架构天花板:基于LangGraph的生产级Harness执行层——Sub-Agent深度拆解
本文转载自微信公众号,查看原文
FSAC未来超级架构师
架构师总动员
实现架构转型,再无中年危机
尼恩说在前面
在45岁老架构师尼恩的读者交流群 (50+人)里,最近不少小伙伴拿到了阿里、滴滴、极兔、有赞、希音、百度、字节、网易、美团这些一线大厂的面试入场券,恭喜各位!前两天就有个小伙伴面腾讯, 问到 “ 听说过Harness Agent 吗?你们怎么实现 Harness Agent 的? ” 的场景题 ,小伙伴没有一点概念,导致面试挂了。小伙伴 没有看过系统化的 答案,回答也不全面 ,so, 面试官不满意 , 面试挂了。小伙伴找尼恩复盘, 求助尼恩。通过这个 文章, 这里 尼恩给大家做一下 系统化、体系化的梳理,写一个系列的文章组成 尼恩编著 《Harness 架构与源码 学习圣经》 深入剖析 Harness AI 平台级 架构的 架构思维与 核心源码,使得大家可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流” 。同时,也一并把这个题目以及参考答案,收入咱们的 《尼恩Java面试宝典PDF》V176版本,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
尼恩编著 《Harness 架构与源码 学习圣经》
第一章: 什么是 Harness架构?2026年AI核心范式解析 : Harness架构与Agent工程化 具体文章: 54k+Star 爆火!AI 框架 新王者 Harness Agent 来了!尼恩 来一次Harness穿透式解读第二章: Harness架构 与 LangChain、LangGraph 三者联动 的底层逻辑 具体文章: Harness架构 与 LangChain、LangGraph 三者联动 的底层逻辑第三章: DeerFlow 源码 14层Middleware 源码解析 ,又一个 “洋葱责任链模式” 架构思维 的 经典案例 具体文章: DeerFlow 源码 14层Middleware 源码解析 ,又一个 “洋葱责任链模式” 架构思维 的 经典案例第四章: LangChain 超底层 四大设计模式 Design Patterns ,架构师 的 必备 内功,毒打面试官 具体文章: LangChain 超底层 四大设计模式 Design Patterns ,架构师 的 必备 内功,毒打面试官第五章:Harness宏观架构:基于 PPAF 思维 & REPL 思维,完成 Lead-Agent和Sub-Agent深度拆解具体文章: 第五章:Harness宏观架构:基于 PPAF 思维 & REPL 思维,完成 Lead-Agent和Sub-Agent深度拆解第六章:Harness宏观架构:DeerFlow 2.0 断点续跑机制 架构设计与实现 具体文章: Harness宏观架构:DeerFlow 2.0 断点续跑机制 架构设计与实现第七章: Harness 平台实战: 用 DeerFlow 构建 一个企业自己的 Manus 平台( 企业长任务智能体平台) 具体文章: Harness 平台实战: 用 DeerFlow 构建 一个企业自己的 Manus 平台( 企业长任务智能体平台)第八章: Harness 超牛逼的 三级记忆架构 上下文+历史分层+事实列表 ! 落地价值 逆天!! 具体文章: Harness 超牛逼的 三级记忆架构 上下文+历史分层+事实列表 ! 落地价值 逆天!!第九章: Harness 顶级架构:DeerFlow 2.0 沙盒 Sandbox 架构设计、Sandbox 源码深度解析(史上最深 、价值 逆天) 具体文章: Harness 顶级架构:DeerFlow 2.0 沙盒 Sandbox 架构设计、Sandbox 源码深度解析(史上最深 、价值 逆天)第10章: 顶奢RAG架构之, 必不可少的 RAG评估体系:7大核心指标落地优化,让RAG从Demo走向生产 【RAG评估、RAG度量指标】顶奢RAG架构之, 必不可少的 RAG评估体系:7大核心指标落地优化,让RAG从Demo走向生产 full - 技术自由圈第11章:Harness架构 :基于LangGraph的生产级Super Agent驾驭层实现 / DeerFlow 2.0 的 lead_agent 任务总调度 架构设计与实现解析Harness架构 : DeerFlow 2.0 的 lead_agent 任务总调度 架构设计与实现解析第十二章: Harness 具体应用:AI编程王炸组合:顶级三剑客 OpenSpec 定方向,Superpowers定纪律,Harness定协同顶级三剑客 OpenSpec 