Hermes 的浏览器工具,也该换一层了
副标题:从 TinyFish、Kimi 网桥、OpenCLI 到 CloakBrowser,我越来越觉得 Hermes 正在靠近真正的 CUA。

这几天我继续折腾 Hermes 的情报层。
前面我写过 TinyFish。
我把 Hermes 的搜索和抓取换成 TinyFish 后,才发现 Agent 的情报层有多重要
那一轮主要解决的是 Search / Fetch。
也就是把 Hermes 的搜索和网页抓取链路,从原来默认能力,换成更适合 Agent 使用的外部情报入口。
但这次不一样。
这次我替换的不是 web 搜索。
也不是普通 fetch。
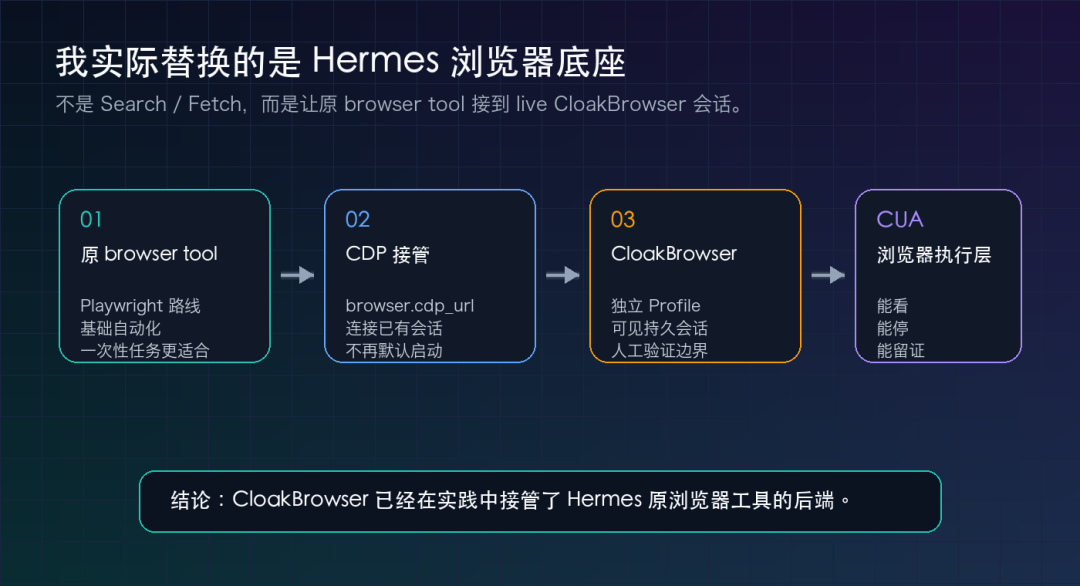
而是 Hermes 自带的浏览器自动化工具。
也就是那个偏 Playwright 路线的 browser tool。
它能打开页面、点按钮、读内容。
CloakBrowser 吸引我的地方,不是它名字里的“隐身”,而是它不像普通 Playwright 那样只在上层做伪装。它的思路更底层:基于定制 Chromium,把浏览器指纹、自动化痕迹和人类操作节奏这些问题放到浏览器执行层处理。
对我来说,更关键的是它能承接一个已经登录、已经验证过的浏览器状态。很多没有稳定 API 的网站,真正难点不是“能不能请求到页面”,而是登录态、风控、动态渲染和人工验证。CloakBrowser 的 persistent profile、可见窗口和 CDP 连接方式,让 Hermes 可以接到一个长期存在的浏览器会话后面继续工作。
这比 Kimi 网桥又往前走了一步。Kimi 网桥让我看到“Agent 可以连接真实浏览器”,而 CloakBrowser 更像是把这个浏览器变成一个可长期驻留、可人工接管、可复用登录状态的执行层。人负责登录和验证,Agent 负责低频、只读、可复核的观察和操作。
所以我选择它,不是为了“自动绕过一切风控”,而是因为它更接近我想要的 CUA 工作台:能看真实页面,能接住登录态,能在没有稳定 API 的网站上,尽量用更接近真实浏览器的方式完成信息获取。
更准确地说,我已经在私有常驻环境里,把 Hermes 默认 browser tool 的后端接到了 CloakBrowser。
这不是另起一个完全无关的脚本。
而是让 Hermes 原来的 browser_navigate、browser_click、browser_snapshot、browser_console 这些工具,走一个 live CloakBrowser 会话。
这件事比“我研究了一个新浏览器项目”重要得多。
我现在越来越觉得:
Hermes 下一步要换的,不只是搜索和抓取,而是默认浏览器工具背后的执行层。
记忆层解决过去。
情报层解决现在。
过去的偏好、规则、经验,可以沉到 memory 里。
但今天网页变成什么样、某个平台是不是弹验证、某个页面真实状态是什么,这些不能靠记忆,也不能只靠 Search / Fetch。
它必须现场看。
而且要用一个更接近真实浏览器环境的方式看。
01|原来的情报层,主要换的是 Search / Fetch
我之前讲 TinyFish 时,说的是 Hermes 情报层。
但那一层更准确地说,是外部信息入口。
Search 负责找页面。
Fetch 负责把页面内容抓下来。
这已经很重要。
因为 Agent 做研究、写报告、查资料,如果搜索慢、抓取不稳,后面的推理再强也没用。
但 Search / Fetch 解决不了所有问题。
它解决的是“网页内容能不能被拿下来”。
它不解决“真实浏览器里发生了什么”。
比如:
- 登录态是否还在;
- 页面是否弹了验证;
- 点击后进入的是详情页还是预览层;
- 评论是否折叠;
- 前端是否动态加载;
- 当前页面是否只显示了一部分内容。
这些不是普通 Search / Fetch 的强项。
所以我现在把 Hermes 的情报层拆成两段:
- 第一段:搜索和抓取;
- 第二段:浏览器执行。
前一段我已经用 TinyFish 重新理解了一遍。
现在这篇讲的是后一段。
也就是:
Hermes 自带浏览器工具,能不能被一个更适合 CUA 的浏览器层替换掉。
现在我的答案更明确了:
