滴滴面试官追问:"Claude Code 自动帮你记了什么?你翻过 MEMORY.md 文件吗?"我打开一看,里面存的全是废话
大家好,我是吴师兄。
鹅厂面试官追问:”Claude Code 的 Memory 是什么时候注入进 system_prompt 的?”
上周发布的这篇文章事后来看写的有点简略,五一期间重新结合训练营相关的文档进行了优化,补充了load_memory_index 具体实现、文件命名安全化、悲观信任策略、Memory vs Compact 区别、两条写入路径、后台提取并发控制等内容。
以下是补充后的正文。
前两篇文章讲了 Claude Code 记忆系统的两个层面:第一篇讲了它有一套和对话历史完全分离的持久化记忆系统,跨会话存活,物理路径是 ~/.claude/projects/{project_id}/memory/;第二篇讲了 Memory 分四种类型,user、feedback、project、reference,各自对应不同的”什么值得被记住”。
写完之后,有读者追问:”师兄,我明白 Memory 存在文件里了,但它是什么时候被模型读到的?每次说话都读一次?还是只读一次?读完之后放在 system_prompt 的哪个位置?它在系统提示词里是什么格式?200 行上限是什么意思?”
问题越来越细,这说明大家真的在认真研究这套机制,而不只是停留在”知道有记忆功能”的层面。
这一篇是这个系列最核心的一篇,也是面试里拉开差距最明显的那个问题。我见过的大模型相关面试里,问”Claude Code 的记忆怎么工作”的频率在过去半年里显著上升,因为这是一个能同时考察大模型系统设计和工程化思维的好题目。
上周有个学员面滴滴,对方的团队在大规模使用 Claude Code 做内部工具开发,面试官对工具链原理非常熟悉。聊到大模型工具链设计时,面试官问:”你知道 Claude Code 的 Memory 机制吗?”
他答:知道,记忆会持久化存在文件系统里,下次会话还能用。
面试官追问:它是什么时候被读取的?是每轮对话都重新读一次,还是只在某个特定时机?
他答:应该是对话开始的时候读吧。
面试官继续:更具体一点,是哪个函数触发的?注入在 system_prompt 的第几段?为什么内存目录的获取函数故意不创建目录?
他继续答了一句”可能是为了性能”,然后就卡住了。
面试官又追了一个:”你知道 Memory 和 Compact 有什么本质区别吗?它们解决的是同一个问题吗?”
这下彻底沉默了。
面试结束后,他发消息给我说:”师兄,这几个问题我答得一塌糊涂,但我感觉面试官是真的在认真考察,不是在刁难。”
我说:对,这不是刁难,这是在看你对工具的理解停留在”会用”这一层,还是真的读过它的工程实现,能推导出背后的设计决策。
今天把 Memory 注入机制从触发时机、注入位置、文件格式、硬性限制、写入路径到并发控制,全部拆开讲,附关键源码行号和代码示例。这一篇会比较长,建议收藏后再读。
一、从路径开始:project_id 是怎么算出来的
在讲注入之前,先要搞清楚一件事:Memory 文件存在哪里,project_id 是什么,它是怎么来的。
前一篇文章讲过,Memory 的物理路径格式是:
1 | `~/.claude/projects/{project_id}/memory/` |
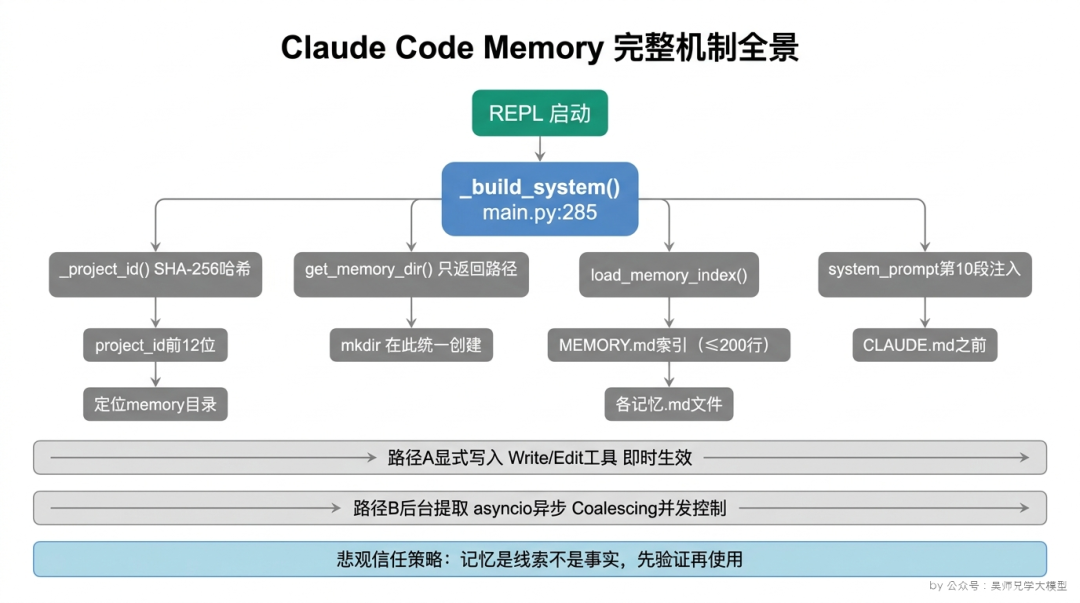
这个 project_id 不是随机生成的,也不是你手动指定的,而是根据当前工作目录的路径计算出来的。对应源码是 cc/memory/session_memory.py:18-28 里的 _project_id() 函数。
计算逻辑很简单,但细节里藏着一个重要的工程决策:
1 | `import hashlib |
用 SHA-256,取前 12 位。为什么是这两个选择?
