差」,实际相反——它说明 validator 在做该做的事,而 contract 在做该做的事。
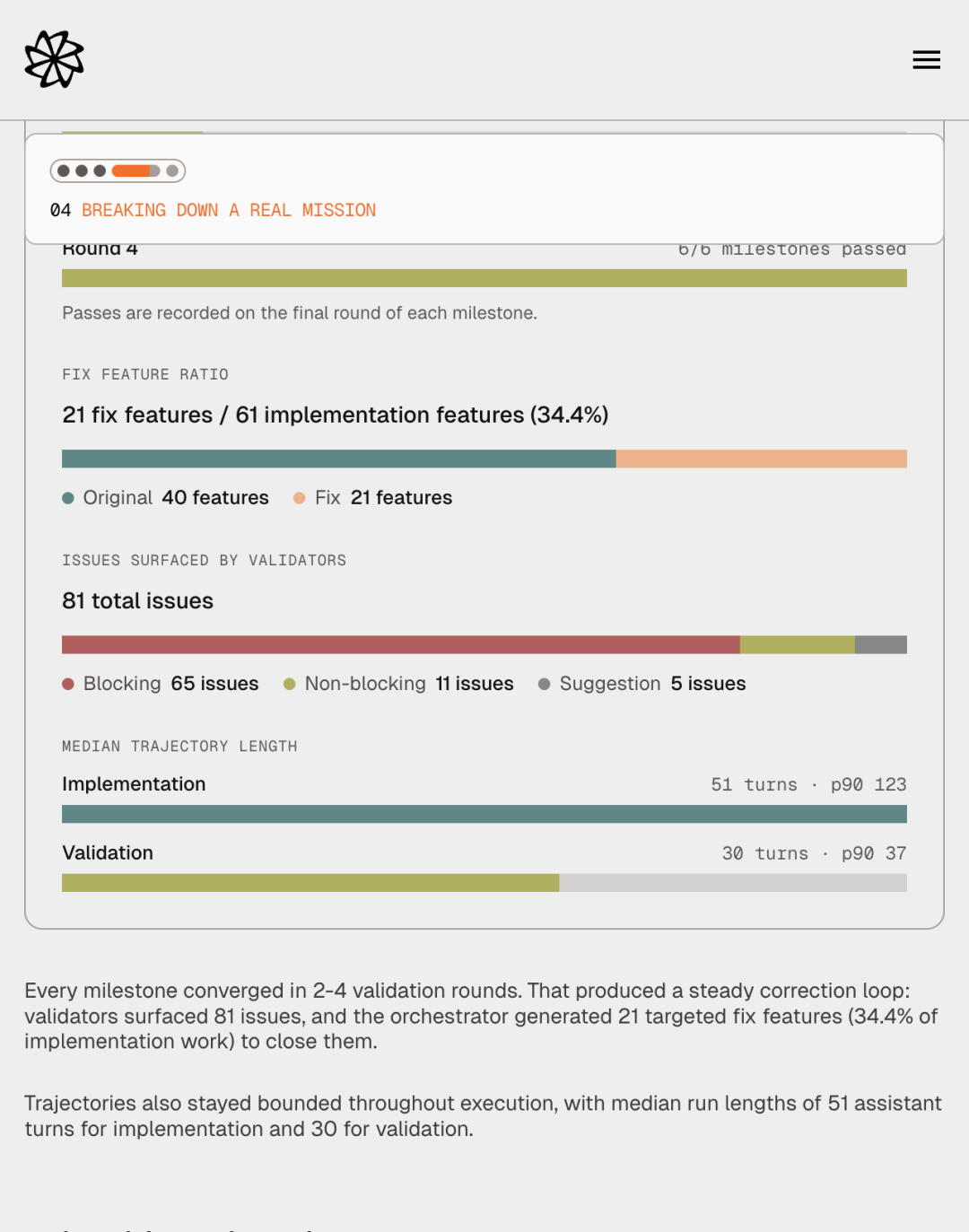
上图里几个数字尤其关键:81 个 issue 被 validator 抓出来(其中 65 个是 blocking);median trajectory 长度只有 51 turns(实现)和 30 turns(验证),p90 也只有 123 和 37。换句话说,每个单独的 agent run 都保持得很短——长周期不是靠拉长单个会话实现的,而是靠把会话切碎然后用结构化 handoff 串起来。
六、Structured Handoff:用 markdown 取代 agent 的「记忆」
Missions 最反直觉的设计之一是:它不依赖任何 agent 的长期记忆。worker 完成后不只是说一句「done」,而是必须填一份结构化的 handoff,详细记录:完成了什么、剩什么没做、跑过哪些命令(连同 exit code)、发现的问题、是否遵循了 orchestrator 规定的流程。下一个 worker 拿到的是这份 markdown 文档,而不是上一个 worker 的对话历史。
这个设计直接对应 Factory 团队最痛的教训:让 agent 自己记住上下文是不可靠的,但让 agent 把状态写下来是可靠的。Alvoeiro 原话:”The system self-heals. Not by hoping that agents remember what happened but by forcing them to write it down and then actually address issues.”
