—title: 如何把Obsidian Web Clipper价值最大化?
date: 2026-04-27 20:56:02
summary: title: 如何把Obsidian Web Clipper价值最大化。date: 2026-04-27 20:56:02 summary:
tags:
- Obsidian
- AI Agent
- 浏览器
- Git
- 知识库
- 开源
- JavaScript
- LLM
- 阅读原文
- 微信转载
categories: - 转载—
Obsidian用户必备插件
哈喽各位精神股东们,我是蔡蔡!
之前分享了 Karpathy 搭建 AI 知识库的方法,其中简单带过了 Obsidian Web Clipper 这个剪存插件。
🔗:https://github.com/obsidianmd/obsidian-clipper
它本身非常好用,很多网页内容甚至 YouTube 视频字幕都能一键剪存到 Obsidian 中,我在知识星球里就多次分享过。不过它对一些中文内容还不支持,于是我就给它做个中文增强,现在支持B站视频字幕+飞书文档。
🔗:https://github.com/nextcaicai/obsidian-clipper-cn
这篇文章就是分享我是怎么玩转 Obsidian Web Clipper 的,分为两部分:
- 如何“榨干”原版 Obsidian Web Clipper ?
- 如何使用中文增强版 Obsidian Web Clipper ?
一、如何“榨干”原版 Obsidian Web Clipper ?
Obsidian Web Clipper 是 Obsidian 官方推出的浏览器插件,可以让你一键将网页内容保存到 Obsidian 中。
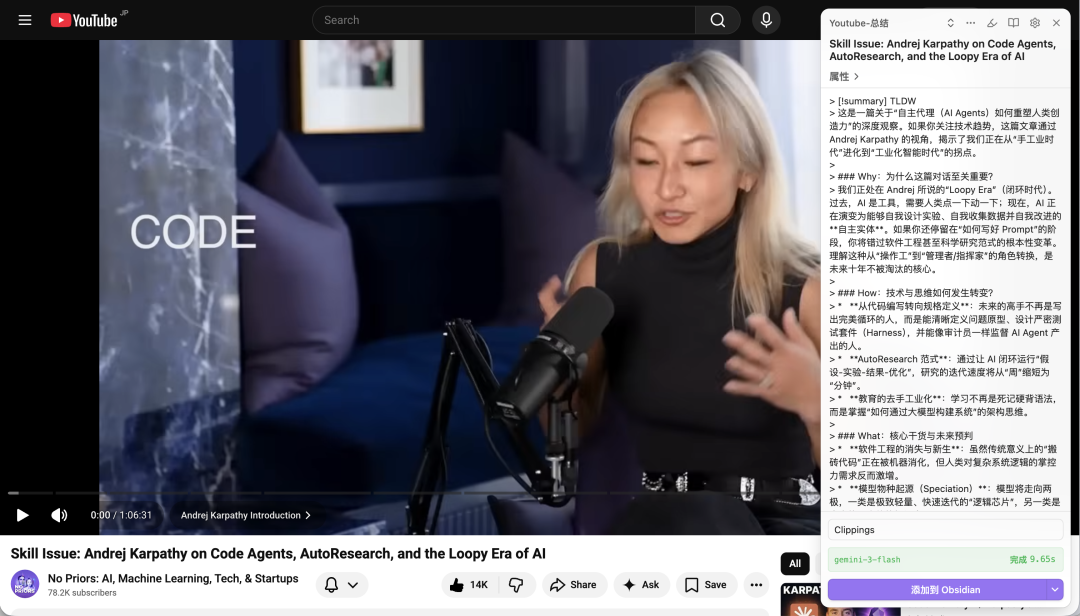
比如我想保存 Anthropic 这篇干货博客,直接唤起 Obsidian Web Clipper 插件,就会看到博客的全部内容都已经在插件面板里了,点击“添加到 Obdsidian”,就可以一键添加到 Obsidian 知识库中。
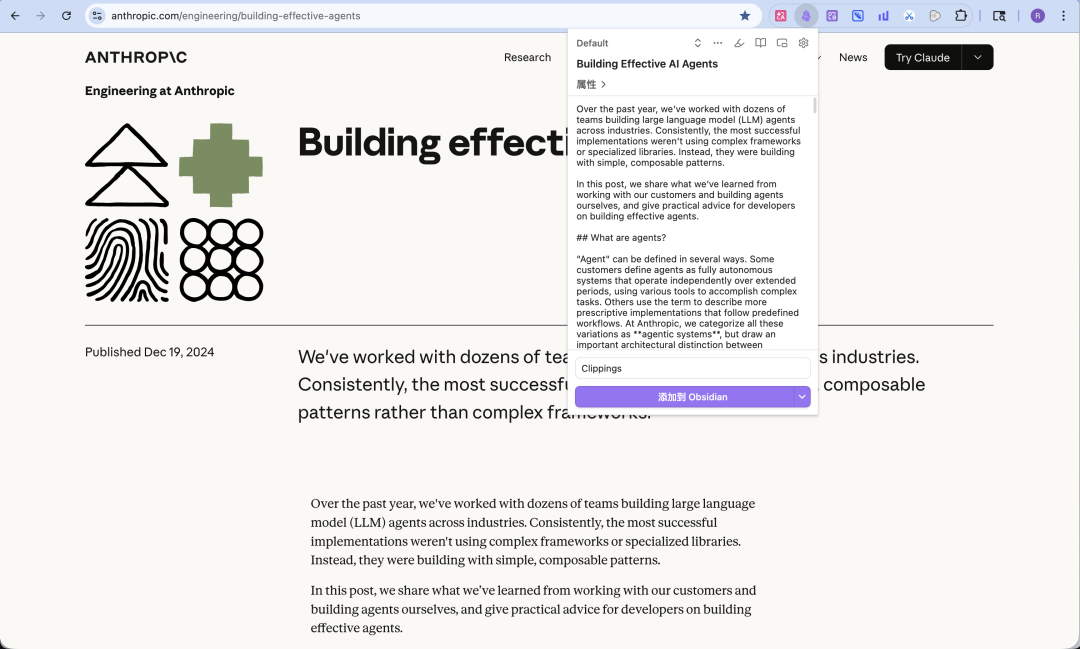
不只文本形态的网页内容,它还可以一键获取 YouTube 视频里的文字稿。
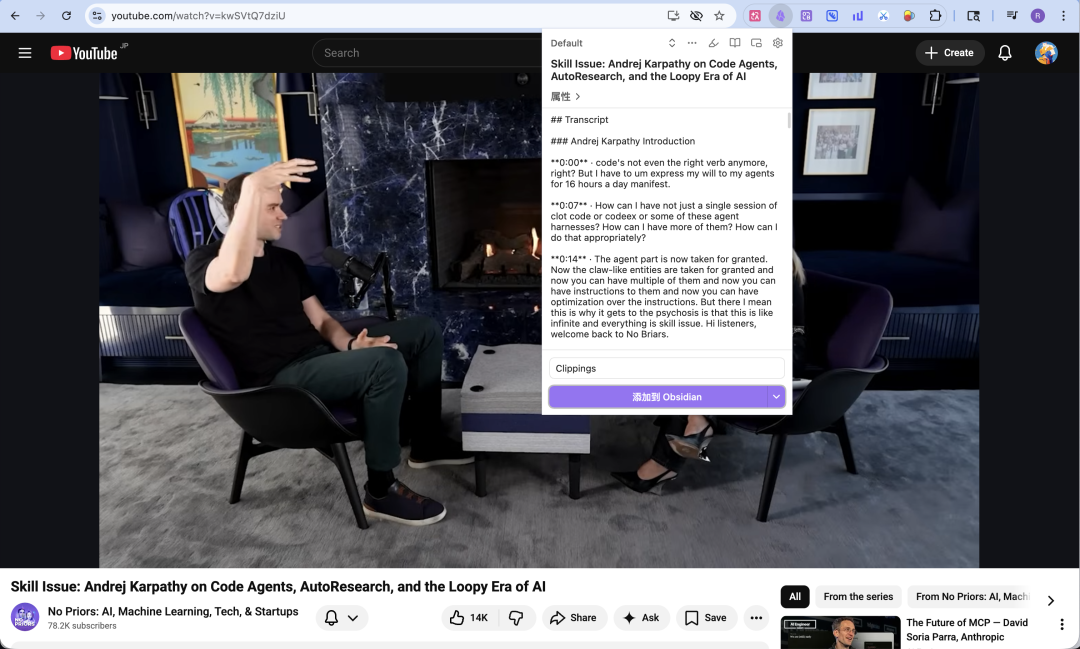
所有的内容,最终都会以 Markdown 格式保存下来。
Markdown 格式的文本内容,在 AI 时代几乎就是硬通货的存在,因为 AI 能无损理解,而且还能跨平台、保存还久。
而这些,还都只是这个插件的基操。
想要把 Obsidian Web Clipper 插件的价值最大化,那么下面这几个小技巧你们一定要试试。