为什么用 SHA-256,而不是 Python 内置的 hash()?
这是这道题里最能体现工程深度的一个细节。Python 3.3 之后,hash() 函数默认启用了随机化(由环境变量 PYTHONHASHSEED 控制),同一个字符串在不同进程里会得到不同的哈希值。举个例子:
1 | `# 进程 A(Python 3.3+,PYTHONHASHSEED 随机) |
两次启动 Claude Code,同一个工作目录,hash() 返回的值完全不同,这意味着存记忆文件的目录名每次重启都变了,所有历史记忆都找不到了。
hashlib.sha256 是确定性的:同一个输入,无论在哪台机器、哪个进程、哪个时间,输出永远一样:
1 | `import hashlib |
**持久化存储不能依赖进程随机性,**这是一条工程原则,在任何需要跨进程、跨重启保持一致性的场景里都适用。
为什么取前 12 位?
12 位十六进制字符 = 48 bit 的哈希空间。对于一台机器上的项目目录来说,发生哈希碰撞(两个不同路径得到相同前缀)的概率极低,同时 12 位又足够短,让目录名保持可读性。如果取 64 位完整哈希,目录名就变成了一串难以辨认的乱码,对调试很不友好。
这个”48 bit 够用 + 人类可读”的权衡,是一个典型的工程实用主义决策。
明白了 project_id 的计算逻辑,你就能解释一个实际使用中经常遇到的困惑:为什么我在不同目录启动 Claude Code,记忆内容不一样?因为每个工作目录对应独立的 project_id,也就对应独立的记忆空间。项目 A 的记忆不会出现在项目 B 的上下文里,这是有意隔离的。
二、注入入口:_build_system() 的完整执行链路
搞清楚路径之后,下一个问题是:Memory 文件是什么时候被读取、被注入的?
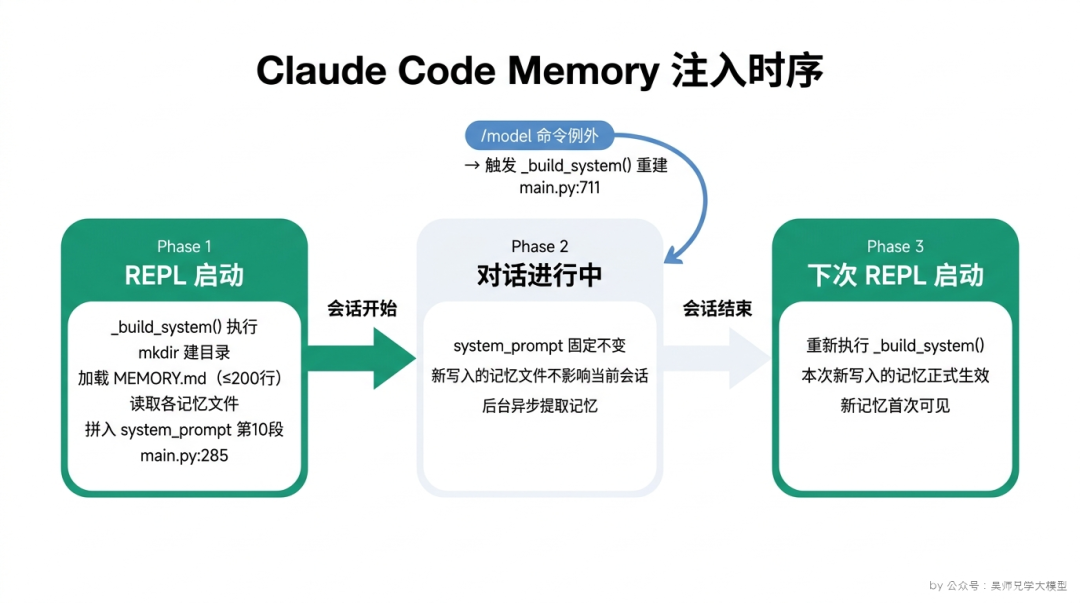
答案是 _build_system() 函数,对应 main.py:285。每次 REPL 启动时,这个函数被调用一次,负责把 system_prompt 的所有段落拼装好。
但”拼装”这两个字说得太简单了。_build_system() 实际上做了相当多的工作,按执行顺序大概是这样的:
第一步:确定工作目录,计算 project_id。
1 | `cwd = os.getcwd() |
注意这里调用的是 get_memory_dir(),这个函数只返回路径,不创建目录。这个设计后面会专门讲。
第二步:主动创建记忆目录(mkdir)。
1 | `memory_dir.mkdir(parents=True, exist_ok=True)` |
这一行才是真正创建目录的地方。放在 _build_system() 里做,而不是放在 get_memory_dir() 里,背后有明确的工程理由,后面第五节详细讲。
第三步:加载记忆索引(load_memory_index)。
1 | `memory_content = load_memory_index(memory_dir)` |
这是真正从磁盘读取记忆内容的地方。它会读取 MEMORY.md 索引文件,然后根据索引读取各个具体的记忆文件,最后把内容拼装成一段文本,准备注入 system_prompt。
第四步:按顺序构建 system_prompt 的各个段落。
builder.py:74-135 里有完整的段落构建逻辑,按顺序把所有段落拼在一起,形成完整的 system_prompt。Memory 内容排在第 10 段位置。
第五步:返回构建好的 system_prompt,REPL 开始工作。
整个过程在 REPL 启动时同步执行一次,执行完之后,system_prompt 就固定了,在当前会话期间不会再更改(除了一个例外,后面讲)。
