Qwen3-TTS + oMLX 三秒钟语音克隆又快了一步
进入正文之前,呼吁声纹保护真的刻不容缓了。实测数据:3秒参考音频 → 克隆成功 | macOS App 一键安装 | OpenAI 兼容 API上次写了 中文TTS天花板!
进入正文之前,呼吁声纹保护真的刻不容缓了。
实测数据:3秒参考音频 → 克隆成功 | macOS App 一键安装 | OpenAI 兼容 API
上次写了 中文TTS天花板!CosyVoice 3 本地部署实测:3秒克隆声音,150ms流式合成,方言随便玩之后,又发现了阿里的 Qwen3-TTS——一款专门做语音合成的模型,这个在语音合成上基本可以达到以假乱真了。
最近折腾本地 TTS,发现 oMLX(GitHub 14K⭐的 Apple Silicon LLM 推理服务器)v0.3.0 悄悄上线了 Zero-shot Voice Cloning功能,直接利用OpenAI兼容API,刚好把 Qwen3-TTS 的能力完全释放出来。
关键是:macOS App 一键安装,API 直接调用,不用折腾 Python 虚拟环境。
🤔 oMLX 是什么?
oMLX(Open-source MLX)是一个专为 Apple Silicon Mac 优化的 LLM 推理服务器,GitHub 14K+ Stars。
它的核心能力:
能力
说明
LLM 推理
支持 Qwen、Llama、DeepSeek、MiniMax 等主流模型,本地跑大模型
VLM 视觉推理
支持 Qwen3.5、GLM-4V、Pixtral 等多模态模型
OCR 模型
DeepSeek-OCR、DOTS-OCR、GLM-OCR
Embedding & Reranker
BERT、BGE-M3、ModernBERT 等
TTS 语音合成
基于 mlx-audio 的 ICL(In-Context Learning),Zero-shot 克隆
STT 语音识别
ASR 能力,直接获取参考音频的文本
菜单栏管理
原生 PyObjC 开发(非 Electron),一键启动/停止,随时查看状态
🏗️ 安装方式
macOS App(最简单 ✅)
1 | `1. 打开 https://github.com/jundot/omlx/releases |
适合不想碰命令行的用户。
🚀 快速启动
安装完成后,点击菜单栏的 oMLX 图标即可启动服务。端口和api key均可自定义。
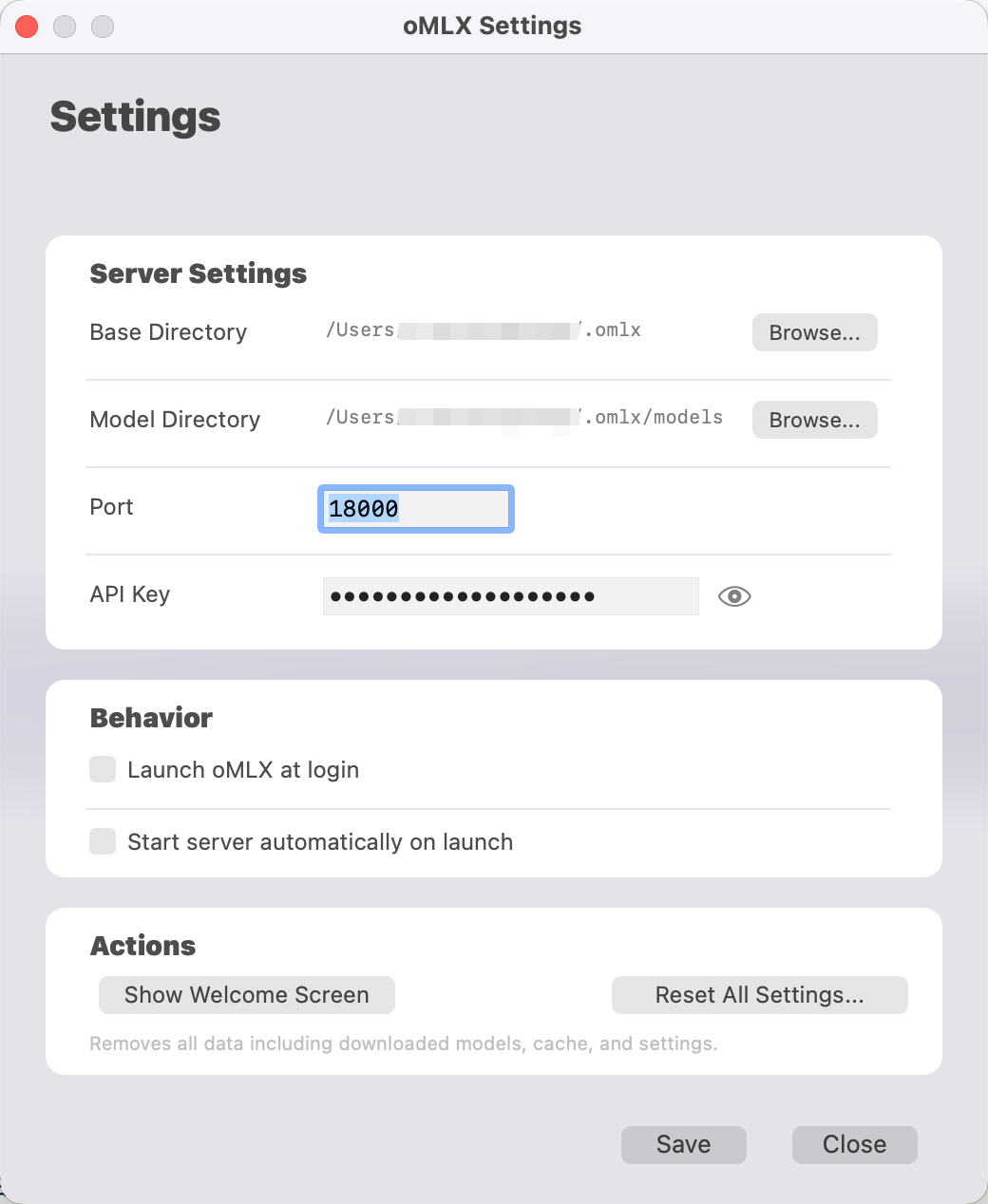
本文API 地址是 http://localhost:18000。通过web页面也可以进行详细的管理。