技巧一:配置“解释器”
目前大多数人都是用 Obsidian Web Clipper 的默认模板,也就是下图,默认的属性、笔记内容、笔记位置等,但它们其实都可以根据自己的剪藏和阅读需求做自定义;
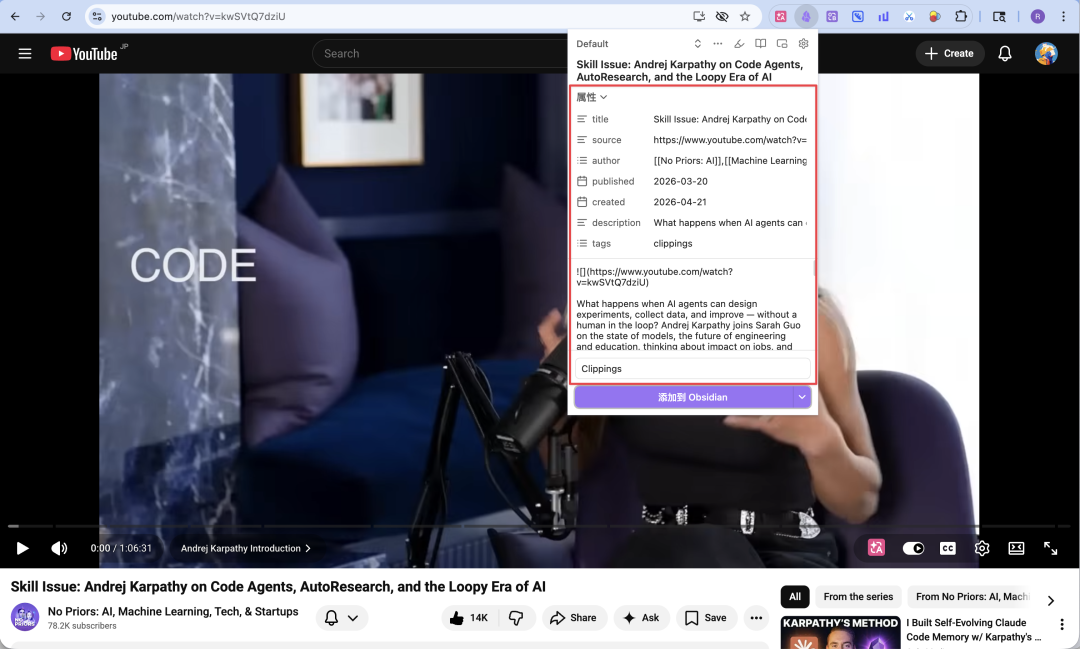
在这些自定义选项中,“解释器”最值得用起来。简单来说,它可以给 Obsidian Web Clipper 引入 AI 能力,然后通过自然语言和网页交互。
这么说可能还是有点抽象,举个例子,我们可以直接在笔记内容中添加这么一个变量:
用简体中文总结和提炼这篇文章的核心内容。请用 Why How What 结构告诉读者这篇文章为什么值得读,风格类似作家 Paul Graham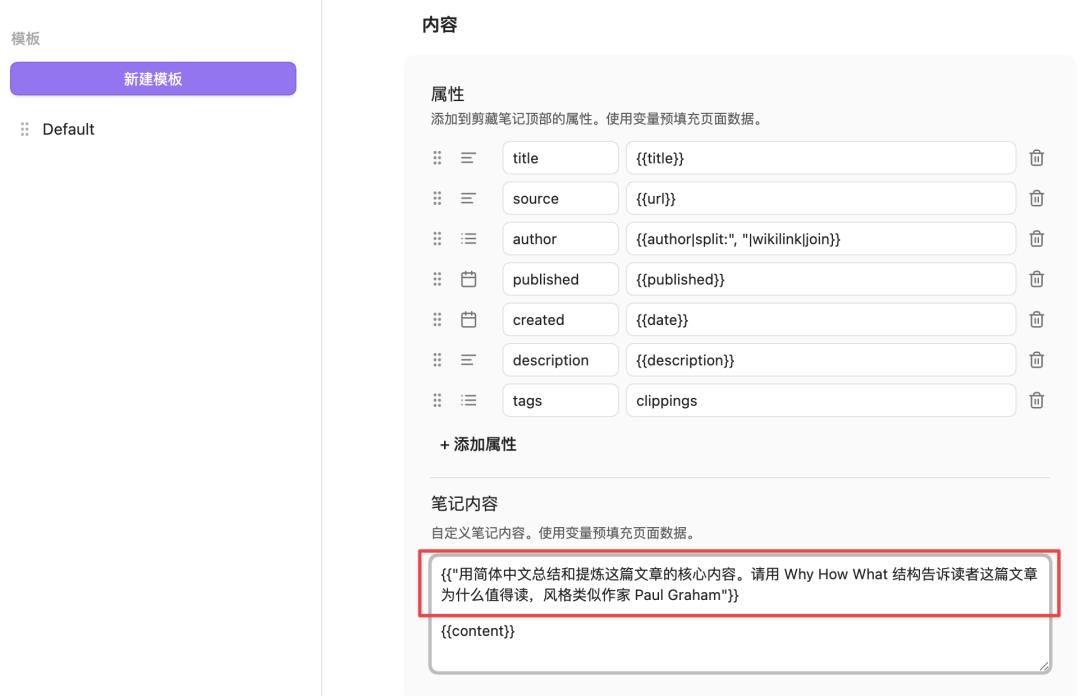
这样我们就可以先获取文章或视频的 AI 总结,再根据 AI 总结的内容决定是否要剪存到 Obsidian 中。
这里简单介绍下“变量”这个编程概念。
大家平时应该都会填一些申请表时,比如表上面写着:
- 姓名:
__________ - 电话:
__________
这里的“姓名”和“电话”就是变量。
- 我填的时候,“姓名”变量的值就是“Next蔡蔡”。
- 马斯克填的时候,“姓名”变量的值就是“马斯克”。
变量定义了数据的类型(这里该填名字),而具体填什么取决于使用者。