为什么强调”只跑一次”?因为这直接决定了一个很多人想当然的误区,他们以为记忆是”写进去就实时生效”的,当前对话里写了一条记忆,模型马上就能感知到。实际上不是。_build_system() 在会话启动时运行一次之后,当前会话的 system_prompt 就固定了。你在对话中途写入的新记忆文件,对当前会话没有任何影响,要到下一次 REPL 启动时才会被读取并注入。
这不是 Bug,是有意设计的。记忆的定位是跨会话的长期状态通道,不是当前会话的实时同步机制。Session 是日志,Memory 是笔记,笔记是写给下一次用的,不是给当前对话实时刷新的。
理解这一点之后,很多使用上的困惑就解开了:为什么我刚让 Claude Code 记住了某件事,但当前对话里它好像还是忘了?因为那条记忆只有下次启动才会生效。
三、load_memory_index() 的具体实现:从磁盘到 system_prompt
_build_system() 第三步调用了 load_memory_index(memory_dir),这是整个注入机制里最核心的函数之一,值得单独拆开讲。
它的工作分三个阶段:
阶段一:读取 MEMORY.md 索引文件。
MEMORY.md 是整个记忆系统的”目录页”,格式是标准 Markdown 列表:
1 | `- [user_preferences](user_preferences.md) -- 用户编码风格和工具偏好 |
每行的格式是:- safe_name -- description。safe_name 是文件名(不含扩展名),description 是这条记忆的一句话说明,让模型在不读完整内容的情况下也能知道这条记忆大概讲什么。
load_memory_index() 先读这个文件,解析出所有条目的 safe_name 和 description。注意前面提到的硬上限:最多读 200 行(MAX_ENTRYPOINT_LINES = 200,sections.py:179),超过的部分直接截断。
阶段二:根据索引读取各个记忆文件。
对于 MEMORY.md 中列出的每个条目,load_memory_index() 会进一步读取对应的 .md 文件内容:
1 | `for entry in memory_entries: |
每个记忆文件包含两部分:YAML frontmatter 和正文内容。格式如下:
1 | `--- |
frontmatter 里的三个字段:
name
:记忆的唯一标识符,等于文件名(不含扩展名)description
:一句话摘要,出现在 MEMORY.md 索引里type
:记忆类型,决定这条记忆”用来记什么”(user/feedback/project/reference)
阶段三:拼装成 system_prompt 段落。
把读取到的所有记忆文件内容,按照一定格式拼装成一段文本,注入 system_prompt 第 10 段。注入后,模型在整个会话期间都能”看到”这些记忆内容,不需要每次单独查询文件。
四、记忆文件名的安全化处理:防路径注入
在讲完加载流程之后,有一个容易被忽略的安全细节值得单独说。
记忆文件的命名有一个严格的规则:文件名(safe_name)里,所有非字母数字字符(除了连字符 - 和下划线 _)都会被替换为下划线。
对应源码:session_memory.py:91。
1 | `def _make_safe_name(name: str) -> str: |
为什么要做这个处理?防止路径注入。
假设用户让模型保存一条记忆,名字是 "../../../etc/passwd"。如果不做安全化处理,文件路径就变成了:
1 | `~/.claude/projects/{id}/memory/../../../etc/passwd` |
这会把文件写到完全不相关的系统路径,可能覆盖敏感文件。安全化之后,文件名变成 ______etc_passwd,路径拼接的结果是:
1 | `~/.claude/projects/{id}/memory/______etc_passwd.md` |