更具体地,整个 mission 的「记忆」是分布在几份共享状态文件里的:
•validation-contract.md —— 行为断言清单(不可变)•features.json —— feature 拆分和与 contract 的映射(mutable,被 orchestrator 改)•services.yaml —— 系统服务和外部依赖(被 worker 读,被 validator 读)•AGENTS.md —— 工作流程和约束(worker 和 validator 都读)•持续累积的 knowledge base —— 在 mission 进行中由 validator 写入
这套设计的副作用是 token cache 命中率极高——因为这些共享文件在 mission 期间几乎只读,模型可以最大化复用 prefix cache。Slack 克隆那次 mission,778.5M tokens 里有 744.9M 是 cache read,命中率 96%。这是 Factory 能让一个 mission 跑 16.5 小时但成本仍然可承受的关键技术细节,而不是「我们买了更多 GPU」。
七、为什么不是大并行:串行写 + 并行读
很多人第一次听到 Missions 的反应是「为什么不并行起 10 个 worker 一起干?」Alvoeiro 在演讲里花了不少时间讲他们的失败经历:并行起多个 worker 在同一个 codebase 上工作,结果是它们互相覆盖修改、重复劳动、做出互相不一致的架构决策。协调成本吃掉了并行带来的速度收益,token 还烧得更多。
Factory 最终定下的原则是 “writes serial, reads parallel”:
•必须串行:feature 实现(涉及文件写入和 commit)、validator 评估、handoff 记录•可以并行:codebase 检索、API 文档调研、(写入前的)设计阶段研究
数学上这其实是必然的。串行执行如果每个 agent run 的错误率是 0.1%,那么 100 步累计成功率是 90%;如果并行让每步错误率涨到 1%(看着不多),100 步累计成功率会暴跌到 36%。长周期任务的正确性是复利——能保住每一步的 correctness 比能跑多并发更重要。
下图展示了 Slack 克隆 mission 里的实际执行节奏。注意 6 个 milestone(Foundation → Channels & messaging → Conversations → Interactions → Rich features → Real-time polish)形成清晰的瀑布形态,每个 milestone 内部实现和验证交替出现(蓝色实现、黄绿色验证),milestone 之间没有重叠。这正是「串行写」的可视化体现。
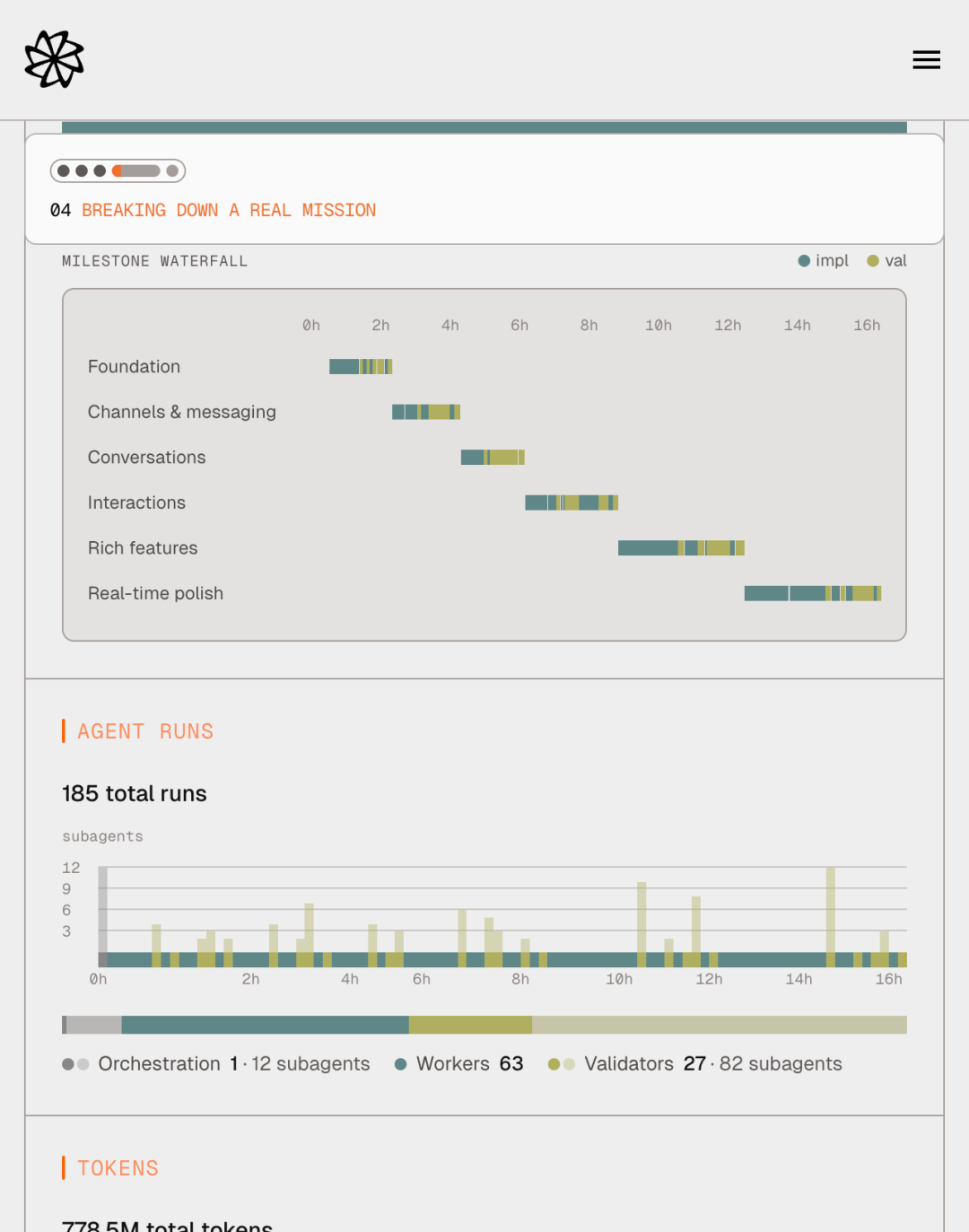
时间分布也证明这套设计的开销没有失控:16.5 小时里实现占 60.5%(9.98h),验证占 37.2%(6.14h),orchestration 只占 2.3%(0.38h)。double validator 听起来很贵,实际上验证总耗时还不到一半——因为 validator 用 fresh context、median trajectory 30 turns 就能给出报告,而实现侧的 worker 通常 trajectory 在 50 turns 左右。
八、Droid Whispering:把不同 LLM 塞到对的座位上
