Multica 让人人都可以成为项目经理
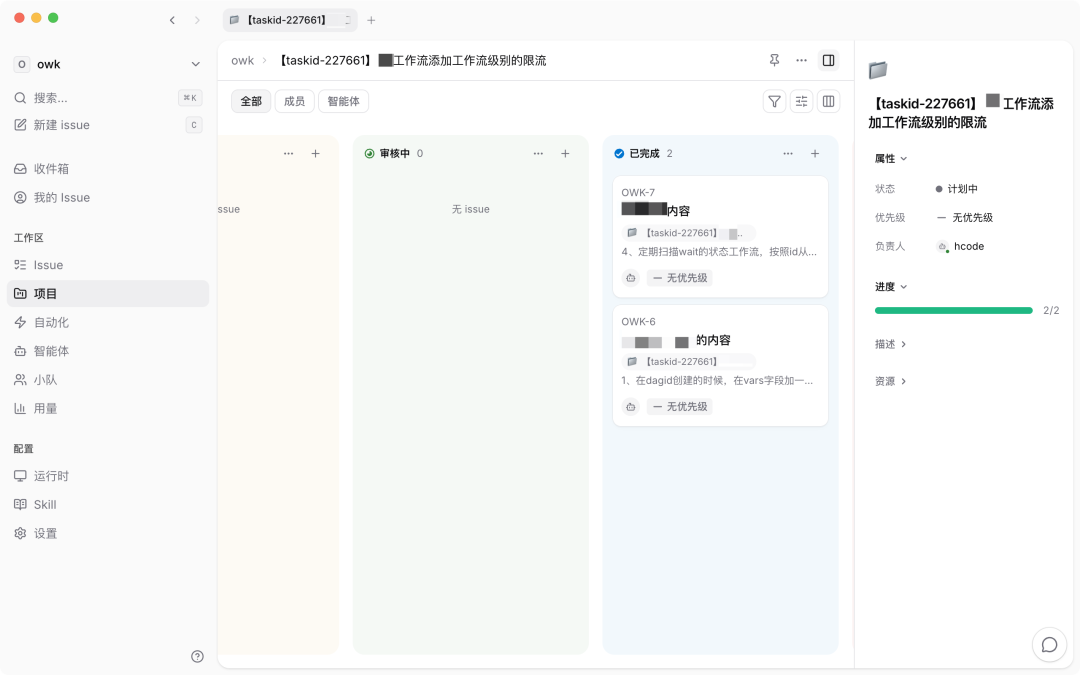
给任务级别做限流。我在 Multica 里下了这么一条需求,然后去倒咖啡。回来的时候,它已经完成了
给任务级别做限流。
我在 Multica 里下了这么一条需求,然后去倒咖啡。
回来的时候,它已经拆成了两个 issue——一个改底层框架,加了限流中间件;一个改业务服务,接入了中间件的配置 API。两个 Agent 各自在各自的仓库里提交了代码。
全程没有人类参与。
起因
我的项目有三个微服务仓库:一个业务服务、一个底层框架、一个交互协议。以前全靠一个 Hermes Agent 干所有活,Agent 本身没问题,问题出在我身上。
每次来一个跨仓库的需求,我得自己想清楚该改哪个仓库、怎么拆、先改谁后改谁,然后手动切目录——先切到框架仓库改底层逻辑,再切到服务仓库接入上层配置,中间还得来回确认接口对不对得上。三个仓库来回切,光切目录和捋上下文就耗掉大半精力,真正写代码的时间反而不多。
最烦的是那种只改一个仓库不够,但改两个仓库又得自己协调顺序的需求——改框架之前得先想好服务那边怎么接,改服务之前又得先确认框架那边留了什么口子。
我不是在写代码,我是在当项目经理。 而 Agent 只是个听指令干活的程序员——你不说,它不会自己拆。
思路
后来我想明白了。真实团队里,一个跨模块需求怎么落地的?
产品经理接到需求,判断涉及哪些模块,然后给后端组派一个任务、给中间件组派一个任务。各组只管自己那块,接口对齐靠约定,不靠一个人在脑子里记所有事。
那为什么不让 AI 也这么干?
我的三个仓库,本来就对应三种职责。业务服务的人不该去动底层框架的代码,底层框架的人也不该碰业务服务的配置——这是团队里的基本规矩。现在只是把这个规矩也应用到 Agent 身上:每个 Agent 只负责自己的模块,拿到自己的任务,改自己的代码。
一个项目,一个 Agent
Hermes 有个 Profiles 功能,可以在同一台机器上跑多个独立的 Agent,每个有自己的配置、记忆、技能——就像同一家公司里不同岗位的员工,用各自的电脑,登录各自的账号。详情可以看我之前公众号的文章
先配好一个基座,再从基座克隆出三个工作 Agent:
-
-
-
-
1 | `hermes profile create hcode # 基座``hermes profile create svc-service --clone-from hcode --clone-all``hermes profile create svc-framework --clone-from hcode --clone-all``hermes profile create svc-protocol --clone-from hcode --clone-all` |
每个 Agent 绑定各自的项目目录,进聊天就直奔自己的仓库:
-
-
-
1 | `svc-service chat # 进入业务服务``svc-framework chat # 进入底层框架``svc-protocol chat # 进入交互协议` |
从这一刻起,svc-service 不知道底层框架的代码长什么样,svc-framework 也不知道业务服务的路由表。它们各自只看见自己的仓库——就像后端工程师不会去看前端的组件目录,不是不能看,是不需要看。
Multica 当 PM
Agent 有了,但它们得协作。谁来拆需求、分任务?