完全在 memory 目录内,安全。
这个细节在面试里能用来展示”你不只考虑了功能,还考虑了安全”。工程里一个容易被新手忽视的原则是:任何来自外部输入的字符串,在用于文件路径之前都需要做安全化处理,不论这个”外部输入”看起来多么可信。

Claude Code system_prompt 构建顺序
五、注入位置:system_prompt 的第十段,位置背后的设计逻辑
现在回到注入位置的问题。
Memory 段落排在 system_prompt 第 10 段,对应 builder.py:74-135。完整顺序是:
1 | `段落 1-3: 系统核心指令(模型角色定义、基础行为规范) |
为什么这个位置值得关注?因为大量实验表明,LLM 对 system_prompt 不同位置的内容关注度并不均匀,靠近开头和结尾的内容通常有更高的注意力权重,中间位置的内容容易在长上下文里被稀释(这就是 Anthropic 在自己论文里提到的”Lost in the Middle”现象)。
Memory 排在第 10 段,在工具描述之后、用户项目配置之前,处于 system_prompt 的中前部。这个位置的设计意图是:
首先,要在工具描述之后,因为工具描述定义了模型”能做什么”,Memory 定义了”用户是谁、偏好什么”,逻辑上应该先知道工具能力,再去看用户偏好。
其次,要在 CLAUDE.md 之前,因为 CLAUDE.md 是用户针对当前项目的明确指令(比如”这个项目一律用 TypeScript”),它的优先级要高于 Memory 里存的历史偏好(比如”用户一般喜欢用 Python”)。当两者冲突时,模型应该遵从 CLAUDE.md 里更具体、更明确的指令。
这个优先级规则在实际使用中很重要:如果你在 Memory 里记了”用户喜欢写详细的注释”,但项目的 CLAUDE.md 里写了”注释保持最简”,模型会优先遵从 CLAUDE.md,不会因为 Memory 里的历史偏好而覆盖当前项目的约定。
六、MEMORY.md 的 200 行硬上限:token 预算的权衡
Memory 注入有一个硬性限制,面试里能说出来会让人眼前一亮:MEMORY.md 最多读取 200 行。
对应源码:sections.py:179,常量名是 MAX_ENTRYPOINT_LINES = 200。超过 200 行的部分会被截断,并附上一条警告信息提示用户 MEMORY.md 已经太长了。
200 这个数字不是拍脑袋定的,背后是 token 预算的权衡:
MEMORY.md 是记忆的索引,每行格式是 - safe_name -- description。索引行本身不含完整内容,只是告诉模型”有这些记忆可用”和”每条记忆大概讲什么”。一行索引大约消耗 20-40 个 token,200 行大约是 4000-8000 token。
这 4000-8000 token 是”索引成本”——模型需要读完所有索引,才能知道自己有哪些记忆可以调用。如果把上限设得太高,索引本身就会占用大量 context window,反而影响模型处理实际任务的能力。
但 200 行对大多数用户来说已经绰绰有余。能写满 200 条记忆索引,说明这个项目的记忆管理已经相当精细了。如果真的触达上限,应该做的是整理和合并记忆(把多条相关记忆合并到一个文件里),而不是期望超过 200 行的部分还能被读取。
这里有一个 Python 示例,展示如果你想手动检查当前项目的记忆索引有多少行:
1 | `from pathlib import Path |
七、get_memory_dir() 故意不建目录:读操作不应有写副作用
现在讲一个面试里能用来展示工程深度的细节。
get_memory_dir() 这个函数的职责是返回当前项目的记忆目录路径,但它故意不创建这个目录。
听起来有点奇怪,对吗?一个负责”获取记忆目录”的函数,为什么不顺手把目录建好?
