Qwen 本地部署,一份被严重低估的救命模板
今天聊一个每个本地部署 Qwen 的人迟早会踩的坑 —— 聊天模板
Qwen3.6 MTP加速,本地部署加速1.5倍,驱动 Claude Code
事情是这样的,最近想用 Qwen3.6 跑点 Agent 任务,结果一上手就翻车:在 LM Studio 里偶尔工具调用刚发出去模型就 <|im_end|> 提前收摊,换到 llama.cpp 上 loop.previtem 直接报解析错误,搬到 vLLM 上想跑 Codex 工具发个 developer role 又被官方模板嫌弃……一通操作下来感觉自己不是在用模型,是在调试一个 Jinja 模板
后来才知道,这些不是我用错了,全是 Qwen 官方 jinja chat template 的锅
HuggingFace 上有个叫 froggeric 的老哥实在看不下去,干脆自己 fork 了官方模板,专门治这些病
项目名简单粗暴:Qwen-Fixed-Chat-Templates,目前已经迭代到 v19,专为 Qwen 3.5 和 Qwen 3.6 全系列(27B / 32B / 35B 都包)打造
简介
一句话讲清楚:这是一个 drop-in 直接替换 的 jinja 聊天模板,专修官方版本的渲染错误、KV Cache 失效、token 浪费和 Agent 任务下的致命卡死
❝
直接把官方chat_template.jinja换成 froggeric 这个版本就行,模型权重不用动,量化文件不用重做
经过实测,在以下推理引擎上都能跑:
- LM Studio:右侧面板换 Prompt Template 直接保存
- llama.cpp / koboldcpp:
--jinja --chat-template-file chat_template.jinja - vLLM:替换
tokenizer_config.json里的chat_template字段,配合--tool-call-parser qwen3_coder - MLX / oMLX:覆盖本地模型目录的
chat_template.jinja,启动加--jinja - 任意支持 HuggingFace Jinja 模板的引擎也通吃
官方模板到底有多少坑?
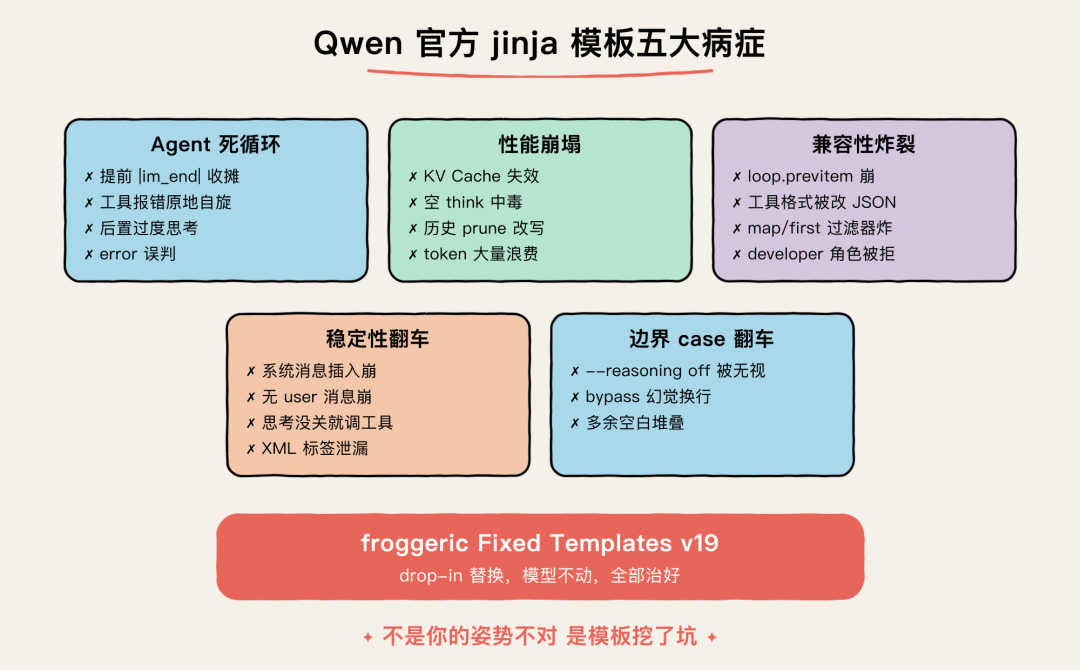
Qwen 官方 jinja 模板五大病症
直接上 froggeric 整理的”罪状表”(v19 视角):
类别
问题
后果
Agent 死循环
提前停机 Bug
模型想边说话边调工具,结果一上头就 `<
Agent 死循环
重试自旋
工具明明报错了,模型还在原地反复发同一个失败的 <tool_call>
Agent 死循环
工具调用后过度思考
拿到数据后陷入”我该不该回答”的内心戏
Agent 死循环
误判错误
返回结果里只要带个 error 字样,立刻误以为工具失败
性能
KV Cache 失效
历史 prune 每轮都改变,整个 prompt 重新算一遍,速度起飞(向下)
性能
“空 think” 中毒
历史里残留一堆空 <think></think>,模型学会”不思考才能用工具”的诡异认知
兼容性