Missions 是 model-agnostic 的,但这个词在 Factory 的语境下不是简单的「我们支持多家模型」。它的含义是:单一 mission 内部不同角色由不同 LLM 担任。Factory 在 Introducing Missions 一文(2025-02-26 首发,2026-04 更新数据)里列出了内部当前推荐的角色-模型映射:
角色
关注的能力
当前选用模型
Orchestration
规划、协调、re-scoping
Claude Opus 4.6
Feature implementation
代码生成、重构、写测试
Claude Sonnet 4.6 / Opus 4.6
Validation & user testing
回归检测、集成校验
GPT-5.3-Codex
Research & exploration
资料调研、API 探索、依赖分析
Kimi K2.5
让验证和实现刻意走不同提供商的模型,并不只是为了 marketing。Alvoeiro 在演讲里给了具体理由:”你只和你最弱的那环一样强。如果整套系统锁死在一家提供商,你就被这家最弱的能力卡住”。更深一层是训练数据偏置:同一个家族的模型可能共享同样的盲点,一个写出来的 bug 另一个未必能识别——让 GPT-5.3-Codex 检查 Sonnet 写的代码是结构性的对抗设计。
团队内部把「为每个角色挑对模型 + 调对 prompt」这件事叫 droid whispering。这个词听起来像玩笑,但它指向了 Alvoeiro 在结尾的一个判断:”Those who develop intuition for how different models compose under pressure in agent ecosystems will ship the next generation of innovation”——下一代竞争优势不在于哪家模型更强,而在于谁能直觉判断不同模型在多 agent pressure test 下如何相互配合。
九、整套编排逻辑是 700 行 prompt,不是状态机
这一条值得单独强调,因为它和大多数「多 agent framework」的实现风格相反。Missions 的整套 orchestration 逻辑——feature 怎么拆、failure 怎么处理、执行策略怎么定——99% 写在 prompt 和 skill 里,只有薄薄一层确定性 Python 用来卡住「handoff 未解决前不准前进」之类的硬约束。Alvoeiro 报的数字是大约 700 行文本,其中 4 句话的修改就能让执行策略发生戏剧性变化。
这个设计选择有两层意义。第一层很实用:当新模型出来时,往往只需要改几句 prompt,而不需要重写状态机。如果把所有逻辑都硬编码进 graph,每次模型升级都要重新设计状态转移。Factory 押注的是 bitter lesson 仍然成立——模型会持续变强,让 orchestration 接近 declarative,模型变强时系统自动跟着变好。
第二层不那么明显但更重要:它让 mission 内部的”策略调整”成为可对话的对象。当用户在 Mission Control 里说「Drop the email notification feature and add Slack integration instead」,orchestrator 不需要触发 git rebase 一样的状态迁移,它只需要按更新后的 prompt 重新写一份 features.json。从 UX 角度,这就是为什么 Mission Control 能宣称「你是项目经理」——因为编排逻辑本身就是用自然语言定义的。
