Redis 之父实测:DeepSeek V4 把 KV cache 压到不足 10GB!MacBook SSD 直接当推理缓存,"旧观念彻底过时了"
Redis 之父实测:DeepSeek V4 把 KV cache 压到不足 10GB!MacBook SSD 直接当推理缓存,”旧观念彻底过时了”
导读
Redis 之父 antirez 扔出一句炸弹:DeepSeek V4 的 KV cache 小到让 MacBook 的 SSD 直接变成推理缓存层,”磁盘不适合做 KV cache”的旧观念已经彻底过时。vLLM 的数据更狠——1M 上下文下,V4 的 KV cache 只有 9.62 GiB,比上一代缩小 8.7 倍。
一条”铁律”,被砸碎了
搞本地大模型推理的人都知道一条潜规则:KV cache 必须待在内存里,磁盘太慢,碰都别碰。
过去这完全正确。长上下文推理时,KV cache 随 token 数线性膨胀,几十 GiB 起步,一旦溢出内存,推理延迟直接爆炸。把它放到 SSD 上?跟摆烂没区别。
但 Redis 之父 antirez 刚刚在 X 上抛出一个观点,直接把这条规矩掀翻了。
“DeepSeek v4 small KV cache + MacBook fast SSD disks = the idea that the disk is not a good target for KV cache is, in this context, totally obsolete. It works great.”
「DeepSeek V4 的小 KV cache 加上 MacBook 的高速 SSD,让’磁盘不适合做 KV cache’的想法在这个场景里彻底过时了。效果非常好。」
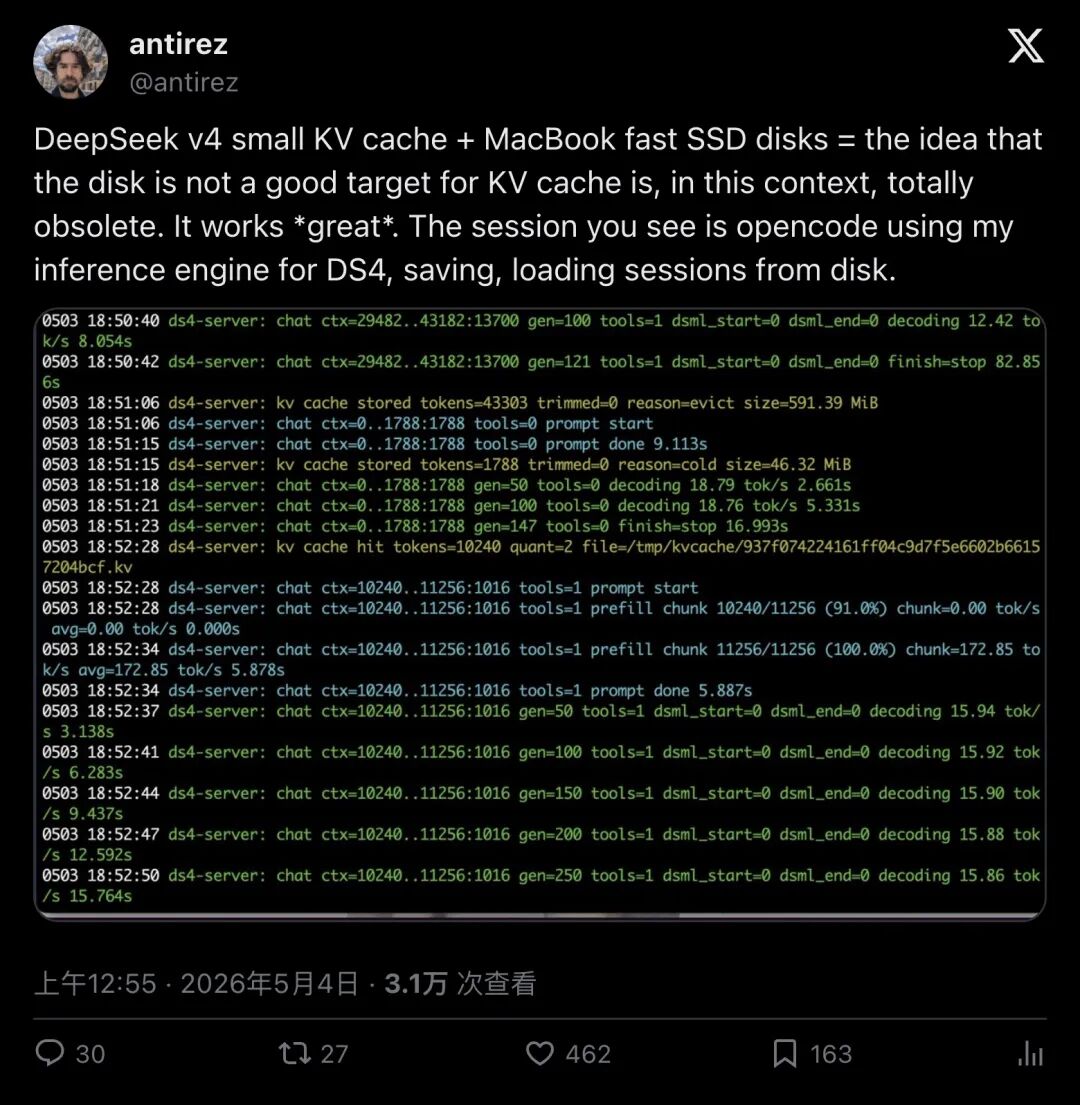
▲ antirez 推文,3.1 万次浏览,462 赞——他直接把终端日志贴了出来:session 在磁盘上存取自如
他紧接着补了一句:
“The session you see is opencode using my inference engine for DS4, saving, loading sessions from disk.”
「你看到的是 opencode 在用我给 DS4 写的推理引擎,session 直接从磁盘保存和加载。」
antirez 可不光是发了条推文。他自己动手写了一个 llama.cpp 的 DeepSeek V4 Flash fork,README 里目标写得明明白白:用 routed experts 的 2bit 量化,把 DSv4 塞进只有 128GB RAM 的 MacBook。支持 CPU 和 Metal 后端,Metal 更快。
