27B 干翻自家 397B 旗舰,我用 oMLX 把 Qwen3.6-27B 跑在了 Mac 上,接上 Claude Code 不限 token
接上 Claude Code 当推理后端用,相当于拥有了一个不限 token 的编程助手。
前几天刷到阿里的消息,说他们新发的 Qwen3.6-27B 在代码编写和 Agent 任务上表现挺强的,比之前的版本提升明显。
说实话我一开始没太在意。27B 的模型,能有多强?
直到我看到这组数据。在编码领域最权威的 SWE-bench Verified 测试中,Qwen3.6-27B 拿到了 77.2 分。而阿里上一代旗舰、397B 参数的 Qwen3.5-397B-A17B,拿的是 76.2 分。
27B 干翻 397B。
不只是 SWE-bench,在 SWE-bench Pro、Terminal-Bench 2.0、SkillsBench 这些主流编程基准上,Qwen3.6-27B 全面碾压了自家的巨无霸前代。SkillsBench 更是从 30.0 直接干到 48.2,差距拉了 60% 以上。
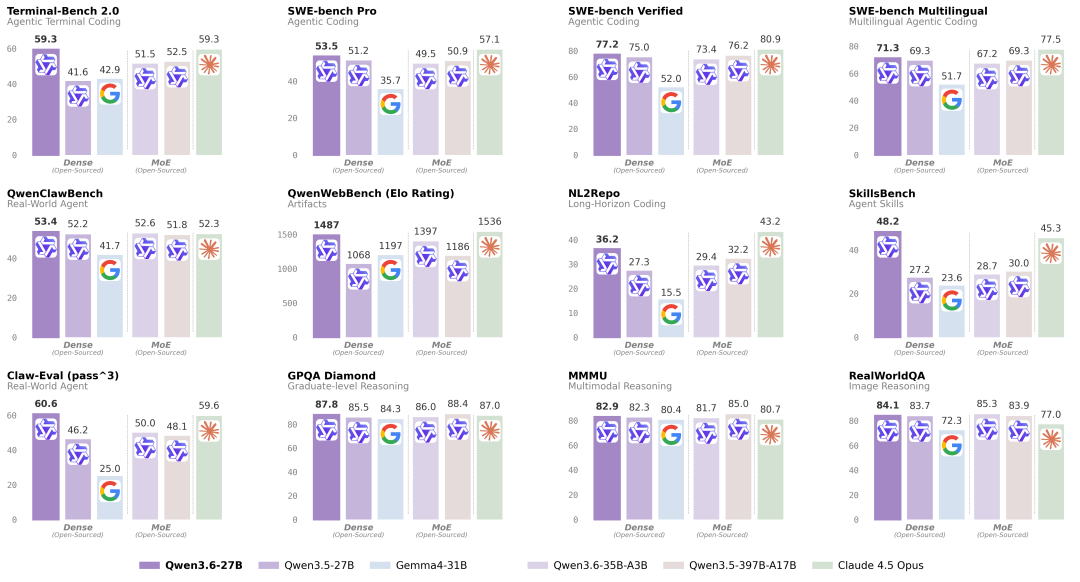
一个 27B 的稠密模型,参数量只有前代的十五分之一,却在代码能力上全面超越。这个事情本身就很离谱。
然后我又看到有人讨论说,这种级别的代码模型完全可以本地跑,接上 Claude Code 当推理后端用,相当于拥有了一个不限 token 的编程助手。这个点一下子戳到我了。
我的 M5 Pro 64GB 放那也是放着,与其让内存闲着不如榨干它。
于是就动手了。装完跑起来的那一刻我盯着活动监视器看了半天,内存占用比我预期的低了很多,生成速度也很稳。
用的工具叫 oMLX,专门给苹果芯片做本地推理优化的。
为什么选 oMLX 而不是别的
我之前跑本地模型用过几套方案。llama.cpp 好用但配置比较折腾,Ollama 方便但调优空间有限,MLX 原生框架性能好但得自己写代码。
oMLX 解决的问题是,它把这些东西整合到了一起,而且专门针对 Apple Silicon 做了底层优化。
几个我觉得挺关键的点。
连续批处理。 你同时发多个请求过来,它不会一个一个排队处理,而是把请求打包在一起并行跑。如果你像我一样同时开着好几个对话窗口或者让 Claude Code 调本地模型,这个能力很重要。
分层 KV 缓存。 这个是它最有意思的地方。它的缓存分两层,热缓存在内存里,冷缓存在 SSD 上。当你聊了很久上下文很长的时候,热缓存满了就把不常用的 KV 块卸载到硬盘。下次你又聊到相关话题,直接从硬盘加载,不用重新计算。