回到 Obsidian Web Clipper 的语境,当你写下 {{ "用简体中文总结和提炼这篇文章的核心内容" }} 时,你就创建了一个解释器变量。它和普通变量的区别是这样的:
- 普通变量: 比如
{{title}},插件直接从网页代码里“抠”出标题给你,不带脑子。 - 解释器变量: 插件把网页内容发给 AI,AI 读懂后,把计算/思考后的结果填回这个位置。
有了解释器后, Obsidian Web Clipper 就不只是剪存网页内容,还可以用在翻译、提取特定文本片段、格式转换等场景,只要我们能用自然语言描述清楚就可以实现。
那它具体该怎么配置呢?也不复杂
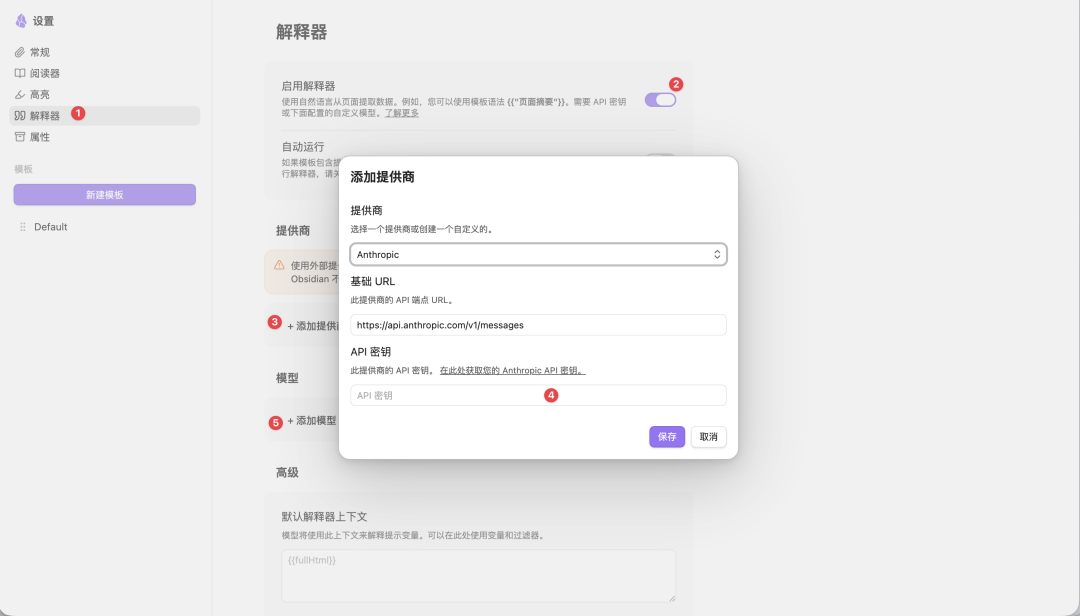
- 点击 Obsidian Web Clipper 插件面板右上角的“设置”icon,在打开的“设置”页面中选择“解释器”;
- 点击“启用解释器”;
- 点击“+添加提供商”,可以在内置的模型提供商中选择,也支持自定义;
- 确定模型提供商后,就可以选择模型了。我在实测对比国内外多个模型后,最终选择了Gemini-3-Flash,因为快且准。要是选大模型的话,处理时间会拉长不少
技巧二:设置模板触发条件
如果你设置了不同的自定模板,那这个技巧一定要用上。
在“编辑模板”配置页面顶部,有个“模板触发器”让你配置 URL。怎么用呢?
