还在用 70B 模型做文档分析?NVIDIA 开源了这个 30B 全模态小钢炮,效率碾压竞品
NVIDIA Nemotron 3 Nano Omni 一个模型搞定文档、图片、视频、音频、GUI 交互。30B 参数只有 3B 活跃,RTX 4090 就能跑 BF16。
NVIDIA Nemotron 3 Nano Omni 是一个开源全模态理解模型,30B-A3B 架构(总参数 30B,活跃参数仅 3B),一个模型同时处理文本、图片、视频、音频和 GUI 交互。
项目地址:https://huggingface.co/collections/nvidia/nemotron-3-nano-omni-68053b0e5e3b3a0001014c02
技术报告:https://arxiv.org/abs/2604.24954
为什么这件事值得关注
如果你是一个需要处理多模态任务的工程师,你的工具箱大概是这样的:
- • 文档/图片理解:用一个视觉-语言模型
- • 语音识别:接 Whisper 或同类 ASR
- • 视频分析:再套一个视频模型
- • GUI 自动化:另起一套 Screen Agent
四套管线、四种依赖、四份显存开销。 每次升级模型,每个管线都要跟着动。
NVIDIA 这次开源的 Nemotron 3 Nano Omni 的思路很直接:把上面这些能力打包进一个模型。而且不是那种”啥都会但啥都不精”的缝合怪 — 它在多个公开基准上拿到了 SOTA 或接近 SOTA 的成绩。
核心能力一览
Nemotron 3 Nano Omni 主打五类工作负载:
- • 长文档分析 — 处理 100+ 页的合同、技术报告、合规材料,支持跨页表格和公式理解
- • 语音识别 — 多口音、多说话人、背景噪声下的高质量转录
- • 长音视频理解 — 屏幕录制、培训视频、会议录播,联合分析画面和声音
- • GUI 智能体 — 看懂屏幕截图,辅助界面操作选择和工作流自动化
- • 多模态推理 — 跨文本、图片、表格的多步推理和计算
架构拆解:Mamba + MoE + Transformer 的混合体
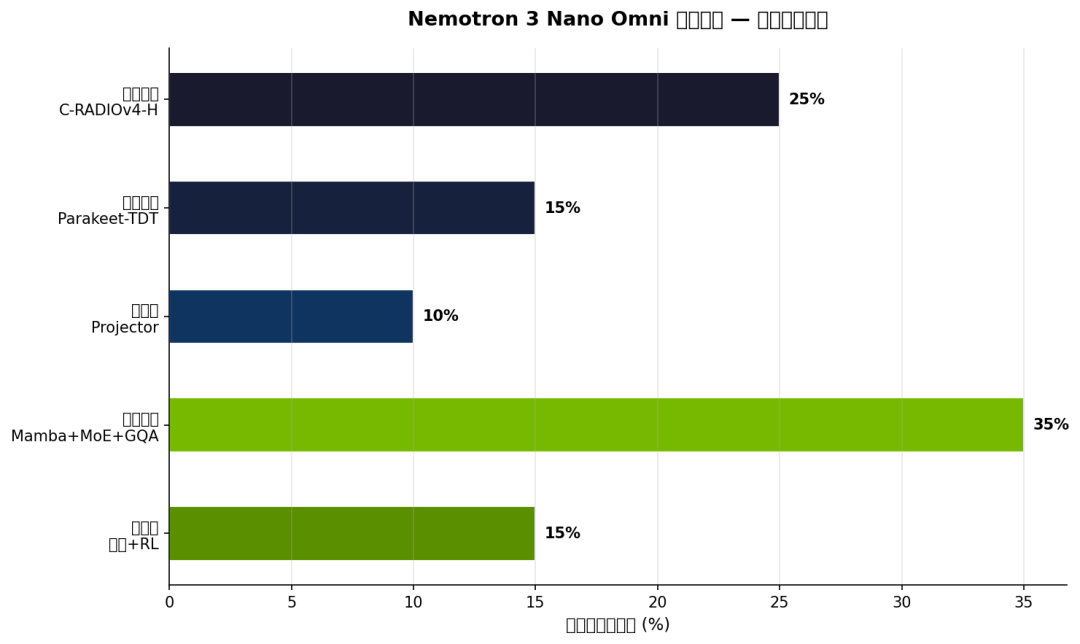
上图展示了 Nemotron 3 Nano Omni 各模块在整体架构中的相对重要性。它的设计有几个关键看点。
混合骨干:为什么不是纯 Transformer?