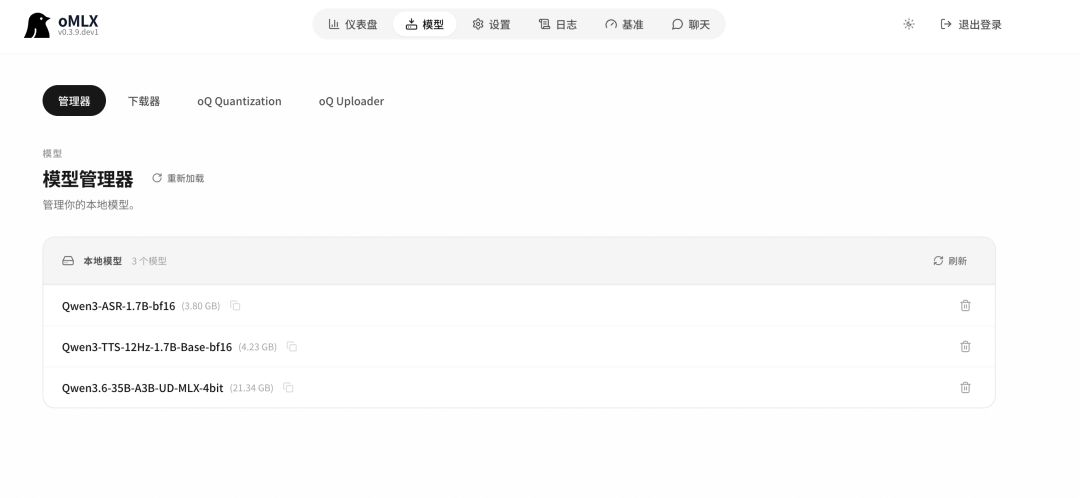
当前已加载的语音模型:
模型
用途
Qwen3-TTS-12Hz-1.7B-Base-bf16
TTS 文字转语音
Qwen3-ASR-1.7B-bf16
ASR 语音转文字
🎤 语音克隆实战
oMLX 的 Zero-shot Voice Cloning 功能在 PR #676 中实现,基于 mlx-audio 的 ICL(In-Context Learning)技术。
工作流程只有 3 步:
1 | `Step 1: ASR 转录 |
以下为完整克隆命令
1 | `# 替换为你的 API Key |
注意事项
限制项
说明
音频大小
≤20 MB(约 60 秒)
ref_text
必填,否则声音会失真
格式
只支持 WAV(MP3/M4A 需先转 WAV)
传输方式
Base64 JSON(不支持 URL)
🧪 实测数据
测试 1:3 秒克隆任意声音
用一段「仅需三秒克隆声音」的提示音频(3 秒),成功克隆出任意文本的语音:
男声原始语音:
男声克隆语音:
测试 2:女声克隆赤壁赋
女声原始语音:
女声克隆语音:
🎯 适合谁用?
场景
推荐度
说明
Apple Silicon 用户,想省事
⭐⭐⭐⭐⭐
macOS App 一键安装,不用折腾 Python
隐私敏感,不想折腾
⭐⭐⭐⭐⭐
菜单栏管理,开箱即用
快速原型验证
⭐⭐⭐⭐⭐
OpenAI 兼容 API,改造成本低
需要流式合成(实时对话)
⭐⭐⭐⭐
可以结合其他工具使用
追求中文方言效果
⭐⭐⭐
建议配合其他工具使用
总结
oMLX 的 Voice Cloning 适合 苹果电脑 + 不想折腾 + 想快速上手的开发者。
macOS App 一键安装、OpenAI 兼容 API、菜单栏管理——这几个标签往这儿一放,懂的都懂。
项目地址:https://github.com/jundot/omlx
有问题?评论区见 💬
💬 本文评论区已开启,但暂无读者留言。
本文转载自微信公众号,如有侵权请联系删除。
- 标题: Qwen3-TTS + oMLX 三秒钟语音克隆又快了一步
- 作者: lxiol
- 创建于 : 2026-05-15 10:57:13
- 更新于 : 2026-05-15 10:57:13
- 链接: https://blog.lxiol.cn/2026/05/15/Qwen3-TTS-oMLX-三秒钟语音克隆又快了一步/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。