原因是一个工程原则:读操作不应该有写副作用。
get_memory_dir() 的语义是”告诉我目录在哪”,而不是”确保目录存在”。这两件事听起来很像,但有本质区别:
1 | `# ❌ 错误的实现:读操作藏了写副作用 |
错误实现的问题有三个:
第一:破坏了函数的单一职责。 命名是 get_memory_dir,语义是”获取目录路径”,但偷偷在里面做了”创建目录”的事情,两种完全不同的操作被混在了一起。
第二:让行为变得难以预测。 如果在只读文件系统上运行(比如某些 CI 环境、容器里的挂载卷),mkdir 会报错。调用者原本只是想拿个路径,却意外遭遇了文件系统异常。
第三:污染测试场景。 单元测试里如果调用 get_memory_dir(),会在文件系统上真实创建目录。测试结束后得手动清理,否则留下副产物。
那目录是什么时候创建的?答案在 _build_system() 里:
1 | `# main.py(简化版) |
_build_system() 是”启动 REPL 并构建工作环境”的地方,它有明确的写操作职责(创建目录、写入必要文件等),在这里做 mkdir 是合适的。
这个设计带来了另一个好处:通过在 _build_system() 里提前建好目录,模型在后续对话中直接用 Write 工具写记忆文件时,不需要额外一次工具调用先检查和创建目录,可以直接写入。这减少了一次工具调用的延迟,也让模型的行动更流畅。
这个细节背后的工程直觉是:把副作用集中在有明确”初始化”职责的地方,读取路径和创建目录是两件事,要分开做。这在任何大型项目的代码库里都是好的实践。
八、悲观信任策略:Memory 是线索,不是事实
现在讲一个很多人没听说过的设计:TRUSTING_RECALL_SECTION,对应 sections.py:287-297。
这是注入到 system_prompt 里的一段特殊指令,告诉模型怎么使用记忆内容。它的核心思想可以用一句话概括:
记忆是线索,不是事实。
具体来说,这段指令告诉模型:
“一条记忆,如果它提到了某个文件路径、函数名或者配置项,那它是在声明’这个东西在记忆被写入时存在’。但代码库是会变化的,那个文件可能已经被重命名了,那个函数可能已经被删掉了,那个 flag 可能从来就没有合并进主分支。”
所以当模型在 system_prompt 里读到这样的记忆时:
1 | `Memory: 用户的主入口文件是 src/main.py,启动命令是 python src/main.py --debug` |
正确的处理方式不是直接告诉用户”你的主入口文件是 src/main.py”,而是先验证:
1 | `# 记忆说有这个文件,先确认一下 |
对应的操作规则是:
- 记忆提到文件路径 → 先用
Read或Glob确认文件存在 - 记忆提到函数名或 flag → 先用
Grep确认 - 记忆和当前实际情况冲突 → 以当前实际情况为准,更新或删除过时的记忆
这个设计避免了 Agent 系统里的一个经典失败模式:模型过度信赖自己一个月前的记忆,在已经过时的信息基础上给出错误建议。
举一个具体场景:你有一条记忆说”数据库连接字符串在 config/db.yaml”,但三周前你把配置文件迁移到了环境变量。如果模型无条件相信记忆,会一直去找 config/db.yaml 这个文件,找不到之后可能给出错误的建议(比如”你的 db.yaml 文件丢失了,需要重新创建”)。
悲观信任策略下,模型会先 Glob 一下文件系统,确认 config/db.yaml 不存在,然后更新记忆(删掉过时的条目,或者写入新的配置位置),最后再给出正确的建议。
这个”先验证再使用”的原则,在任何依赖外部状态的 Agent 系统里都应该遵循,记忆、数据库查询结果、API 返回值,都可能是过时的,不能无条件信任。
九、当前会话 system_prompt 不实时更新——以及唯一的例外
前面提到了 _build_system() 在 REPL 启动时只运行一次,这里深挖这个机制的含义。
会话启动后,新写入的记忆不会触发 system_prompt 更新。具体说:后台异步提取到了新记忆,写入了文件系统之后,当前会话的 system_prompt 不会刷新。模型在当前会话里看不到这条新记忆,仍然按之前的 system_prompt 行动。
这个设计不是疏漏,而是有意为之。想象一下如果 system_prompt 实时更新会发生什么:
每轮对话结束,后台提取新记忆,写入文件,然后重建 system_prompt,注入更新后的内容,这意味着模型的”世界观”在对话进行中会发生变化,它对自己应该做什么、用户偏好什么的理解会在对话中间突然改变。这会导致行为不一致,前半段对话和后半段对话里模型的表现可能截然不同。
更稳定的设计是:一次对话,一个固定的上下文。 本次对话里写入的新记忆,对当前对话不生效,留给下次用,这就是”Memory 是写给未来的”的含义。