可以。至少在我的私有环境里,这条路已经跑起来了。

02|从 Kimi 网桥、OpenCLI,到 CloakBrowser
我不是一上来就想到 CloakBrowser。
前面我先折腾过 Kimi 网桥。
后来又继续摸 OpenCLI。
这些实践让我意识到一件事:
Agent 要真正接近 CUA,不能只靠模型会调用工具。
它还需要一个稳定的浏览器承载层。
这个承载层最好具备几个特点:
- 能保持长期会话;
- 能让人接管登录和验证;
- 能被 Agent 继续连接和操作;
- 能截图、留证、回放;
- 不要和普通浏览器、其他网桥混在一起。
Hermes 自带的浏览器工具更像一个基础自动化能力。
它能用。
但它不是为长期身份会话、中文平台、人工验证和持续情报工作台设计的。
所以我现在才会觉得,CloakBrowser 不只是“值得研究”。
它已经可以作为 Hermes 默认浏览器工具的替换后端来实践。
我现在在私有常驻环境里,已经不是简单试了一下命令。
而是做了两层事情。
第一层,是把 CloakBrowser 作为独立、可见、持久的浏览器会话跑起来。
它有自己的 profile。
有自己的本地连接入口。
和 Kimi 网桥、OpenCLI、普通浏览器隔离。
第二层,是把 Hermes 的默认 browser tool 接到这个会话上。
也就是说,Hermes 仍然调用原来的 browser 工具名。
但背后不再走默认的简单浏览器启动逻辑。
而是通过本地 CDP endpoint 连接到已经跑起来的 CloakBrowser。
这才是我觉得最关键的实践。
因为这不是“旁边多了一个工具”。
这是把 Hermes 原本的浏览器自动化底座换掉了。
同时,我又把它整理成了一套 Hermes browser skill 的操作规则。
这里面有几条规则,我觉得比“能不能打开页面”更关键:
- 优先连接已经存在的浏览器会话,而不是每次重新启动;
- 使用独立 profile,不和普通浏览器、Kimi 网桥、OpenCLI 混在一起;
- 登录、扫码、验证码、账号验证全部交给人处理;
- Agent 默认低频、只读、慢速操作;
- 一旦出现验证、异常登录、风控提示,就停下来;
- 不把 CloakBrowser 宣传成“不会被检测”,只记录实际观察到的状态。
这才是我觉得它有价值的地方。
它不是一个“更酷的浏览器”。
它更像一个可以被 Hermes 接管、但又保留人工边界的浏览器工作台。
我甚至觉得,这比单纯替换 Search / Fetch 更接近 CUA。
因为 Search / Fetch 解决的是信息入口。
而浏览器工作台解决的是:
Agent 能不能在一个真实窗口里,持续、谨慎、有边界地完成观察和操作。
但我不想把它写成“反检测神器”。
这个方向很容易误导。
我真正关心的是:
它能不能替代 Hermes 自带的浏览器自动化工具,成为更接近 CUA 的浏览器前哨。
也就是说,它不是替我自动登录。
不是替我绕过验证。
也不是保证账号永远安全。
它更像一个独立、可见、持久的浏览器环境。
人负责处理登录、扫码、验证这些高风险动作。
Agent 负责后面的低频阅读、截图、归档、结构化和标注不确定性。
这个分工一出来,我对 Agent 浏览器的理解就变了。
它不应该是一次性打开、一次性关闭的工具。
它更像一个长期驻留的浏览器工作台。
我现在更愿意把这层叫“浏览器执行层”。
它上面可以接 Hermes 的任务。
下面可以接真实浏览器会话。
中间则是一套操作纪律:先连接、再观察、必要时等待人、最后留证。
03|我感觉这离真正的 CUA 越来越近了
我说的 CUA,不是简单“让 AI 点鼠标”。
真正有用的 CUA,应该具备三种能力:
第一,能看见真实界面。
不是只读 HTML,也不是只读搜索结果,而是知道当前窗口里真实发生了什么。
第二,能理解边界。
什么时候可以自动操作,什么时候必须停下来等人,什么时候只能只读,什么时候不能继续。
第三,能留下证据。
URL、截图、页面内容、结构化结果、失败原因,都要能回看。
如果 Hermes 能把 browser、memory、task、gateway 串起来,它就不再只是一个聊天框。
它会更像一个本地工作台:
模型负责判断。
新的浏览器层负责看世界。