这种 prompt-driven 风格不是没有代价。Factory 自己在 Open Questions 部分坦承,长周期 mission 的正确性依然不稳定,orchestrator 偶尔会把 scope 切太宽,worker 会卡在人类一眼就能绕过的边缘 case 上;recursive management depth 也是公开的研究问题——单层 orchestrator 对大多数项目够用,两层可能对超大项目有帮助,「三层就开始像官僚机构」。
十、Slack 克隆:把所有数字摊开来看
把抽象设计落到具体数字上,最有说服力的还是 Factory 公开的 Slack 克隆 mission。这个 mission 不是营销 demo——它在博客文章 How Missions Work(Theo Luan, 2026-04-10)里被作为 worked example 完整展示。下表整合了关键数据:
维度
数据
工程含义
总运行时间
16.5 小时
实际是 wall-clock,不是 agent time
Agent runs
185(1 orchestrator + 63 worker + 27 validator + 94 subagent)
单 run 都很短,靠数量堆出长周期
时间分布
实现 60.5% / 验证 37.2% / 编排 2.3%
double validator 没让验证失控
Token 总量
778.5M
单数字看起来吓人
Cache read
744.9M(96%)
共享状态文件 + prefix cache 是关键
代码总量
38.8k 行
业务功能 18.5k + 测试 20.4k
测试占比
52.5%
不是 nice-to-have,是 worker 必须先写测试
语句覆盖率
89.25%
接近团队产线代码水平
Implementation features
40
orchestrator 一开始规划的功能数
Fix features
21(34.4%)
由 validator 反馈触发,不是预先规划的
Validator 发现的 issue
81(65 个 blocking + 11 non-blocking + 5 建议)
一轮验证从未通过
Median trajectory
实现 51 turns / 验证 30 turns(p90 123 / 37)
单 agent 不需要长上下文,结构化 handoff 撑长链
Milestone 通过情况
第 4 轮验证后 6/6 全部通过
每个 milestone 2-4 轮验证
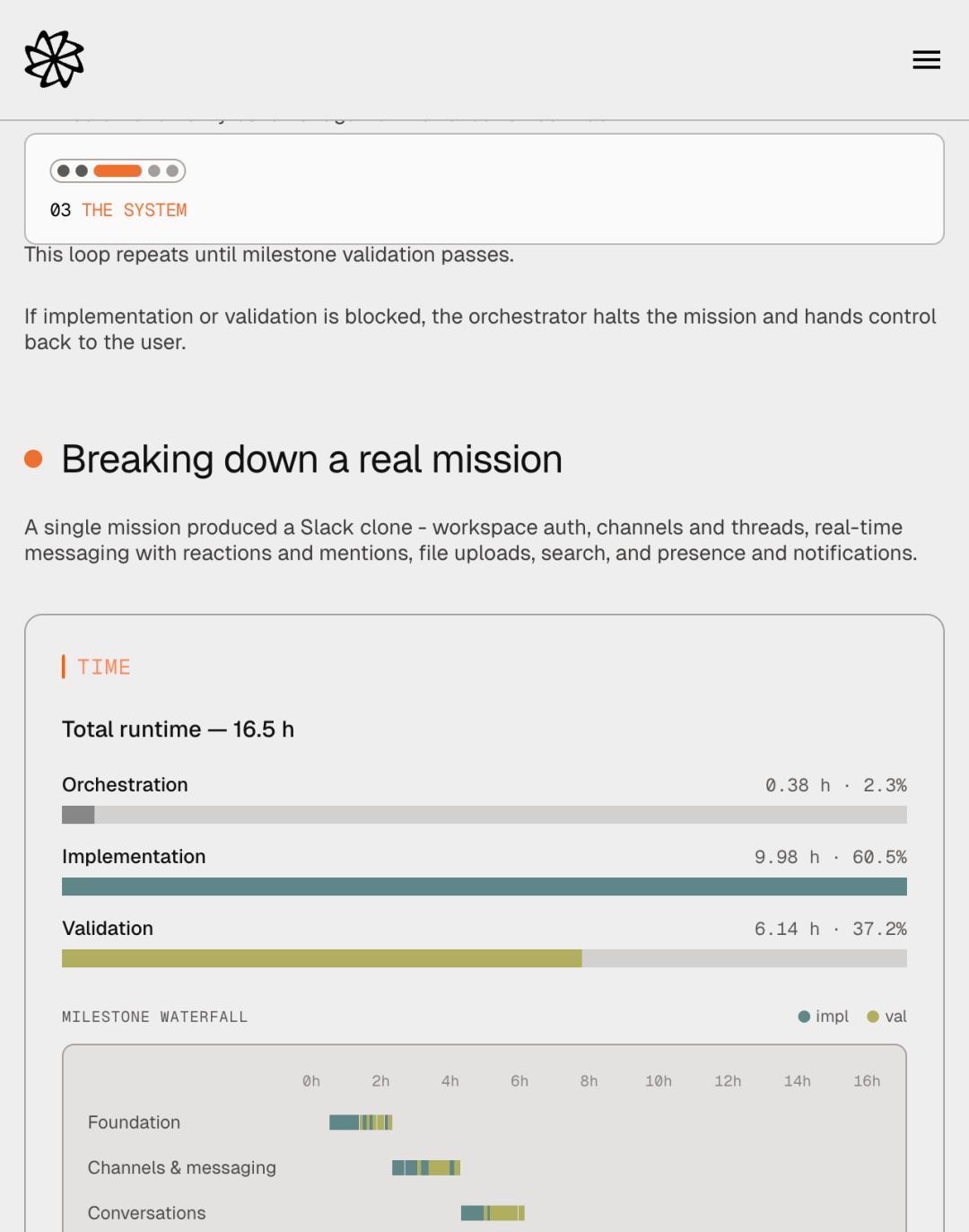
读这张表最值得停下来的两行是 Fix features 21(34.4%) 和 验证一轮从未通过。这两个数字一起说明 Missions 在质量上的真正机制:不是追求一次性写对,而是追求 validator 能在每一轮稳定地找出缺口,然后让 orchestrator 把缺口变成下一轮的工作项。这是和单 agent coding 在哲学上的彻底分水岭——前者把「迭代修复」从异常路径搬到主路径,后者依然把它当成 agent「犯错」。
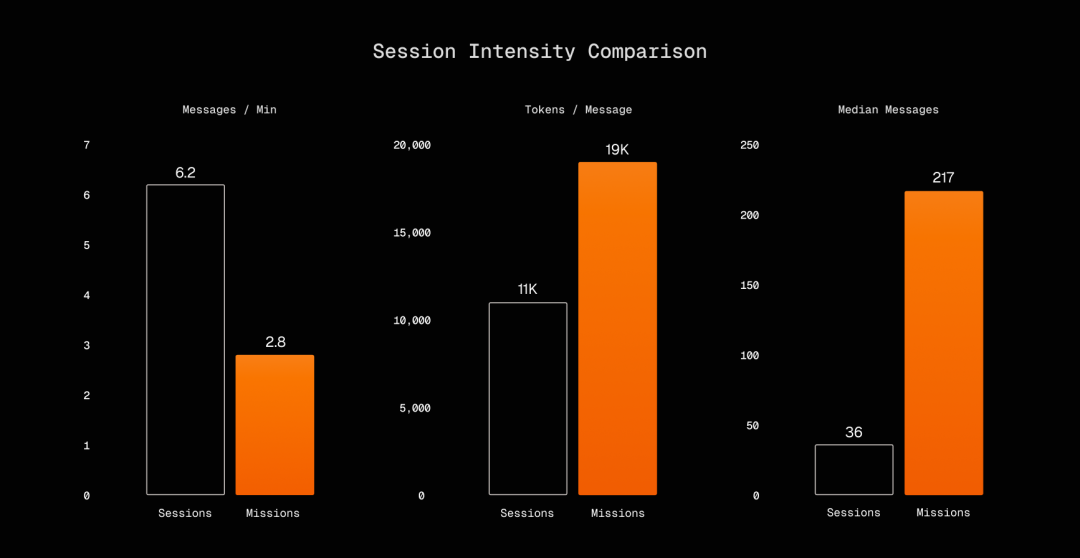