但有一个例外:/model 命令。
当用户在对话中执行 /model 切换模型时,Claude Code 会重新调用 _build_system(),对应 main.py:711。这意味着如果你在当前会话里写了一条重要记忆,想让它立刻对后续对话生效,可以执行一次 /model(切换回当前模型也行),这会重建 system_prompt 并读取最新的记忆文件。
1 | `# 在对话中执行,触发 system_prompt 重建 |
这是一个”不那么显眼但非常实用”的技巧。注意:/model 命令切换模型的实际效果,加上触发记忆重载的副作用,理解了底层机制,你就知道什么时候该用这个技巧。
Claude Code Memory 注入时序
十、两条写入路径:显式记忆 vs 后台提取
讲完读取,说说写入。Memory 有两条完全不同的写入路径,混淆这两条路径会导致对”记忆什么时候写入”的理解出现偏差。
路径 A:模型主动写入(显式记忆)
当用户明确说”记住这个”,或者模型判断某个信息值得保存时,模型直接使用 Write 工具写 .md 文件,再用 Edit 工具更新 MEMORY.md 索引。
1 | `# 模型执行的操作(简化展示) |
这条路径完全由 prompt 驱动,代码层面零特殊处理。模型把 Write 和 Edit 当作普通工具调用来操作文件,和它写任何其他文件没有区别。最大的优势是即时性:写完之后模型立即可以读回来确认内容,能做到”写了就验证”。
路径 B:后台自动提取(隐式记忆)
每轮对话结束后,main.py:783-805 会在后台启动一个异步任务:
1 | `# main.py(简化版) |
这个后台任务会分析本轮对话内容,判断有没有值得提炼的信息,如果有就自动写入记忆文件。
三个关键的工程细节:
fire-and-forget,不阻塞 REPL。asyncio.create_task() 是异步的,后台任务在运行,用户已经可以输入下一轮问题了。用户感知不到任何延迟。
低配模型调用,省 token。 后台提取调用模型时,max_tokens=1024,因为提取结果只是简短的 JSON 格式摘要,不需要长输出。这样在不影响提取质量的情况下,节省了 token 消耗。
引用防 GC。_bg_tasks.add(task) 这一行很关键。Python 的 asyncio Task 如果没有任何引用持有它,垃圾回收器可能在任务完成之前就把它清理掉,导致后台任务”静默消失”,任务还没跑完,内存就被回收了。把 Task 放进集合持有引用,任务完成后通过 add_done_callback 自动从集合移除,优雅地避免了这个陷阱。
两条路径的核心区别:
维度
路径 A(显式)
路径 B(后台提取)
触发方式
用户主动要求,或模型判断有必要
每轮对话自动触发
代码实现
纯 prompt 驱动,Write/Edit 工具
异步任务,低配模型调用
即时性
写完立即可验证
后台运行,写完当前会话看不到
覆盖场景
用户明确想保存的信息
自动发现值得提炼的上下文
十一、ExtractionCoordinator:并发控制的工程细节
路径 B 的后台提取有一个容易被忽视的并发问题:如果用户快速连续发送多轮消息,每轮结束都触发 _bg_extract(),多个提取任务同时读写 MEMORY.md,会发生数据损坏。
ExtractionCoordinator(extractor.py:253-328)解决了这个问题,用的是一种叫 Coalescing(合并) 的并发控制策略。
它维护三个状态变量:
1 | `_running: bool = False # 是否有提取正在进行 |
工作逻辑是这样的:
1 | `async def maybe_extract(self, messages: list, memory_dir: Path, model: str): |
这个策略确保了:无论并发来多少提取请求,同一时间只有一个提取任务在运行,而且最终状态一定被处理到,不会因为并发而丢失数据。
为什么用 Coalescing 而不是 Debounce?
这个问题很经典,能区分”知道概念”和”理解设计意图”两种水平。
Debounce(防抖)的策略是:等待一段时间没有新请求,再执行。如果在等待期间又来了新请求,重置计时器。结果是中间的请求都被丢弃,只处理最后一个。
问题在于:如果上一次提取刚快要结束时,又来了一条新消息,这条消息触发的提取请求因为 Debounce 的”等待”逻辑,可能要等很久才执行,甚至在某些边界情况下永远不执行。
Coalescing(合并)的策略不同:当前有任务在跑时,新请求不起新任务,而是设 _dirty = True。当前任务结束后,检查 _dirty,如果有未处理的请求,再跑一次。这样最终状态一定被处理到,不会有漏掉的消息。
MIN_NEW_MESSAGES = 4 的意义。