那问题来了——KV cache 怎么就小到能放 SSD 了?
硬数字:KV cache 缩小 8.7 倍
答案在 DeepSeek V4 的架构里。
4 月 24 日,DeepSeek 官方发布 V4 时,重点提了一个概念:Novel Attention = Token-wise compression + DSA(DeepSeek Sparse Attention)。翻译成人话:每个 token 占用的缓存更少,长上下文的注意力计算范围被精准控制。1M context 直接成为所有官方服务的默认标准。
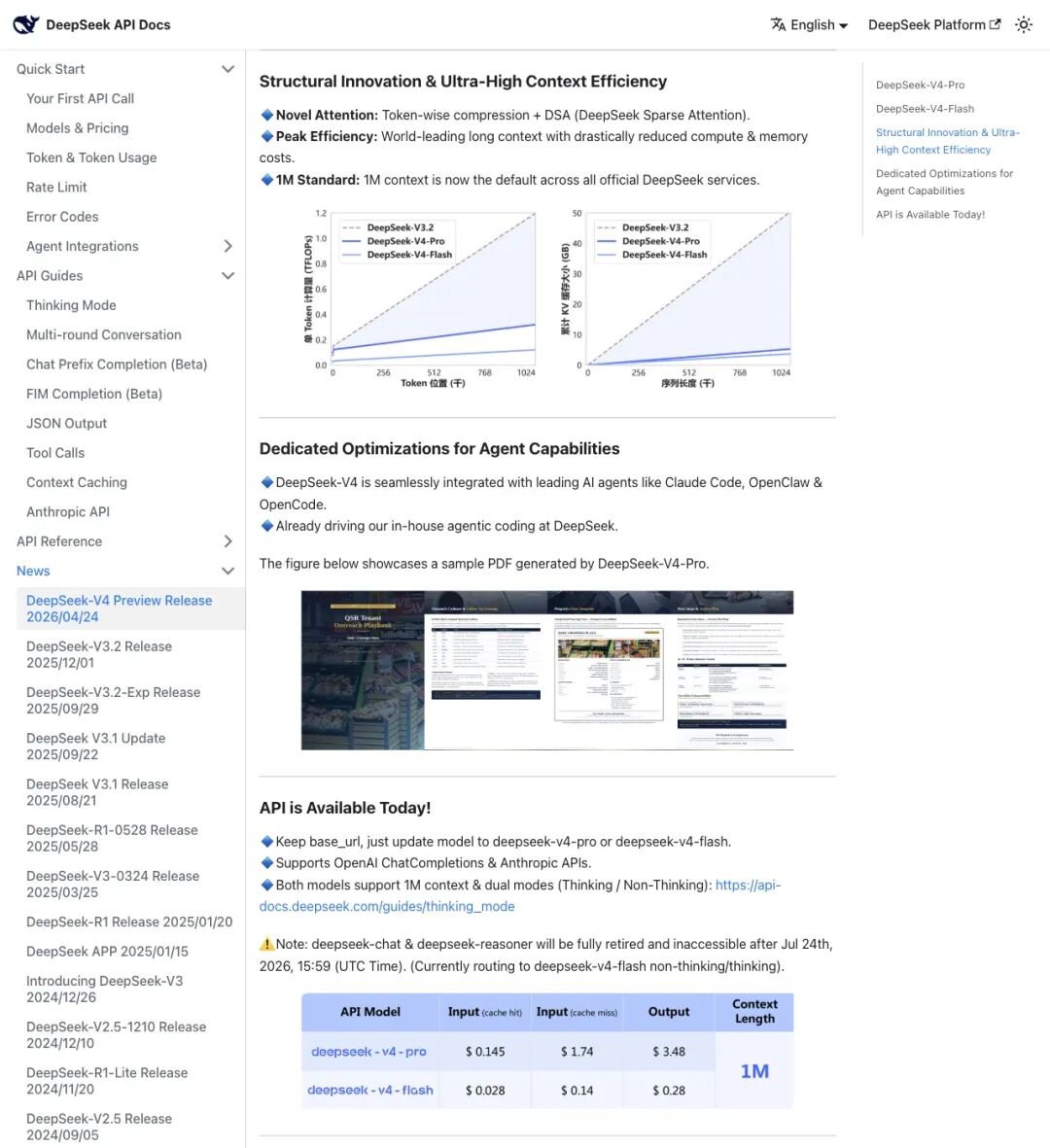
▲ DeepSeek 官方发布页:结构创新 + 超高上下文效率,V4-Pro 1.6T 总参数 / 49B 活跃参数,V4-Flash 284B 总参数 / 13B 活跃参数
但真正让人倒吸凉气的,是 vLLM 团队同一天发布的量化对比。
vLLM 把 V4 的注意力机制拆了个底朝天:共享 K/V 带来 2 倍节省、c4a / c128a 把多个 token 压缩进更少的缓存槽位、DSA 限制长上下文注意力的计算范围、sliding window 保留局部信息。
这些手段叠在一起,效果是什么?