举个例子,你有视频、公众号文章两个模板。
就可以给视频模板配置上这两条 URL:
1 | `- |
https://www.youtube.com/watch``https://www.bilibili.com/video
1
2
3
4
5
给公众号文章配置上这条 URL:
-
`https://mp.weixin.qq.com/s`
```
这样当你在 YouTube 视频或 B 站视频页面打开插件时,插件面板默认打开的就是视频模板,公众号页面同理。省去来回切换的麻烦。
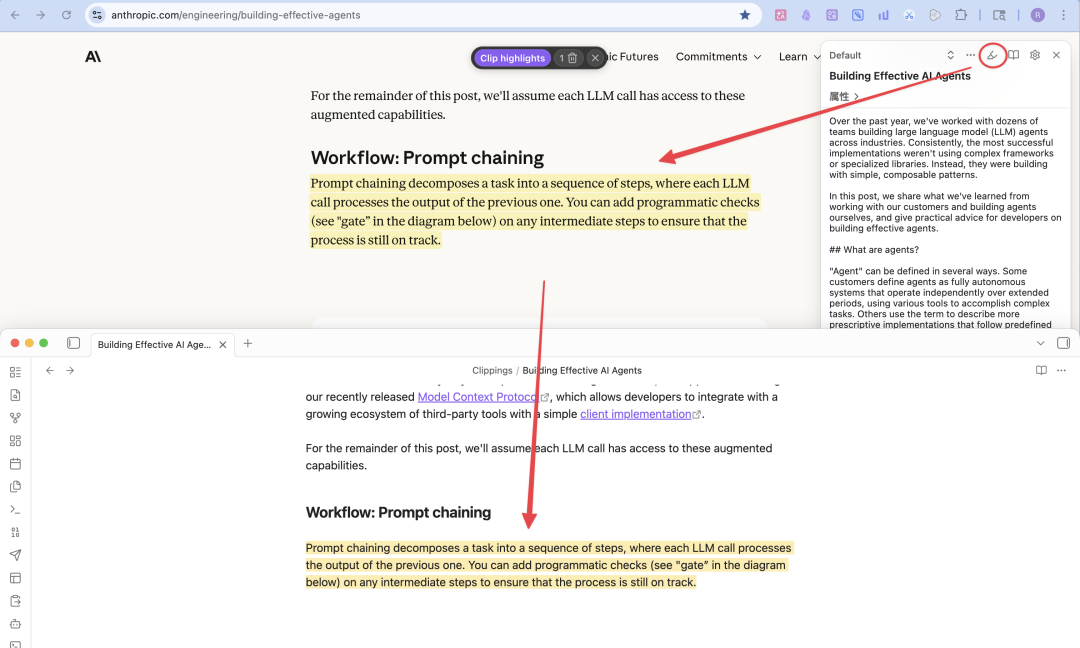
技巧三:高亮文本
当你在阅读博客或者视频文字稿的过程中,看到一些让自己很惊喜或受启发的内容,可以点击插件的“高亮”功能,这样你就可以直接划重点,而不用跳出当前网页。
所有高亮的文本,最后都会同步到 Obsidian 文档中,你就不用二次整理了。
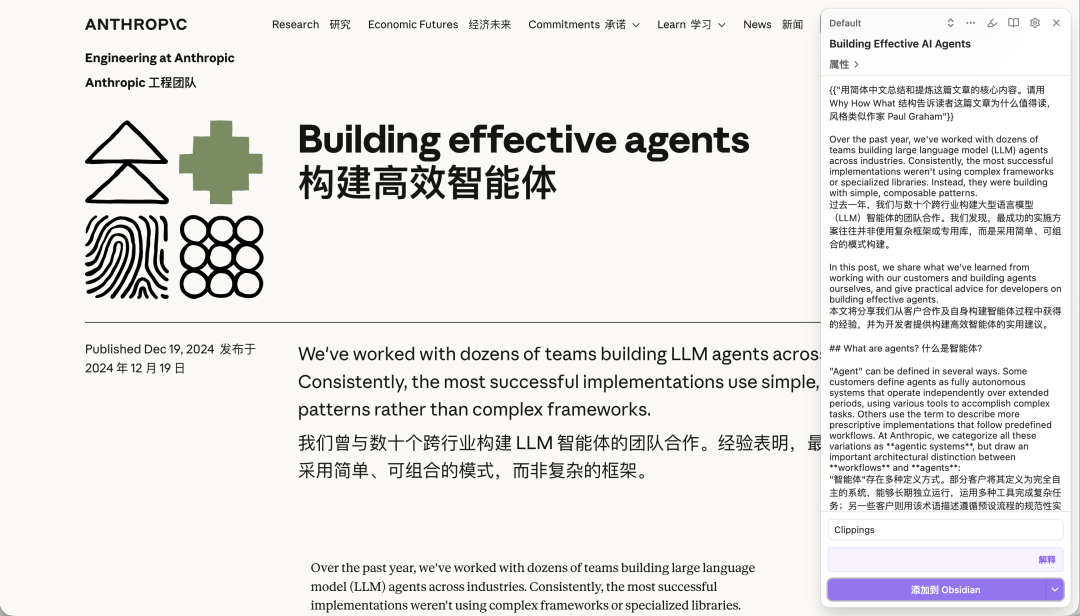
技巧四:沉浸式翻译 + Obsidian Web Clipper
如果你平常很习惯用沉浸式翻译做页面翻译,那么月可以不用在 Obsidian Web Clipper 中单独配置一个翻译解释器,而是在沉浸式翻译的页面直接打开 Obsidian Web Clipper。
然后你就会发现,Obsidian Web Clipper 是可以将同时获取原文和翻译的。
二、如何使用中文增强版 Obsidian Web Clipper ?