我把 Multica 当 PM 用。
Multica 支持 Hermes 的方式是通过 -p 参数指定 Profile。也就是说,每个 Multica Agent 启动时带上自己的 Profile 名,就自动绑定了独立的记忆、配置和工作目录。我在 Multica 里创建四个 Agent,每个都指定各自的 Profile:
- hcode:技术负责人,负责拆需求、派任务
- svc-service:业务服务程序员
- svc-framework:底层框架程序员
- svc-protocol:交互协议程序员
我在 Multica 里给 hcode 下需求,它判断涉及哪些仓库,然后给对应的 Agent 派 issue。各 Agent 拿到 issue 开始干活,干完了 hcode 汇总验证。我只需要提需求,不用拆任务,不用切目录,不用协调顺序。
目前 Multica 还没有做 Profile 选择器 UI,只能通过 -p 手动指定。但已经够用了——我的四个 Agent 就是这么跑起来的。Feature Request Multica表示也会合入这个Feature
开头那个给任务级别做限流的需求,就是这么跑通的。hcode 判断限流需要两层支撑,底层框架加检查点,业务服务加配置 API。然后各干各的,互不干扰。
以前我是项目经理兼程序员,现在 Multica 当 PM,我只管提需求。
记忆系统
分工容易,难的是记忆。
三个 Agent 需要共享一些知识——比如不能加新表,用缓存替代这种全局约定,或者接口走 v2 版本,不走 v1这种跨模块规则。如果每个 Agent 各记各的,队长今天定下来的约定,队员明天还不知道。
但它们又不能什么都共享——底层框架的线程池参数、业务服务的状态机定义、交互协议的消息格式,这些是各自的私有经验。就像团队里,架构决策谁都知道,但你自己模块踩过的坑,别人不需要知道——知道了反而可能误用。
共享太少,Agent 会犯全局性的错;共享太多,Agent 会犯局部性的错。
好在 Holographic 的实现比这个概念简单得多。它本质上就是一个 SQLite 文件,db_path 可以随便指。所有 Profile 指向同一个 db,共享记忆就天然实现了:
-
-
-
1 | `plugins:``hermes-memory-store:``db_path: /path/to/shared/memory_store.db` |
hcode 今天记住的公共约定,svc-service 下一次查就能查到。不需要同步,不需要广播。至于谁往里面写什么——队长负责沉淀公共事实,各 Agent 只追加自己模块的特性事实。Holographic 的 contradict 兜底:如果某个 Agent 写了一条和公共约定矛盾的事实,矛盾会被自动发现。
同一个大脑,但各自的经验不串。 像团队里的知识库——技术规范谁都查得到,但每个人只往自己负责的板块里写东西。
还在实验中
这个方案目前有两个明显的坑。
第一,Token 烧得快。 队长拆解一个需求就要 3000 token,还不算各 Agent 执行代码的消耗。相比直接告诉 Agent 改这里,额外开销大约 2-3 倍。本质上是为”分工”付出的协调成本——就像团队里的沟通开销,比一个人闷头干总是贵的。
第二,信息是割裂的。 三个 Agent 并行干活,进度散在各自的 Multica 面板里,你得分别点进去看。没有统一的看板展示小队的整体进展。就像你带了个三人小组,但没有站会、没有白板,每个人只在自己的工位上默默推进。
都是工程问题,不是架构问题。方向没错,工具链还不够顺。
不是多开,是分工
回头看,给每个微服务配一个 Agent听起来像是多开了几个实例,但本质上跟多开没关系。
多开是同一个 Agent 跑三份,干一样的活。我做的事是让三个 Agent 各管各的,干不一样的活——就像团队里不会让三个全栈工程师各自把前后端都改一遍,而是后端改后端的、前端改前端的,接口对齐靠约定。
那个队长自动拆任务、Agent 各改各的仓库、改完自动提交的瞬间,让我看到了 AI 辅助编程的下一个形态:不是一个人带着一个 AI 干活,而是一个人指挥一支 AI 小队。
你不需要 AI 更聪明,你需要 AI 更像团队。
- END -
💬 本文评论区已开启,但暂无读者留言。
本文转载自微信公众号,如有侵权请联系删除。
- 标题: Multica 让人人都可以成为项目经理
- 作者: lxiol
- 创建于 : 2026-05-21 19:36:27
- 更新于 : 2026-05-21 19:36:27
- 链接: https://blog.lxiol.cn/2026/05/21/Multica-让人人都可以成为项目经理/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。