1M 上下文下,DeepSeek V4 每个 sequence 的 bf16 KV cache 只有 9.62 GiB。
拿 DeepSeek V3.2 的 61 层架构跑同样的 1M 上下文呢?83.9 GiB。
缩小了 8.7 倍。
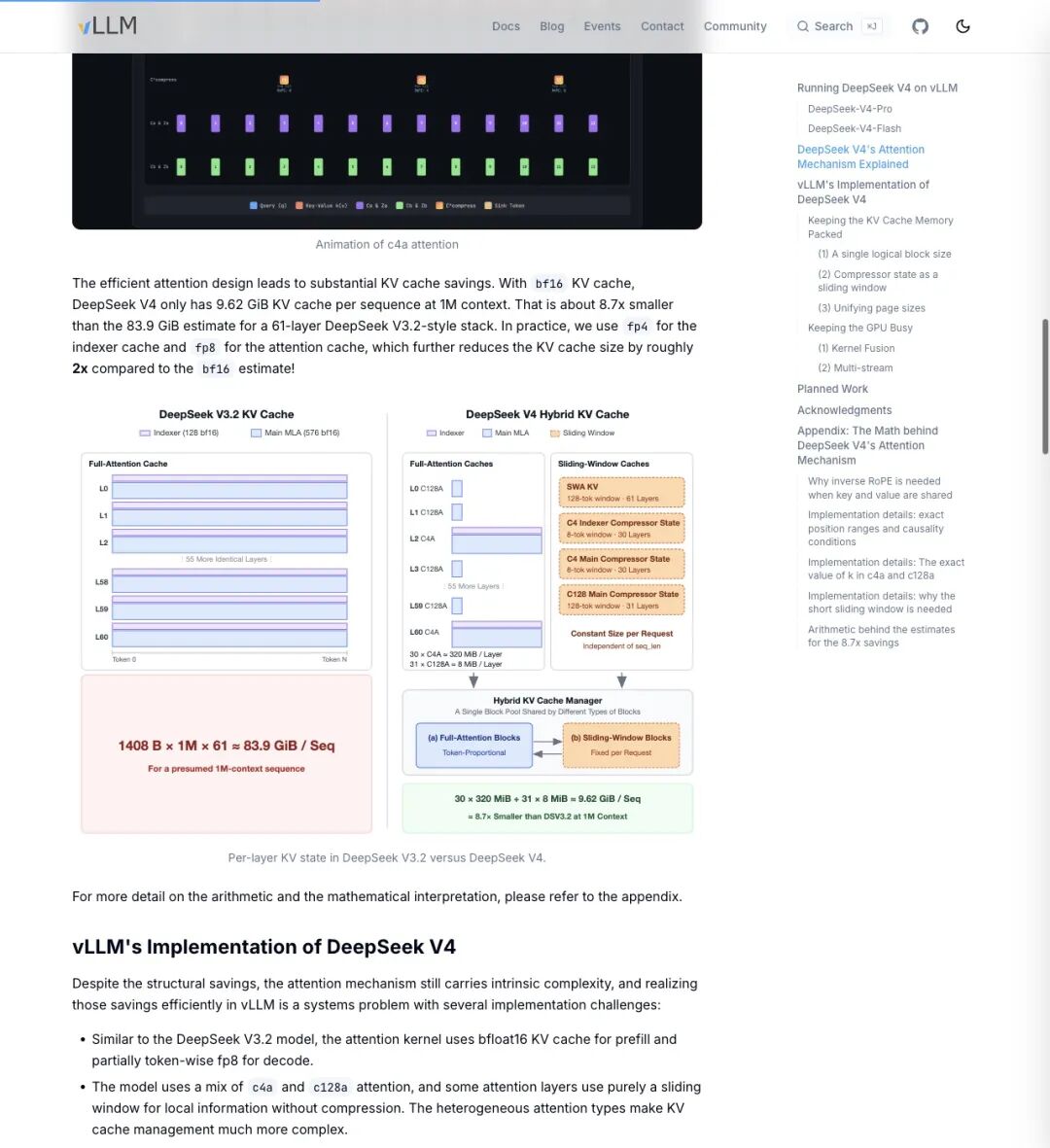
▲ vLLM 的可视化对比:左边是 V3.2 的 KV cache 体积(140.6 GiB × 1M × 61 = 83 GiB / Seq),右边是 V4——差距一目了然
更狠的是,这只是 bf16 精度下的理论估算。vLLM 指出,实际部署中如果 indexer cache 用 fp4、attention cache 用 fp8,KV 体积还能再缩大约2 倍。
也就是说,1M 上下文的 KV cache 有可能被压到5 GiB 以下。
5 GiB,MacBook 的 SSD 随便写。
MacBook 本地跑大模型,真正松动的是上下文成本
知名开发者 Simon Willison 同一天撰文,把技术细节翻译成了每个 MacBook 用户都能听懂的话。
他给出两个关键体积:V4-Pro 在 Hugging Face 上865GB,V4-Flash 是160GB。
“I’m hoping that a lightly quantized Flash will run on my 128GB M5 MacBook Pro.”