任务系统负责排队。
记忆层负责沉淀经验。
Gateway 负责路由和边界。
这就是我觉得 Hermes 离真正 CUA 越来越近的原因。
不是因为它多了一个网页工具。
而是因为我已经把原来那层简单浏览器自动化,接到了一个可长期运行、可人工接管、可证据回流的浏览器执行层。
04|另一个没解决的问题:记忆层
不过这里还有一个独立问题。
它不是这次 CloakBrowser 带来的。
而是我之前写 Hermes 记忆层时,就一直没有完全想透的问题。
我之前以为,只要把记忆分层,问题就能解决一大半。
比如用户偏好、项目背景、任务记录、工具经验,不要全混在一个地方。
这个判断现在看仍然对。
但它没有解决所有记忆问题。
真正麻烦的是:
- 什么应该被长期记住;
- 什么只是当前任务的临时状态;
- 什么应该写进项目上下文;
- 什么应该作为历史日志留着,但不要进入模型默认记忆;
- 什么已经过期,应该被删掉或降权。
所以这篇虽然主要讲浏览器工具层,但我还是会把记忆层放在结尾。
因为 Hermes 越接近真正的 CUA,记忆层这个问题就越绕不开。
不是说 CloakBrowser 解决了记忆。
也不是说浏览器层产生的东西都要进 memory。
而是说:
我之前写的记忆层,仍然没有解决 Hermes 所有的记忆问题。
这部分我现在还没有满意答案。
如果你对 Agent 长期记忆、项目记忆、任务记忆怎么分层有更好的思路,欢迎留言。
05|这篇真正想说的
这次研究 CloakBrowser,我最大的收获不是“浏览器更隐身了”。
而是我更清楚地看到:
Agent 的下一步,不是更会回答,而是更会有边界地看世界。
Hermes 如果只有模型,它是聊天框。
如果加上工具,它是助手。
如果加上任务系统,它像工作流。
如果再加上情报层和记忆层,它才开始接近一个真正能长期工作的 Personal AI Stack。
现在浏览器工具替换这条线,我觉得方向越来越清楚。
但记忆层怎么治理,我还在想。
这是上一篇记忆层文章留下的问题,不是这次 CloakBrowser 本身能解决的问题。
如果你也在做 Agent、CUA、浏览器自动化、长期记忆这类东西,欢迎留言聊聊。
我现在很想听听更好的思路。
相关阅读
- 我为什么要搭建自己的 Personal AI Stack
- 【0基础】:别只让AI陪聊,先让它帮你做事
- 我把 Hermes 接进企业微信和飞书后,才发现 Agent 真正难的不是模型
- 我试了 Hermes Kanban,才发现我真正想要的不是任务队列,而是本地 Agent 群组
- 我把 Hermes 的搜索和抓取换成 TinyFish 后,才发现 Agent 的情报层有多重要
- 我花20美金买GoogleAIPro,结果它把ClaudeOpus也塞进来了
互动问题
你现在最希望 AI 记住你的哪类信息?
是写作风格、工作项目、常用资料,还是你每次都懒得重复解释的那些规则?
请关注我,私信或者文章回复告诉我
这里是 KevinAIStack。
持续关注我,我会继续记录两条线:
• 一条给新手看:AI 工具怎么真正进入日常;
• 一条给技术人看:Agent、Gateway、Computer Use、本地部署和 Personal AI Stack 到底怎么搭。
不吹,不黑。
先跑起来,再做判断。
参考与核对
- CloakBrowser GitHub 仓库:https://github.com/CloakHQ/CloakBrowser
- CloakBrowser README:persistent profile、humanize、Playwright/Puppeteer API、Chromium 指纹处理等。
💬 本文评论区已开启,但暂无读者留言。
本文转载自微信公众号,如有侵权请联系删除。
- 标题: Hermes 的浏览器工具,也该换一层了
- 作者: lxiol
- 创建于 : 2026-05-24 16:04:32
- 更新于 : 2026-05-24 16:04:32
- 链接: https://blog.lxiol.cn/2026/05/24/Hermes-的浏览器工具也该换一层了/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。