用好前面几个技巧,基本能把原版 Obsidian Web Clipper 的价值挖掘到 70-80%。
但如果你平常还需要经常和 B 站视频、飞书文档打交道,那么原版就不够用了,因为它不支持 B 站视频文字稿和飞书文档的处理。
那么大家可以使用这个中文内容增强的插件:obsidian-clipper-cn,它既有原版插件的所有能力,还额外支持 B 站视频和飞书文档:
🔗:https://github.com/nextcaicai/obsidian-clipper-cn
B 站视频支持
obsidian-clipper-cn 对 B 站视频的支持体验,和官方的 YouTube 集成基本保持一致,包括:
- 内容提取 — 从视频页面提取视频简介、章节和字幕
- 视频嵌入 — 在 Reader Mode 中嵌入 Bilibili 播放器,支持置顶固定
- 时间戳点击跳转 — 点击任意字幕或章节的时间戳,视频跳转到对应时间
- 自动滚动 — 播放过程中自动滚动字幕,跟随播放进度
- 高亮当前行 — 播放时高亮显示当前字幕行
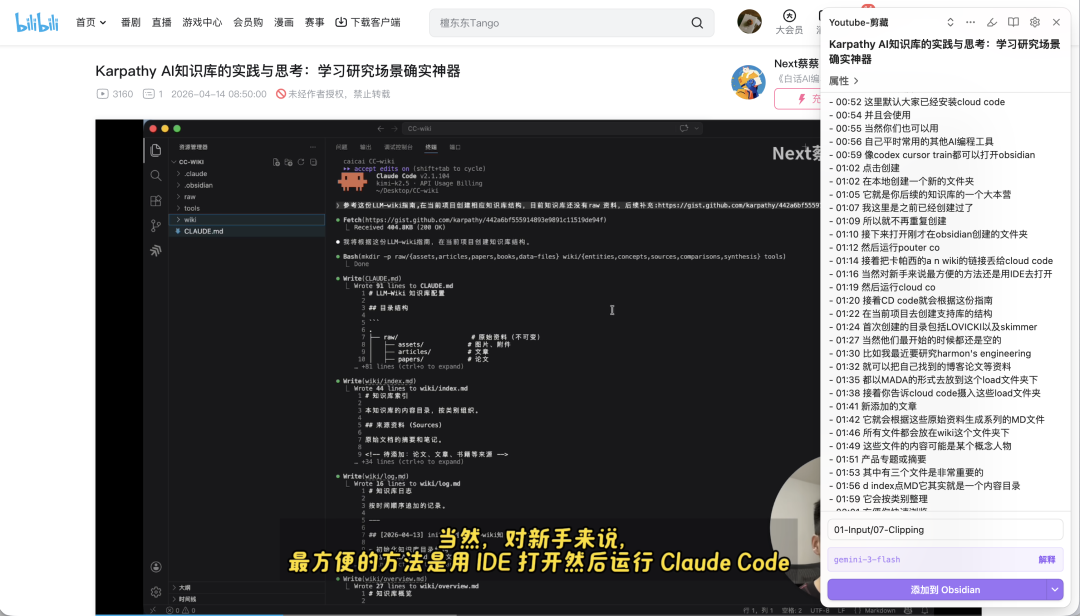
可以搭配前面提到的解释器技巧一起用,效果更佳。
飞书文档支持
原版 Obsidian Web Clipper 插件是通过通用 DOM 解析提取飞书文档内容,但会因为飞书的动态渲染机制导致内容不完整。

obsidian-clipper-cn 通过接入飞书开放平台 API,通过结构化接口完整获取文档内容。
不过目前有个不足,无法获取文档图片,后续我再看看这个问题能否解决。