「我期待轻量量化后的 Flash 能在我的 128GB M5 MacBook Pro 上跑起来。」
“It’s possible the Pro model may run on it if I can stream just the necessary active experts from disk.”
「如果只从磁盘流式读取必要的 active experts,Pro 也许可以在那台机器上跑起来。」
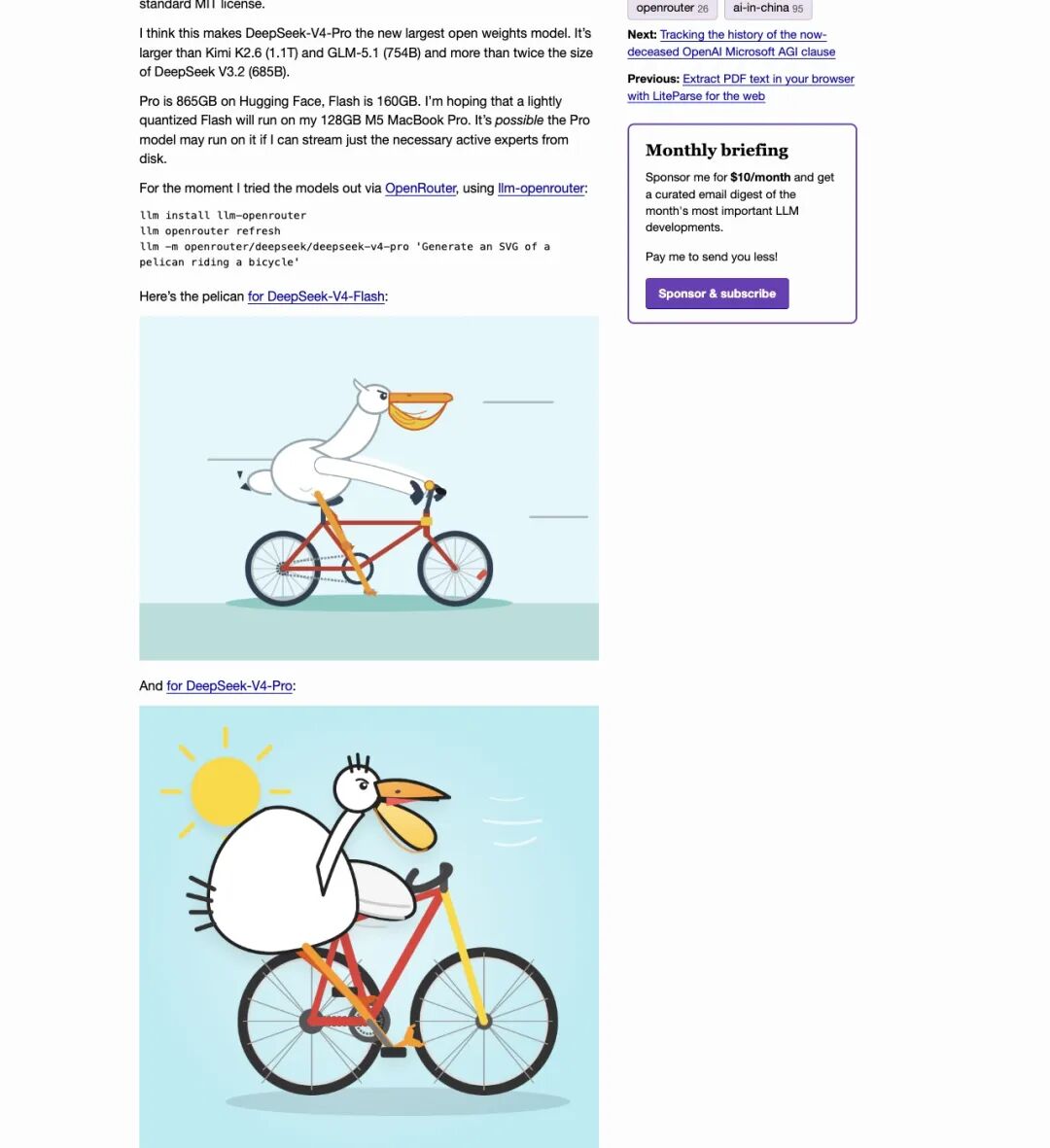
▲ Simon Willison 的判断:Flash 160GB 有望跑在 128GB MacBook 上,Pro 甚至可能通过从磁盘流式读 active experts 来运行
他引用论文数据,把对比做得更直观:
V4-Pro:1M 上下文下,单 token FLOPs 只有 V3.2 的 27%,KV cache 只有 V3.2 的 10%。
V4-Flash 更激进:单 token FLOPs 只有 V3.2 的 10%,KV cache 只有 V3.2 的 7%。

▲ Simon 引用论文数据:V4 相对 V3.2 的 FLOPs 和 KV cache 缩减幅度,Flash 版 KV cache 只剩 7%
这里有一个区分必须做清楚。Simon 说的”从磁盘流式读取”主要针对模型权重(active experts),antirez 说的则是KV cache 和 session 的磁盘存取。方向不同,但指向一个共同结论——SSD 正在从”只存模型文件”的角色,扩展到参与推理运行态。
社区已经沿着这个方向走远了
Hacker News 上,开发者们的讨论比 antirez 还激进。
有人直接算账:V4 相比 V3.2,在 1M 上下文下只需要 27% 的推理 FLOPs 和 10% 的 KV cache——本地可运行性出现了质的飞跃。
更有人给出了一句相当炸裂的判断:DeepSeek V4 Pro 因为 KV cache 极瘦,可能非常适合consumer platform + SSD offload。过去”把 KV cache offload 到存储层”听着像个糟糕主意,现在值得重新评估了。
大家开始意识到,DeepSeek V4 的”瘦 KV cache”打开的可能性远不止”跑得更快”。它允许在消费级硬件上:
- 开更大的 batch