语言骨干用了三种组件交替堆叠:
- • 23 层 Mamba(选择性状态空间) — 擅长高效处理超长上下文,复杂度线性增长
- • 23 层 MoE(混合专家,128 个专家,top-6 路由) — 用条件计算放大有效参数
- • 6 层 GQA(分组查询注意力) — 保证全局交互和推理质量
这个组合的直接收益是:在保持 Transformer 级别推理能力的同时,把长上下文的计算复杂度从二次降到了线性。
对于处理 100+ 页文档或长视频场景,这个选择是决定性的。
视觉编码:动态分辨率替代固定分块
以前的视觉-语言模型处理大图时,通常把图片切成固定大小的 patch 网格(tiling)。问题是:
- • 切得太粗 → 丢失细节(小字号、细线条、密集表格)
- • 切得太细 → token 爆炸,上下文窗口不够用
Nemotron 的方案是动态分辨率:每张图片用 1,024 到 13,312 个视觉 patch 表示,根据内容密度自适应。相当于模型自己决定”这张图需要看多细”。
视频编码:Conv3D + EVS 双管齐下
视频理解最大的瓶颈是 token 数量。如果每帧独立编码,一分钟 30fps 就是 1,800 帧。
Nemotron 用了两层优化:
- • Conv3D tubelet embedding — 把相邻两帧融合成一个 tubelet,视觉 token 直接减半
- • EVS(Efficient Video Sampling) — 推理时自动丢弃静态帧的冗余 token,只保留动态变化的部分
音频编码:原生音频理解,不是 ASR + LLM
和”先转文字再给 LLM”的传统路线不同,Nemotron 用了 Parakeet-TDT-0.6B-v2 音频编码器,直接提取音频的语义特征。这意味着模型能理解语调、情绪、说话人切换等纯文本丢失的信息。
数据对比:跑分说话
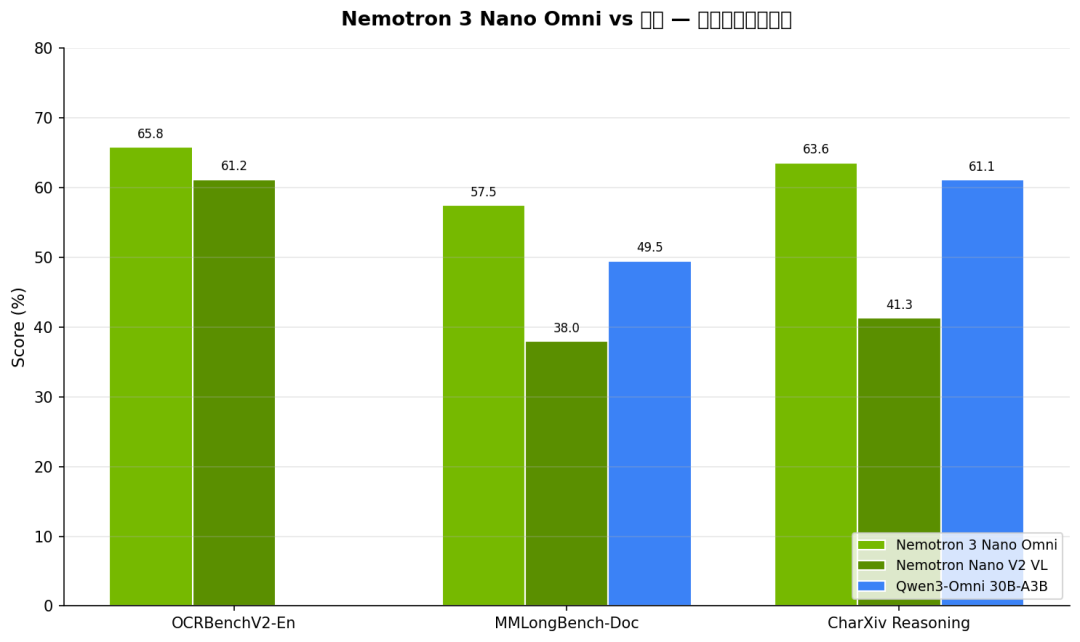