使用 obsidian-clipper-cn 插件获取飞书文档的方法也不难:
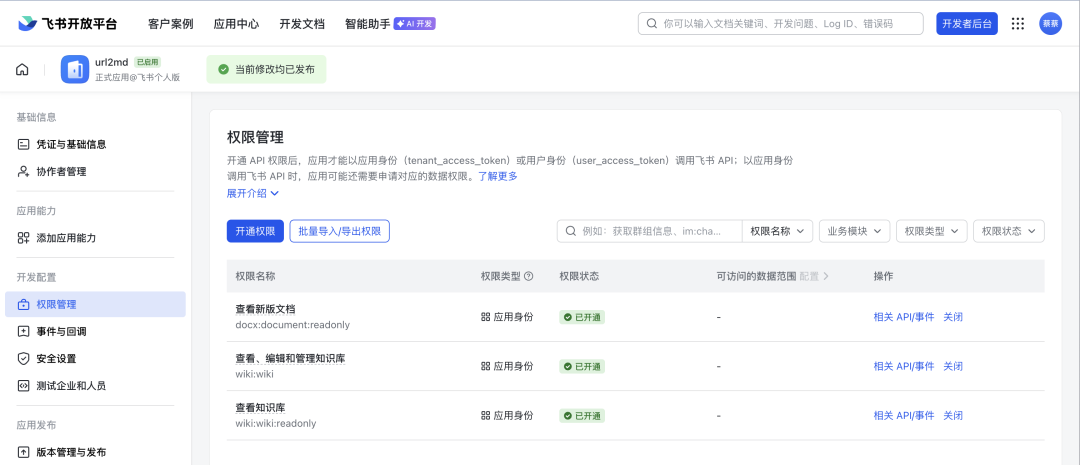
- 前往飞书开放平台(https://open.feishu.cn/app)创建一个自建应用,如果你们之前有把龙虾接入过飞书,那应该会很熟悉下面整个流程;
- 接着给应用开通以下权限:`docx:document:readonly`、`wiki:node:read`,开通完记得要启用应用才能推进后续步骤;
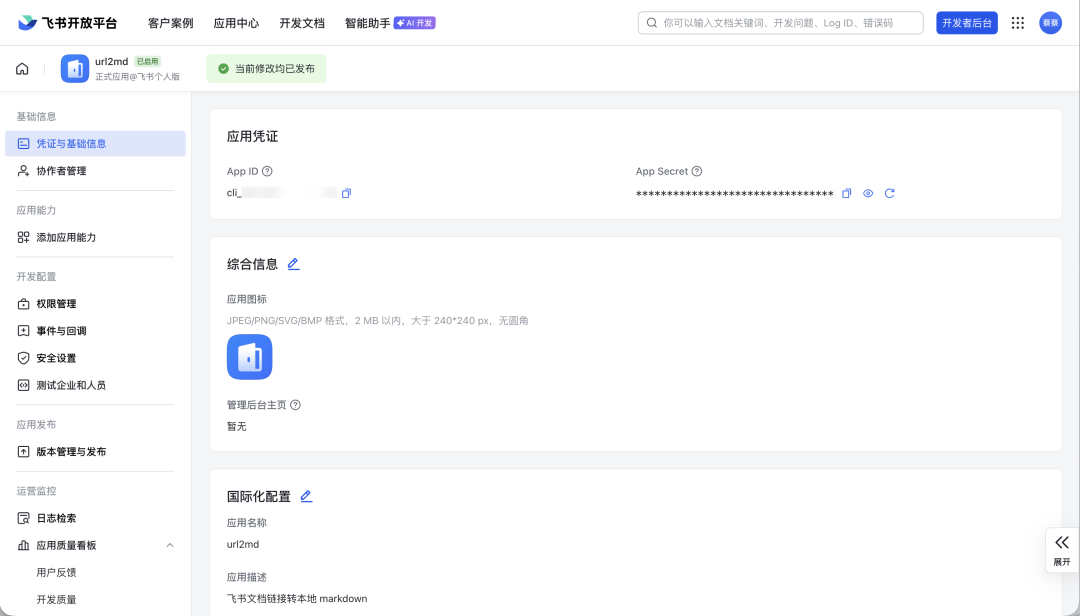
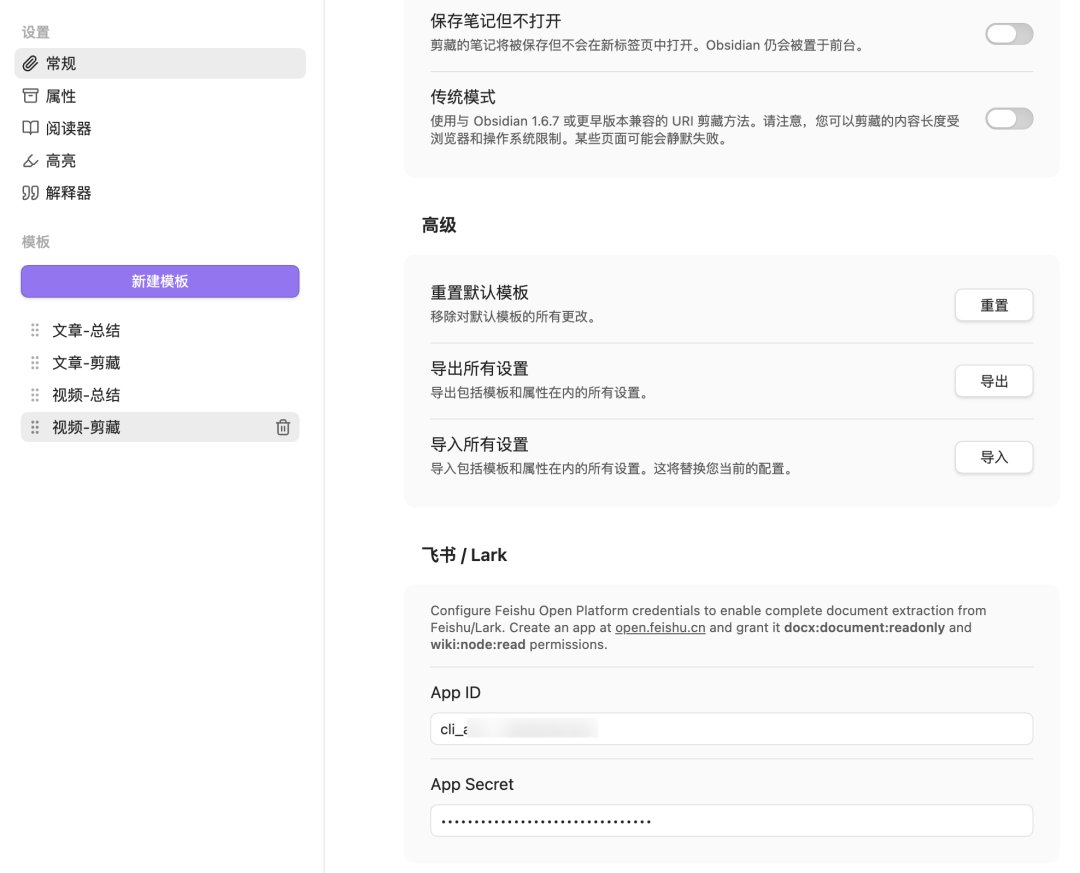
- 接着你就可以在“凭证与基础信息”这里获取应用的 App ID 和 App Secret(官方文档有非常详细的介绍>>>https://open.feishu.cn/document/server-docs/api-call-guide/calling-process/get-access-token#63c75bdc,这里就不赘述了)
- 最后,打开 obsidian-clipper-cn 插件,点击右上角“设置” ,在打开的“设置-常规”页面底部找到“飞书 / Lark”模块,填入前面获取到的 App ID 和 App Secret
> 隐私说明:App ID 和 App Secret 仅保存在你本地浏览器的存储中(`browser.storage.local`),不会上传到任何服务器。
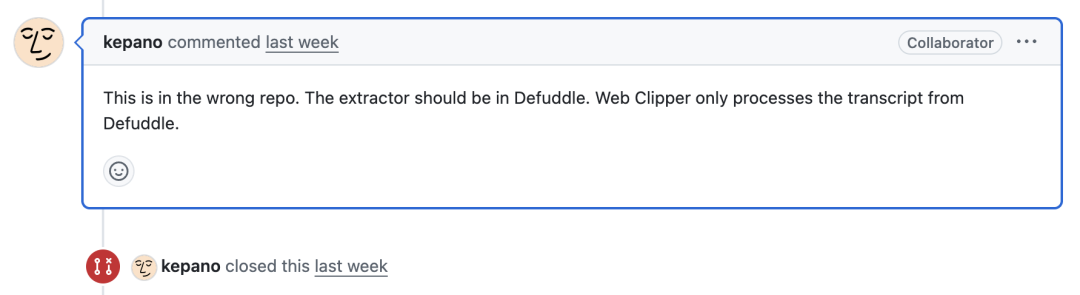