甚至关掉服务器再重启,冷缓存还在。这个体验就跟浏览器的缓存一样,刷新页面不用从头加载所有资源。
内存管理。 它有一个 LRU 淘汰机制,内存不够用的时候自动把最久没用的模型从内存里卸掉。你也可以把常用模型钉住,让它一直驻留在内存里。
还有一个进程级内存限制,默认是系统总内存减 8GB,防止把你的 Mac 直接搞崩。这个真的太重要了,之前我用别的工具跑大模型,直接把系统干到交换空间狂写,风扇转到起飞,整个电脑卡成幻灯片。
怎么装
装起来其实特别简单,三种方式任选。
方式一,直接装 App。 去 oMLX 的 GitHub Releases 页面下载 .dmg 文件,拖进 Applications 就完事了。它自带自动更新,后续升级一个点击的事。
1 | https://github.com/jundot/omlx/releases |
方式二,Homebrew。
1 | brew tap jundot/omlx https://github.com/jundot/omlx |
装完之后如果想让它后台常驻运行,一个命令:
1 | brew services start omlx |
崩溃了还会自动重启,挺省心。
方式三,从源码装。
1 | git clone https://github.com/jundot/omlx.git |
要求 macOS 15.0 以上,Python 3.10 以上,必须是 Apple Silicon 芯片,M1 到 M4 都行。
怎么跑 Qwen3.6 27B
第一步,启动服务。
1 | omlx serve --model-dir ~/models |
这个命令会在本地起一个推理服务,默认监听 8000 端口。它兼容 OpenAI 的 API 格式,也就是说任何支持 OpenAI API 的客户端都能直接连过来用。
不需要配这配那,模型放进去它就能认。
第二步,下载模型。
这里有两种方式。
一种是直接在 oMLX 的管理后台下载。服务启动之后浏览器打开 http://localhost:8000/admin,里面有一个模型下载器,可以搜索 HuggingFace 上的 MLX 格式模型,一键下载。
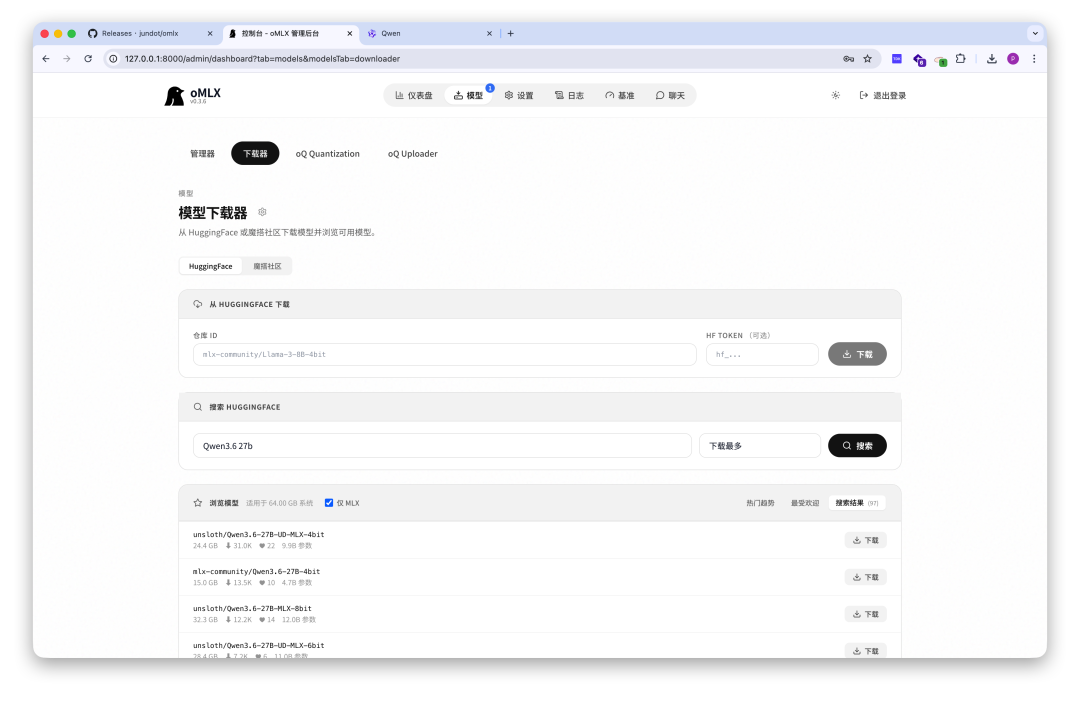
另一种是手动下载。去 HuggingFace 搜「Qwen3.6 27B」,把模型文件下载到你的 ~/models 目录下就行。模型文件夹的名字就是模型 ID,服务启动的时候会自动扫描发现。