上图对比了 Nemotron 3 Nano Omni、上一代 Nano V2 VL、以及 Qwen3-Omni 30B-A3B 在三个文档理解基准上的表现。几个关键数据:
- • OCRBenchV2-En:65.8 vs 61.2(上一代),提升 4.6 分
- • MMLongBench-Doc:57.5 vs 38.0(上一代),暴涨 19.5 分 — 这说明长上下文能力不是微调出来的,而是架构级改进
- • CharXiv Reasoning:63.6 vs 41.3(上一代),图表推理能力大幅提升
注意 Qwen3-Omni 在 OCRBenchV2-En 上没有公开成绩,所以那一项为空。
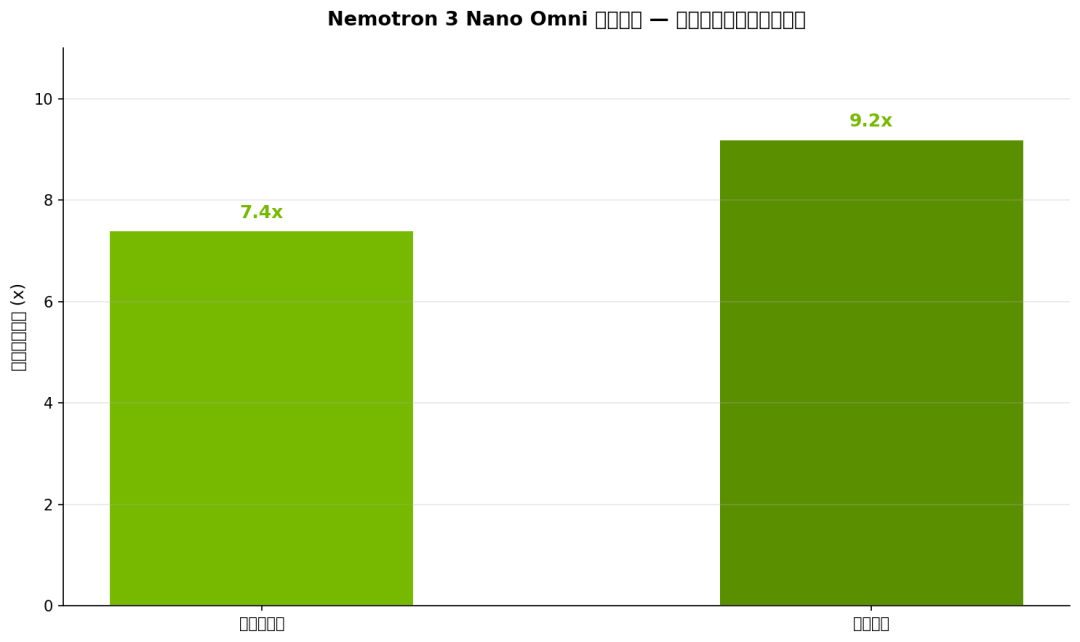
上图是系统吞吐量对比(在相同每用户交互性阈值下,单位 tokens/sec/user):
- • 多文档场景:Nemotron 比其他开源全模态模型高 7.4 倍
- • 视频场景:高 9.2 倍
这是 Conv3D 压缩 + EVS 动态采样 + MoE 条件计算叠加的效果。
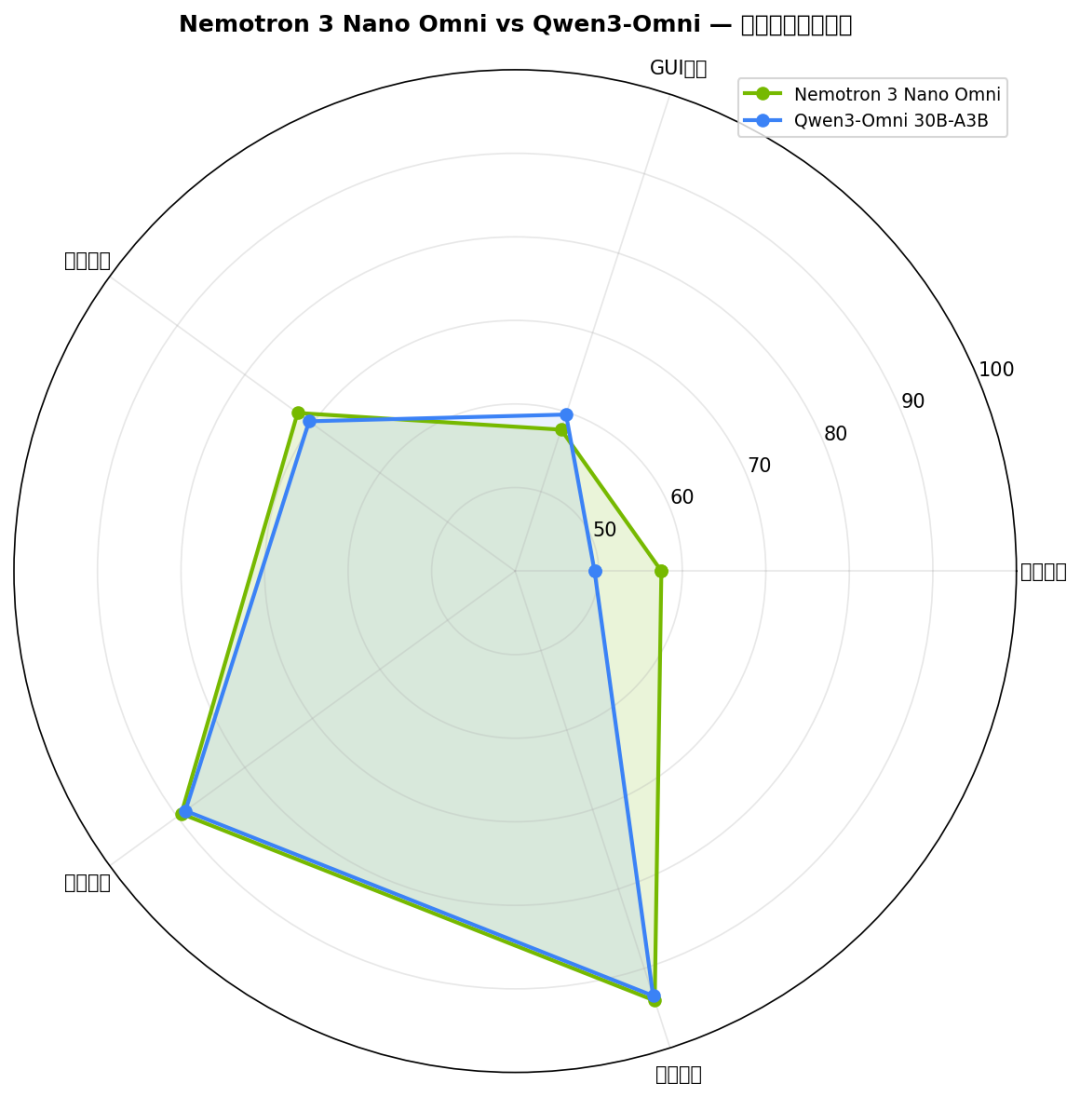
雷达图展示了五个维度的综合能力对比。Nemotron 在 文档理解(MMLongBench-Doc 57.5 vs 49.5)和 GUI 交互(OSWorld 47.4 vs 29.0)上的优势最为突出。
怎么用:快速上手指南
最小可用示例
1 | `# 安装依赖 |
1 | `from transformers import AutoModelForCausalLM, AutoProcessor |
视频 + 音频联合分析
1 | `messages = [ |
量化版本选型
NVIDIA 提供了三个精度版本的 checkpoint:
版本显存需求精度损失推荐场景BF1660GB无生产环境,追求最高精度FP830GB极小单卡 A100/H100NVFP4~15GB可接受消费级显卡、边缘部署
1 | `# FP8 版本 |
关键结论
适合的场景:
- • 需要同时处理 文档 + 语音 + 视频 的流水线,想用一个模型替代多模型拼凑
- • 长文档(100+ 页)分析,尤其是合同、技术报告、合规材料
- • 会议录、培训视频的自动摘要
- • 想要 开源可商用 的全模态模型
不建议的场景:
- • 只需要纯文本对话 → 用更小的纯文本模型更经济
- • 对延迟极度敏感的实时场景(如直播字幕)→ 专用 ASR 更低延迟
- • 需要极高质量的专业 OCR → 传统 OCR + LLM 的管线仍然有优势
写在最后
Nemotron 3 Nano Omni 代表了 NVIDIA 在 开源多模态基础设施 上的持续投入。从纯文本的 Nemotron Nano,到视觉-语言的 V2 VL,再到今天的全模态 Omni — 这条产品线的迭代节奏和开放程度,值得持续关注。
我个人最看好的是动态分辨率 + EVS 这套组合拳 — 它解决的不是”模型聪不聪明”的问题,而是”模型能不能处理真实世界的数据量”的问题。这才是工程落地最关键的门槛。
下一步我打算实测一下 NVFP4 版本在消费级显卡上的表现,如果效果不错会单独写一篇部署指南。
参考来源:NVIDIA Nemotron 3 Nano Omni 官方博客、技术报告 (arXiv:2604.24954)、HuggingFace 模型页面
💬 本文评论区已开启,但暂无读者留言。
本文转载自微信公众号,如有侵权请联系删除。
- 标题: 还在用 70B 模型做文档分析?NVIDIA 开源了这个 30B 全模态小钢炮,效率碾压竞品
- 作者: lxiol
- 创建于 : 2026-05-18 13:00:27
- 更新于 : 2026-05-18 13:00:27
- 链接: https://blog.lxiol.cn/2026/05/18/还在用-70B-模型做文档分析NVIDIA-开源了这个-30B-全模态小钢炮效率碾压竞品/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。