大家可能会有疑问,我为什么不把这两个渠道支持合并到原项目中。
其实我一开始有试过在官方项目中提了 PR 合并,不过没通过。Obsidian CEO 驳回的理由是:Obisidian Web Clipper 只处理从 Defuddle 处理后的内容。
后来我就想着在 Defuddle 项目上提 PR,但由于没法在本地验证自己的 PR 在 Defuddle 的真实服务器中是否成功,所以最后没提交,而是基于 Obisidian Web Clipper 做了个中文内容增强的插件,也就是大家现在看到的 obsidian-clipper-cn。
🔗:https://github.com/nextcaicai/obsidian-clipper-cn
欢迎大家体验,中间如果遇到一些体验上或功能上的不足,可以提 Issues,或者直接在这里留言反馈。
**声明:该插件已开源,仅用于学习,勿作他用。
以上就是今天的全部内容,谢谢你看到了这里。
我是蔡蔡,持续分享 AI 编程、AI Agent,以及我的 AI 学习思考。我们下期见 ~
---
> 💬 本文评论区已开启,但暂无读者留言。
> 本文转载自微信公众号,如有侵权请联系删除。
- 标题:
- 作者: lxiol
- 创建于 : 2026-04-27 20:56:02
- 更新于 : 2026-04-29 20:21:28
- 链接: https://blog.lxiol.cn/2026/04/27/如何把Obsidian-Web-Clipper价值最大化/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。