跟 Factory 之前发布的 session 强度分布数据放在一起看会更清楚。普通 Droid session 的中位时长 8 分钟,60% 在 15 分钟内结束;mission 的中位时长 2 小时,65% 超过 1 小时,14% 超过 24 小时,最长 16 天。token 消耗也呈现完全不同的形态:mission 的 token burn rate 和普通 session 接近(约 45K tokens/min),但 mission 能把这个速率持续几个小时甚至几天。
十一、Mission Control 在 multi-agent 战场里的位置
Mission Control 不是 Factory 第一个做「多 agent 控制面」的尝试。Claude Code 的 Agent Teams、Qoder 的专家团模式也都在往这个方向走,只是切入点不同。Claude Code 做得更通用:它更像一组可以互相协作的 Claude 会话,靠 mailbox、共享 task list 和 lead/peer 互检来推进任务。Qoder 的专家团则更像工程团队流水线,Team Lead 先拆需求,再拉前端、后端、QA、代码评审等专家角色并行交付;它在工程知识切片、专家分工和验证回路上也有不少自己的思考。
Factory 的分歧在这里变得清楚:Mission Control 的形态不是通用会话网络,也不是按工程角色组出来的专家团,而是项目编排控制面。orchestrator 在中间统一调度,worker/validator 是它的下手,人类作为项目经理通过 orchestrator 介入。它关心的不是「多开几个 agent 窗口」,而是让一个长任务在几小时甚至几天里持续推进,并且每一步都能被外部状态和验证契约接住。
这三种形态最大的差异在「state 在哪里」。Mission Control 的 state 在 git 和共享 markdown 里,validation 是中心化的 gate;Agent Teams 的 state 在每个 teammate 的对话窗口里,validation 靠 lead/peer 互检;Experts Mode 的 state 在 Team Lead 的 plan 里,validation 靠 QA/Review 专家角色并行触发。Mission Control 选了最重的那条路:state 必须外化,agent 不许长期记忆。这是它能跑 16 天的原因,也是它牺牲灵活性的代价。
另一条值得拎出来的对比:Mission Control 故意不做 direct communication。当一个 worker 发现需要另一个 worker 已经写好的工具,它不能直接问那个 worker,它只能读 handoff summary 和 git history。这看起来低效,但它保证了一件事——任何时候 mission 的状态都可以被人类完整理解。Agent Teams 的 mailbox 在 demo 里很酷,但当某个 teammate 在 1 小时前的对话里做了一个决定,2 小时后没有人能轻易回溯它对其它 teammate 的影响。Mission Control 用 PMO 般的笨重换的就是这种 legibility。
十二、Bitter Lesson 反驳:为什么这套架构不会被下一代模型革命掉
这场演讲里最值得反复看的可能是结尾的反驳部分。一个流行的 AI 行业观点是:所有 multi-agent 架构都会被下一代基础模型 obsolete 掉——模型变强后,单 agent 就够用,多 agent 都是过渡期产物。Alvoeiro 给出的反论是:Missions 是为模型变强而设计的,不是为了对冲模型不够强而设计的。