——同样的内存,跑更多并行任务 - 跑更长的 unattended job
——挂后台跑一晚上,不用担心内存爆掉 - 跨 session 保持上下文状态
——关机重启,上下文还在磁盘上等你
新范式的轮廓已经浮现
来捋一下正在发生的事。
DeepSeek V4 通过架构创新,把 1M 上下文的 KV cache 从近 84 GiB 压到不足 10 GiB。antirez 拿着这个特性,在 MacBook 上实现了 session 的磁盘保存和加载,给出了”效果非常好”的判断。Simon Willison 认为轻量量化的 Flash 有望跑在 128GB MacBook 上。社区已经在讨论 SSD offload、overnight batch、跨 session 上下文恢复。
但边界也要说清楚:DeepSeek 官方从未声称”SSD 是 KV cache 的理想目标”,官方的表述聚焦在架构层的上下文效率提升。”SSD 可以成为推理设计的一层”这个判断,来自 antirez 的实测经验和社区推演,暂时没有标准化 benchmark 做系统对比。
但方向已经清晰得不能再清晰了。
当模型架构把缓存体积做到足够小,硬件和工程的设计空间就会被重新打开。
过去本地推理的思路是——内存装不下就别玩了。
现在的思路正在变成——内存装模型,SSD 装上下文,磁盘参与运行态。
背后的推动力来自多个层面的共振:模型结构、量化技术、MacBook 统一内存架构、高带宽本地 SSD——它们同时在发力,共同推动一场系统层的变化。
本地 AI 的下一章,可能就是从这块 SSD 开始写的。
— END —
— END —
💬 本文评论区已开启,但暂无读者留言。
本文转载自微信公众号,如有侵权请联系删除。
- 标题: Redis 之父实测:DeepSeek V4 把 KV cache 压到不足 10GB!MacBook SSD 直接当推理缓存,"旧观念彻底过时了"
- 作者: lxiol
- 创建于 : 2026-05-06 20:00:42
- 更新于 : 2026-05-12 16:07:04
- 链接: https://blog.lxiol.cn/2026/05/06/Redis-之父实测DeepSeek-V4-把-KV-cache-压到不足-10GBMacBook-SSD-直接当推理缓存旧观念彻底过时了/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。