每次提取前,会检查”上次提取之后新增了多少条消息”。如果不足 4 条,跳过这次提取。这个设计是为了避免频繁的微小提取:一两条消息来回,可能没有任何值得提炼的新信息,但每次都调用模型提取会浪费 token。
4 这个数字是经验值,4 条消息的对话,通常积累了足够多的上下文,值得跑一次提取。
十二、Memory 和 Compact 的根本区别
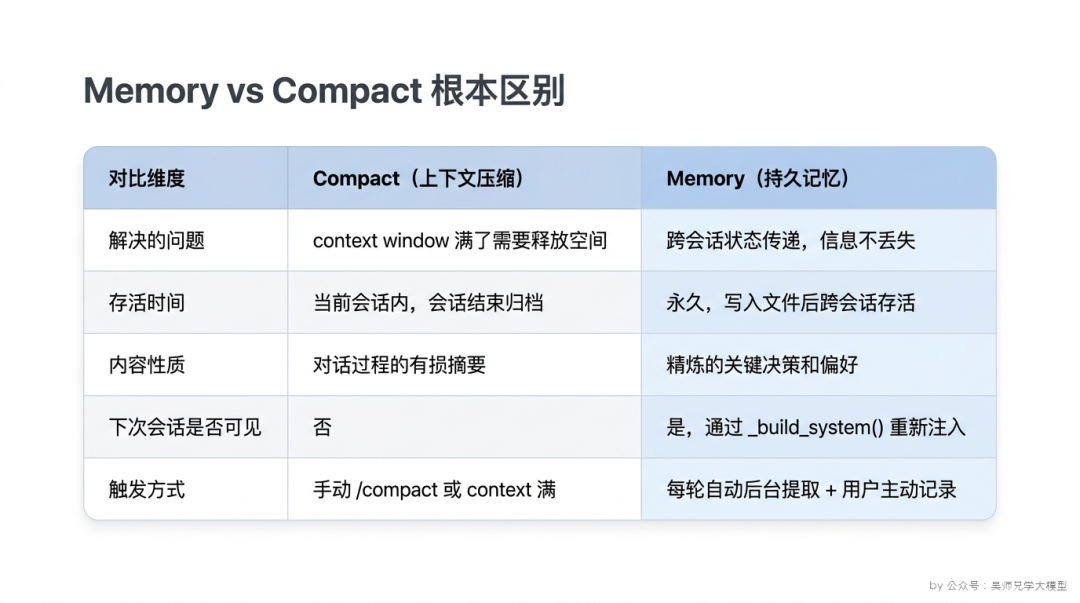
很多人会把 Memory 和 Compact(上下文压缩)混淆,因为两者都和”如何在长对话里管理信息”有关。但它们解决的是完全不同的问题。
Compact 做的是:压缩当前会话里的历史消息,释放 context window 空间。
当对话变得很长,历史消息占满了 context window,Compact 会把较早的消息压缩成摘要,保留关键信息,让 context window 里能放更多新消息。
Compact 的输出是一段摘要文字,注入到 context window 里,作为”被压缩的那段对话的总结”。但这个摘要是有损的,工具执行的详细输出、代码片段的具体内容、中间推理步骤,都可能在压缩过程中丢失。
Compact 产出的摘要只在当前会话里有效。会话结束后,摘要随着对话记录一起归档,不会出现在下次会话里。
Memory 做的是:从对话中提炼值得跨会话保留的信息,写入文件系统持久化存储。
Memory 的输出是独立的 .md 文件,存在文件系统上,下次 REPL 启动时通过 _build_system() 注入 system_prompt,永久可用(直到被手动删除)。
两者的本质区别:
维度
Compact
Memory
解决的问题
context window 满了,需要释放空间
有价值的信息需要在会话之间传递
存活时间
当前会话内,会话结束后随记录归档
永久,写入文件后跨会话存活
内容性质
对话过程的摘要(有损)
提炼出的关键决策和偏好(有选择地保存)
在下次会话是否可见
否
是,通过 _build_system() 重新注入
触发方式
手动触发 /compact,或 context 达到阈值
每轮自动后台提取,或用户主动要求记住
一个好的类比:Compact 是速记本,记的是这次会议的流水账,会议结束后封存归档;Memory 是工作笔记本,记的是值得下次用到的关键决策,每次开会前先翻一遍。
在设计 Agent 系统的记忆机制时,这两种机制通常需要配合使用:Compact 解决单次对话的 context 管理问题,Memory 解决跨会话的状态传递问题。只有其中一个,系统就是残缺的。
Memory vs Compact 对比
十三、面试怎么答”Claude Code 的 Memory 注入机制”?
如果面试官问这个问题,按这个框架答,能讲 2-3 分钟,每一句都有信息量:
第一个问题:Memory 的物理存储路径是什么?project_id 怎么算的?(20 秒)
Memory 存在 ~/.claude/projects/{project_id}/memory/ 下。project_id 由 _project_id() 函数(session_memory.py:18-28)计算,对当前工作目录路径做 SHA-256 哈希,取前 12 位十六进制字符。用 SHA-256 而不是 Python 内置 hash(),是因为 Python 3.3 后 hash() 有进程随机化,重启后会变,持久化存储不能依赖进程随机性。
第二个问题:Memory 是什么时候读取并注入到 system_prompt 里的?(30 秒)
通过 _build_system() 函数(main.py:285)在 REPL 启动时注入,执行一次,当前会话期间 system_prompt 固定不变。具体流程是:计算 project_id → 获取 memory_dir → 创建目录(mkdir 在 _build_system() 里做,不在 get_memory_dir() 里做)→ 调用 load_memory_index() 从磁盘加载记忆 → 拼装进 system_prompt 第 10 段。新写入的记忆要到下次 REPL 启动才能生效,唯一例外是 /model 命令会触发 _build_system() 重建(main.py:711)。
第三个问题:为什么 get_memory_dir() 不创建目录?(20 秒)
读操作不应该有写副作用。get_memory_dir() 的语义是”告诉我路径在哪”,不是”确保目录存在”。如果它在内部做 mkdir,会破坏函数单一职责、在只读文件系统上产生意外报错、污染单元测试。创建目录的职责在 _build_system() 里,统一做,目的是让模型后续写记忆文件时能直接写入,不需要额外的 mkdir 工具调用。
第四个问题:MEMORY.md 有什么限制?(15 秒)