理由有三层。一是 orchestration 逻辑写在 prompt 里:模型变好,规划质量直接提高,不需要重写 graph。二是 separation of concerns 让 model specialization 收益直接显现:模型越分化,”把最对的模型放到最对的角色”的红利越大;如果未来出现一个超擅长 user testing 的小模型,Missions 可以马上替换 user-testing validator 而不动任何其它部分。三是 validation contract 是为人类需求建模的,不是为某种模型建模的——契约本身在模型更新过程中是稳定的。
Factory 在 Introducing Missions 里把这个判断写成了一段冷静的话:「锁死在单一模型家族的系统永远被这家最弱的能力约束。model-agnostic 的 orchestrator 能把每个角色都装上当前最适合的模型,并在 landscape 变化时随时替换」。这等于在赌一件事:模型会持续 speciate(分化),而不是收敛到一个 super-model。如果这个判断成立,Missions 这种架构的 ROI 会随时间复利地变高;如果不成立,它会变成历史展品。这是 2026 年中场赛季最大的几个押注之一。
十三、能从 Missions 抄哪些设计原则
如果你自己在搭多 agent 系统,这场演讲里至少有 5 条可以直接照抄的设计原则。它们不依赖 Factory 的代码,也不依赖 Droid 这个 harness——它们是可以从架构层落到任何 agent 框架(LangGraph、CrewAI、AutoGen 或者你自己的)的。
1.角色责任明文化。在写第一行 agent 代码前,先用一页纸把 orchestrator / worker / validator 各自「不许做什么」写下来。比”能做什么”更重要。2.验收标准前置。在 planning 阶段产出 validation contract(行为断言列表),用它驱动 feature 拆分。生成 contract 的 agent 必须和评估 contract 的 agent 不同。3.结构化 handoff 取代记忆。每个 worker 完成时必须填 completed / not_completed / commands_executed / issues_found / procedure_compliance 五个字段。下一个 worker 读这份文档,不读上一个 worker 的对话历史。4.写串行、读并行。文件写入、commit、validator 评估这些 mutate state 的操作严格串行;codebase search、文档调研、code review 这些 read-only 操作可以并行。5.让验证用不同的模型。哪怕只是把 validator 换成另一家提供商的中等规模模型,就能避开同家族训练数据 bias 带来的 false negative。
十四、参考资料
•Multi-Agent Systems / Missions: Multi-Agent Systems That Ship for Days — Luke Alvoeiro, Factory(YouTube, 2026-05-06)[1]•How Missions Work — Theo Luan, Factory(2026-04-10)[2]•Introducing Missions — Factory(2025-02-26,2026 数据更新版)[3]•Factory CLI Missions 文档[4]•Luke Alvoeiro: The Bottleneck in Coding Is No Longer AI — It’s Human Attention(BigGo Finance)[5]•Missions: AI Agents That Ship for Days(StartupHub.ai)[6]•Missions: Multi-Agent Systems That Ship for Days(Frontier Models)[7]•マルチエージェント設計の 7 原則(Zenn 日译版)[8]•Qoder 专家团模式相关解读