我建议用管理后台下载,省事,而且能看到文件大小再决定下不下。
第三步,开始用。
服务跑着,模型加载好了,你可以直接在管理后台的内置聊天界面里跟模型对话,测试一下效果。
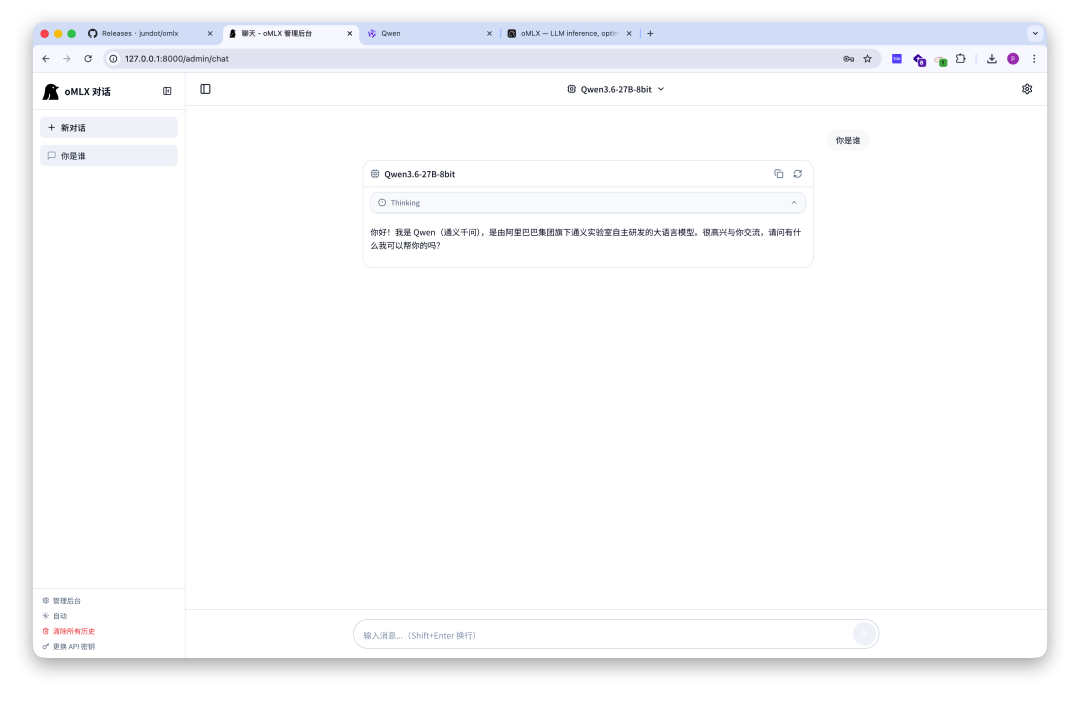
想接入其他工具的话,API 地址就是 http://localhost:8000/v1,格式跟 OpenAI 完全一样。
怎么接 Claude Code
这是我最想说的部分。
模型跑起来之后,你可以直接在 oMLX 管理后台聊天测试,但真正的价值在于把它接进 Claude Code。Claude Code 本来只支持 Anthropic 的 API,但它可以通过环境变量指向任何兼容的 API 端点。oMLX 恰好兼容 OpenAI API 格式,所以只需要告诉 Claude Code 「把请求发到本地」,就完事了。
最简方法,三个环境变量。
打开终端,把下面这几行加到你的 shell 配置里(~/.zshrc 或 ~/.bashrc):
1 | export ANTHROPIC_MODEL="Qwen3.6-27B-8bit" |
然后 source ~/.zshrc 生效,或者重新开一个终端窗口。
之后正常启动 Claude Code,它就会把所有请求发到本地的 oMLX 服务,用 Qwen3.6-27B 来推理。
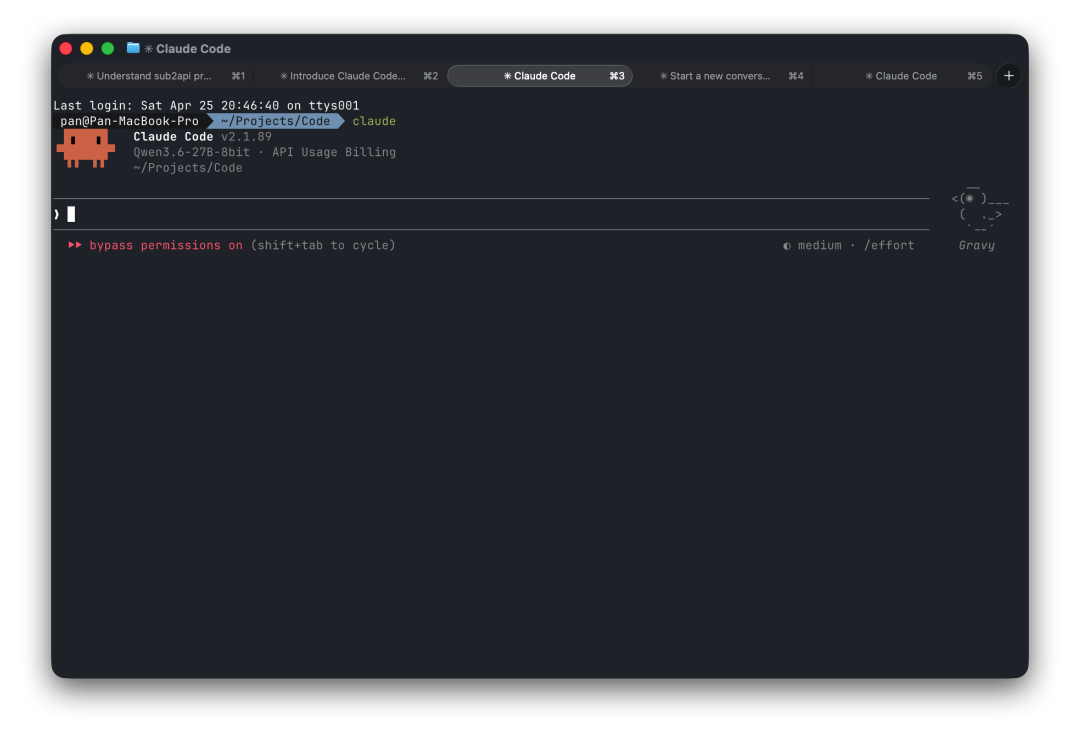
不需要改任何配置文件,不需要装额外的东西,三个变量搞定。
几个注意的点。
模型 ID 要跟你下载的模型文件夹名完全一致,大小写都不能错。如果你不确定,启动 oMLX 服务后打开 http://localhost:8000/admin,里面会显示当前加载的模型 ID。如果 oMLX 的端口不是 8000,记得把 URL 里的端口改过来。
用完想切回 Anthropic 官方 API,把那三个环境变量删掉或注释掉就行,Claude Code 会恢复默认行为。
几个我觉得有用的调优参数
这些是我自己试过的,不一定最优,但至少跑起来体验不错。
内存限制。 如果你的 Mac 内存不大,建议手动设一下上限:
1 | omlx serve --model-dir ~/models --max-process-memory 80% |
这样它会保证至少留 20% 的内存给系统和其他应用。
SSD 缓存。 如果你经常聊长上下文,建议开启 SSD 缓存:
1 | omlx serve --model-dir ~/models --paged-ssd-cache-dir ~/.omlx/cache |
首次计算完的 KV 块会存到硬盘上,下次命中缓存直接加载,省掉大量重复计算。
国内网络。 如果你从 HuggingFace 下载模型比较慢,可以换个镜像源:
1 | omlx serve --model-dir ~/models --hf-endpoint https://hf-mirror.com |
为什么这件事值得在意
你可能觉得,本地跑模型有什么用,API 调一下不就完了?
确实,对于大多数场景,调 API 是最省事的选择。但有几个场景本地推理有不可替代的优势。
隐私。 你的代码、你的文档、你的笔记,不需要发给任何第三方服务器。对于在国企、金融机构或者有合规要求的公司工作的人来说,这一点很重要。
成本。 一个 27B 模型的 API,按 token 计费的话,重度使用一个月可能要几百甚至上千。本地跑,电费忽略不计。
离线。 飞机上、高铁上、网络不好的咖啡厅,你照样能用。
速度。 不用等网络延迟,本地推理的响应时间就是一个 HTTP 本地调用的延迟,基本可以忽略。
可控。 模型就在你电脑上,你想怎么调参数、用什么量化精度、挂什么工具,全部自己说了算。不用被服务商的限流、排队、模型下线搞心态。
这些优势单独拿出来可能都不够打动人,但加在一起,对于经常跟 AI 打交道的人来说,本地模型已经不是「能跑就行」的玩具了,而是一个实实在在的生产力工具。
oMLX 让这个工具的门槛低到了「装个 App 就能用」的程度。我觉得这才是最重要的。
如果你也想在Mac 上跑本地模型,试试 oMLX。有问题可以评论区聊。
💬 本文评论区已开启,但暂无读者留言。
本文转载自微信公众号,如有侵权请联系删除。
- 标题: 27B 干翻自家 397B 旗舰,我用 oMLX 把 Qwen3.6-27B 跑在了 Mac 上,接上 Claude Code 不限 token
- 作者: lxiol
- 创建于 : 2026-05-06 19:56:54
- 更新于 : 2026-05-12 16:07:03
- 链接: https://blog.lxiol.cn/2026/05/06/27B-干翻自家-397B-旗舰我用-oMLX-把-Qwen36-27B-跑在了-Mac-上接上-Claude-Code-不限-token/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。