最多 200 行(MAX_ENTRYPOINT_LINES = 200,sections.py:179),超出截断附警告。是 token 预算和记忆索引数量的权衡。超出上限时应该整理合并记忆,而不是期望超出部分还能被读取。
第五个问题:Memory 的写入有几条路径,有什么区别?(30 秒)
两条路径。路径 A 是模型主动写入(显式):用户说”记住这个”,模型用 Write/Edit 工具直接操作文件,即时写入可立刻验证,完全由 prompt 驱动。路径 B 是后台自动提取(隐式):每轮对话结束后,main.py:783-805 启动 asyncio 异步任务,fire-and-forget 不阻塞 REPL,用低配模型调用(max_tokens=1024)节省 token,用 _bg_tasks 集合持有 Task 引用防 GC。并发写入用 ExtractionCoordinator(extractor.py:253-328)的 Coalescing 策略控制,保证最终状态一定被处理,不丢消息。
第六个问题:Memory 和 Compact 的区别是什么?(20 秒)
解决的是两个不同的问题。Compact 解决 context window 满了需要释放空间的问题,输出是当前会话内的摘要,会话结束后归档不再可见。Memory 解决跨会话状态传递的问题,输出是持久化到文件系统的 .md 文件,下次 REPL 启动时重新注入。Compact 有损,Memory 有选择地精炼。两者应该配合使用,各自解决不同维度的问题。
第七个问题:悲观信任策略是什么?(15 秒)
Memory 是线索,不是事实(TRUSTING_RECALL_SECTION,sections.py:287-297)。记忆里提到的文件路径、函数名、配置项,是”写入时存在”的声明,可能已经过时。使用前要先用 Read/Glob/Grep 验证,和当前实际情况冲突时以实际情况为准,并更新或删除过时记忆。
能把这七个问题答下来,在绝大多数关于 LLM 工具链原理的面试里都能稳住。
Claude Code Memory 完整机制全景图
写在最后
很多人用 Claude Code 用了很久,知道它能记住东西,但不知道记忆是什么时候生效的,为什么有时候感觉”刚说过的话它又忘了”。理解了今天讲的这套机制,这些困惑就都有了答案:
记忆在 REPL 启动时一次性注入,当前会话固定不变。你在对话里写入的新记忆,要等下次启动才能被模型感知——不是忘了,是笔记写给未来用的,不是给当前对话的。
project_id 用 SHA-256 计算,不同项目目录完全隔离,记忆不会串台。MEMORY.md 有 200 行硬上限,记忆管理要做合并,不能无限堆叠。悲观信任策略让模型把记忆当线索而非事实,先验证再使用。两条写入路径各有适用场景,后台提取用 Coalescing 防并发数据损坏。Memory 和 Compact 解决不同维度的问题,一个管跨会话状态,一个管单次会话 context。
这些细节加在一起,构成了一套完整的跨会话状态管理系统,设计克制,边界清晰,每个决策背后都有明确的工程理由。
了解这套机制,不只是为了能在面试里答出来。更重要的是,当你在实际项目里用 Claude Code 遇到奇怪的行为时,模型”忘了”某件事、记忆没生效、记忆内容是过时的,你知道去哪里找原因,知道怎么调整使用策略。这是理解工具底层实现带来的真实价值。
我是吴师兄,我们下篇文章见。
本文为 Claude Code 记忆机制系列第三篇。系列往期文章可在主页查看,大模型训练营本季度正在讲解相关项目,点击了解详情:明显感觉大厂的面试已经变了。。
往期推荐
字节面试官:”LoRA 的 r 你一般设多少?” 我说 64,他摇头:”你每次都这样浪费显存?”
字节面试官:”你的 Deep Research 跑了 20 步,模型记不住第 3 步找到的结论了,怎么办?” 我:”加大 Context?” 他翻了翻白眼。。。
鹅厂面试官:”你做了三个月 RAG,召回率多少?” 我:这篇七万字是我的答案!
鹅厂面试官追问:”你的 RAG 能跑通 Demo?那让它在 5000 份文档里稳定答对,试试看”
💬 本文评论区已开启,但暂无读者留言。
本文转载自微信公众号,如有侵权请联系删除。
- 标题: 滴滴面试官追问:"Claude Code 自动帮你记了什么?你翻过 MEMORY.md 文件吗?"我打开一看,里面存的全是废话
- 作者: lxiol
- 创建于 : 2026-05-06 19:50:57
- 更新于 : 2026-05-12 16:32:44
- 链接: https://blog.lxiol.cn/2026/05/06/滴滴面试官追问Claude-Code-自动帮你记了什么你翻过-MEMORYmd-文件吗我打开一看里面存的全是废话/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。