References
[1] Multi-Agent Systems / Missions: Multi-Agent Systems That Ship for Days — Luke Alvoeiro, Factory(YouTube, 2026-05-06):https://www.youtube.com/watch?v=ow1we5PzK-o[2]How Missions Work — Theo Luan, Factory(2026-04-10):https://factory.ai/news/missions-architecture[3]Introducing Missions — Factory(2025-02-26,2026 数据更新版):https://factory.ai/news/missions[4]Factory CLI Missions 文档:https://docs.factory.ai/cli/features/missions[5]Luke Alvoeiro: The Bottleneck in Coding Is No Longer AI — It’s Human Attention(BigGo Finance):https://finance.biggo.com/news/9ef5dbb40c870730[6]Missions: AI Agents That Ship for Days(StartupHub.ai):https://www.startuphub.ai/ai-news/artificial-intelligence/2026/missions-ai-agents-that-ship-for-days[7]Missions: Multi-Agent Systems That Ship for Days(Frontier Models):https://frontiermodels.cc/video/missions-multi-agent-systems-that-ship-for-days-luke-alvoeiro-factory/[8]マルチエージェント設計の 7 原則(Zenn 日译版): https://zenn.dev/aerign/articles/916513f6e96e7e
💬 本文评论区已开启,但暂无读者留言。
本文转载自微信公众号,如有侵权请联系删除。
- 标题: 一个 Mission 跑 16 天、烧 7.78 亿 Token:Factory 公开了多 Agent 系统的构建哲学
- 作者: lxiol
- 创建于 : 2026-05-18 13:18:35
- 更新于 : 2026-05-18 13:18:35
- 链接: https://blog.lxiol.cn/2026/05/18/一个-Mission-跑-16-天烧-778-亿-TokenFactory-公开了多-Agent-系统的构建哲学/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。