老旧 C++ 引擎崩溃loop.previtem
在老版 llama.cpp / minijinja 上直接挂
兼容性
工具调用格式错
Qwen 训练时用的是 XML 格式 <function=name>,官方模板却给改成 JSON,vLLM 的 qwen3_coder 解析器直接懵
兼容性
Jinja C++ 崩溃
Python 专属过滤器 map、first 在 minijinja 上是一炸一个准
稳定性
对话中插系统消息崩溃
框架想中途插一句 system 指令,模板硬错
稳定性
没用户消息直接崩
纯 Agent loop 或系统消息上下文里 raise_exception 触发
稳定性
思考没关就调工具
XML 标签泄漏到工具解析器
边界 casedeveloper
角色被拒
Claude Code / Codex / OpenCode 现代 API 都用 developer 角色,官方模板不认
边界 case--reasoning off
被忽略
明明关了思考,错误升级路径里又偷偷开了 <think> 块
边界 case
关思考时幻觉 reasoning 标签
Qwen 自己会幻觉出多余的 \n,堆栈空格炸了
v19 改了什么(这是最值得看的部分)
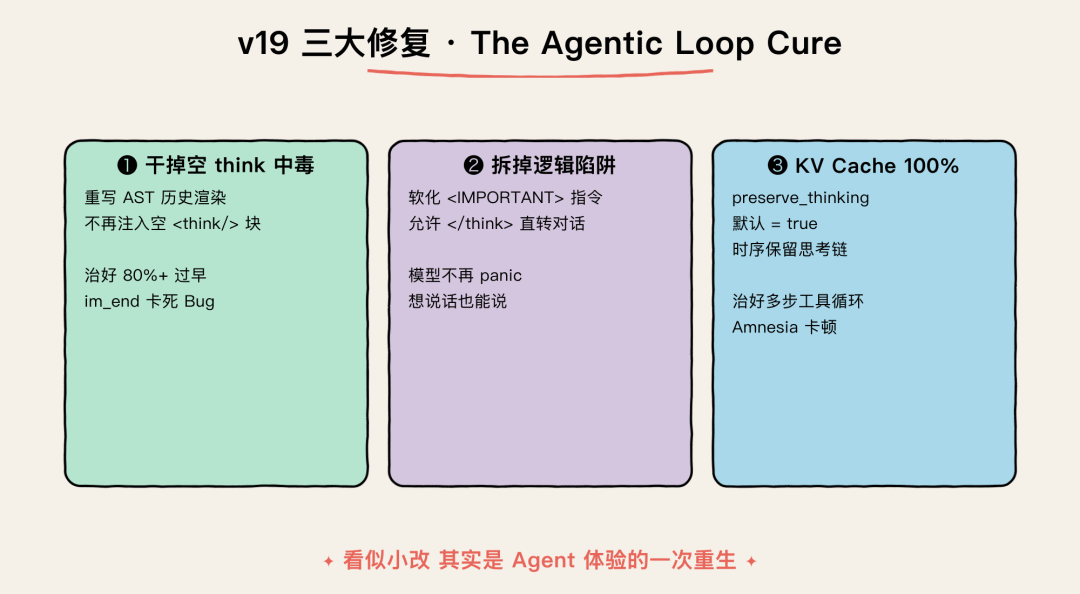
v19 三大修复 · The Agentic Loop Cure
v19(2026-05-18 发布)的核心是 The Agentic Loop Cure,三件大事:
1. 干掉”空 think 中毒”
之前的版本为了省 token,把历史里的 <think> 块清空成空标签,结果模型把”空思考 = 可以调工具”和”完整思考 = 必须接对话”建立了一个错乱的关联,80% 以上的过早收摊 Bug 都来自这个,v19 直接重写 AST 历史渲染,彻底不再注入空 think 块
2. 拆掉系统提示词里的”逻辑陷阱”
老版的 <IMPORTANT> 块里给了一道死命令:”</think> 之后必须调工具”,模型一遇到只想聊天的场景就 panic,v19 改成了 Universal Synthesis 指令,允许模型从 </think> 直接转入对话回复,不必再为这条规则做内心 debate
3. KV Cache 100% 命中 + Amnesia 修复
preserve_thinking 现在默认 true,过去的思考链严格按时序保留,完全治好了多步工具循环里的”失忆卡顿”,同时数学保证 100% Prefix KV Cache 命中率,本地推理速度直接拉满
这一波下来,agent loop 基本可以一气跑完,不再卡在中途乱拐弯
安装方式
按你用的引擎选一个:
LM Studio
1 | `1. 右侧面板打开 Qwen 模型 |
llama.cpp / koboldcpp
1 | `--jinja --chat-template-file chat_template.jinja` |
vLLM
把 tokenizer_config.json 里的 chat_template 字段整段替换成 jinja 文件原文,然后配合 Qwen 原生 XML 工具解析器:
1 | `--tool-call-parser qwen3_coder` |
oMLX
覆盖本地模型目录的 chat_template.jinja,启动时加 --jinja,把所有 chat_template_kwargs 覆盖项删掉,模板内部已全自动处理
❝
Qwen 3.5 / 3.6 全系列(35B / 32B / 27B / 14B)共用同一个chat_template.jinja,不需要分版本
思考模式开关,省钱小妙招
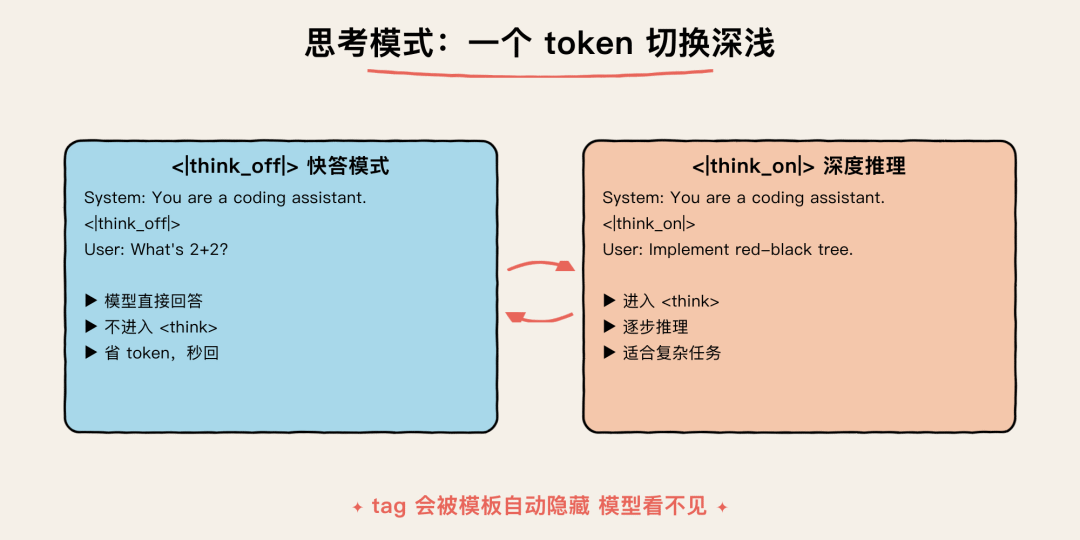
思考模式:一个 token 切换深浅
这套模板还有一个我特别喜欢的功能:思考模式可以在 prompt 里随时切换
直接在 system 或 user 消息里塞一个 control token:
1 | `快速回答,不思考: |
模板会自动拦截这个 tag,从最终上下文里删掉,模型看不到,但模式已经切了
为什么用 <|think_on|> 而不是早期社区流行的 /think?因为 Qwen 控制 token 的 delimiter 绝不会和正常文本或文件路径打架,安全等级高一档
想再省点 token?
v19 默认 preserve_thinking=true,主打 KV Cache 命中率,但如果你显存吃紧、context window 紧张,可以在引擎模板 kwargs 里关掉:
1 | `{ |
代价是多轮对话 KV Cache 命中率会下降(prompt 字符串会动态变化),但能省下一截 context
唯一的小坑:升级到 v19 的时候,preserve_thinking默认改成 true 了,如果你之前自己改过 kwargs,记得对照一下
总结
老实讲,这是那种”看起来不起眼但用过就回不去”的项目,没有花哨的功能,就是把官方挖的坑一个一个填了
适合的人群:
- 用 llama.cpp / LM Studio / vLLM 本地跑 Qwen 3.5 / 3.6 的所有人
- 想跑 Agent / 工具调用 / Coder 任务的开发者
- 被 KV Cache 失效折磨到怀疑硬件的同学
- 用 Claude Code / Codex / OpenCode 接 Qwen 的玩家
唯一的劝退点是:得自己手动替换模板,对纯小白稍微有门槛,但跟着官方 README 一步步来五分钟就能搞定
#Qwen #chat_template #llama.cpp #vLLM #Agent #本地部署
制作不易,如果这篇文章觉得对你有用,可否点个关注。给我个三连击:点赞、转发和在看。若可以再给我加个🌟,谢谢你看我的文章,我们下篇再见!
💬 本文评论区已开启,但暂无读者留言。
本文转载自微信公众号,如有侵权请联系删除。
- 标题: Qwen 本地部署,一份被严重低估的救命模板
- 作者: lxiol
- 创建于 : 2026-05-25 14:52:20
- 更新于 : 2026-05-25 14:52:20
- 链接: https://blog.lxiol.cn/2026/05/25/Qwen-本地部署一份被严重低估的救命模板/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。