定方向,Superpowers定纪律,Harness定协同第十三章: Harness 架构哲学和思维:架构思维、架构哲学、设计模式 大拆解、大总结、大提炼Harness 架构哲学和思维:架构思维、架构哲学、设计模式 大拆解、大总结、大提炼本文第十四章: 架构哲学和思维: Harness /ReAct /PlanExec /Reflect /混合范式 的 区别 架构哲学和思维: Harness /ReAct /PlanExec /Reflect /混合范式 的 区别第十五章: Harness 底层知识: MCP与FC的10大差别?Harness 怎么 用MCP与FC? Harness 底层知识: MCP与FC的10大差别?Harness 怎么 用MCP与FC?第16章: 架构天花板 :基于LangGraph的生产级 Harness 执行层 Sub-Agent 深度拆解 本文具体文章: 尼恩还在写, 本周发布第18章:Harness架构 核心一:断点续跑机制 的 架构设计 与底层源码分析 . 具体文章: 尼恩还在写, 本周发布第19章:Harness架构 核心二: XXX 具体文章: 尼恩还在写,后续发布估计有 10章以上,具体请关注技术自由圈。
架构天花板 :基于LangGraph的生产级 Harness 执行层 Sub-Agent 深度拆解
DeerFlow 的 Sub-Agent 体系:设计决策到执行引擎的完整闭环
相信做过 Agent 开发的小伙伴都懂这种痛: 一个 AI Agent 硬扛所有步骤,从数据爬取、清洗到校验、输出,跑一次要40多分钟, 中间还经常因为上下文溢出断思路,重试一次又是大半天。不是模型不行,是架构没找对路子。单线程串行执行的效率瓶颈, 大家 在实际跑复杂需求的时候,体会得太深了。一个 AI Agent 碰到多步骤、多依赖的活,硬扛下去不仅慢,还容易在中间环节断掉思路。DeerFlow 搞出这套 Sub-Agent 系统,其实就是奔着解绑来的。Lead Agent 退居幕后当指挥官 ,把大活拆成几块,分给专属的 Sub-Agent 并行去跑,最后再把碎片拼好交差。一条是设计决策链 ——Sub-Agent 为什么这么设计、怎么委派、委派出什么、怎么约束、怎么管理一条是运行机制链 ——执行引擎长什么样、任务怎么创建、问题怎么定位、跑在什么环境里、怎么执行、出问题怎么办。两条链首尾相接,构成从架构决策到底层执行的完整闭环。先从 Lead Agent 与 Sub-Agent 之间的关系讲起。
一、Harness 任务单层委派模型: 任务编排与执行的三条铁律
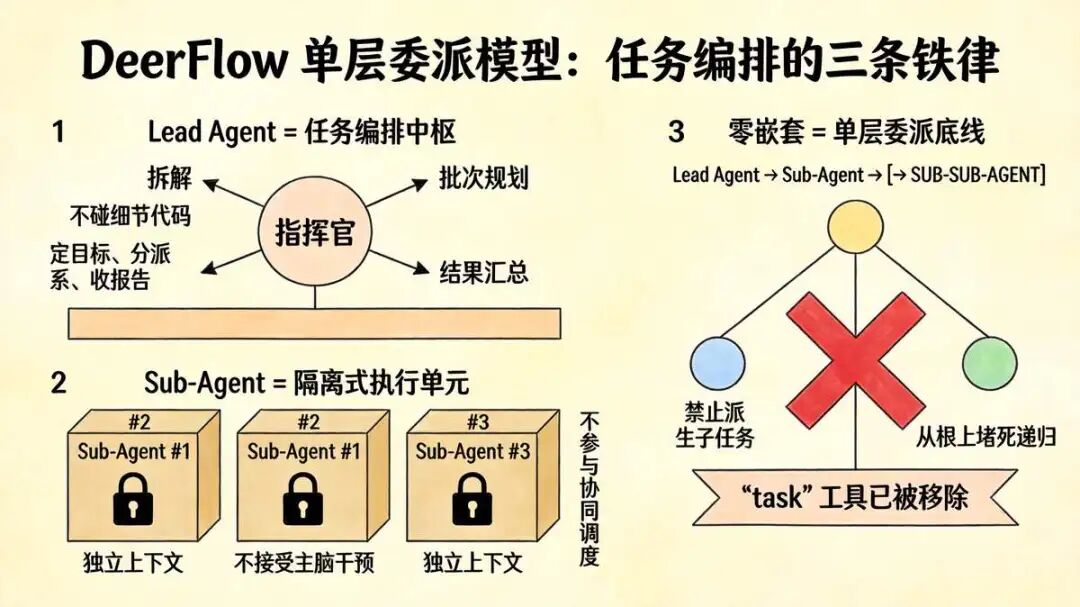 DeerFlow 里的 Lead Agent 就是大家平时直接对话+调用的主入口 ,Middleware 栈、需求澄清、Skill 技能这些重头戏全在它身上扛着。遇到能拆的复杂任务,它不自己硬算,直接调
DeerFlow 里的 Lead Agent 就是大家平时直接对话+调用的主入口 ,Middleware 栈、需求澄清、Skill 技能这些重头戏全在它身上扛着。遇到能拆的复杂任务,它不自己硬算,直接调 task 工具把子任务扔出去。尼恩有时候觉得,这种设计挺像狡猾狡猾的项目经理 ,自己不碰细节代码,只管定目标、分派系、收报告。两者的关系不用背太复杂的定义,拆开来就三条铁律:
- Lead Agent 是任务编排者 :核心职责全在拆解、批次规划、结果汇总上,执行节奏必须牢牢捏在自己手里,不能放权太彻底
- Sub-Agent 是专属执行者 :被关进独立隔离的上下文里单干,领了明确指令就去跑,中途别指望主脑来救场或插手
- 严格禁止嵌套调用 :子任务绝对不能再派生子任务,
task工具直接被踢出工具列表,这条路从根上堵死
这种任务委派模型,看着有点保守,其实救了大命。尼恩以前跟团队折腾过递归嵌套的方案,结果深度一失控,上下文窗口直接爆满,内存泄漏查得人头秃。这种 任务委派模型 ,是一种 单层 委派模型, 这种 Lead Agent 到 Sub-Agent 是单层委派, 这种单层委派,不是级联委派,不是 嵌套委派,强制扁平化,反而让系统稳住了。DeerFlow 确保整个体系只有 “Lead Agent(指挥官)→ Sub-Agent(执行者)” 这一层委派关系,不允许出现 “Lead Agent → Sub-Agent → 子 Sub-Agent” 的多层嵌套。DeerFlow 死守 “单层委派底线”, 不让 Sub-Agent 再派生新的 Sub-Agen ,彻底切断递归嵌套的可能,DeerFlow 死守 “单层委派底线” , 资源消耗可控了,调试路径也变直了,这才是生产环境最需要的东西。
二、第一步: Lead Agent 如何创建 Sub-Agent
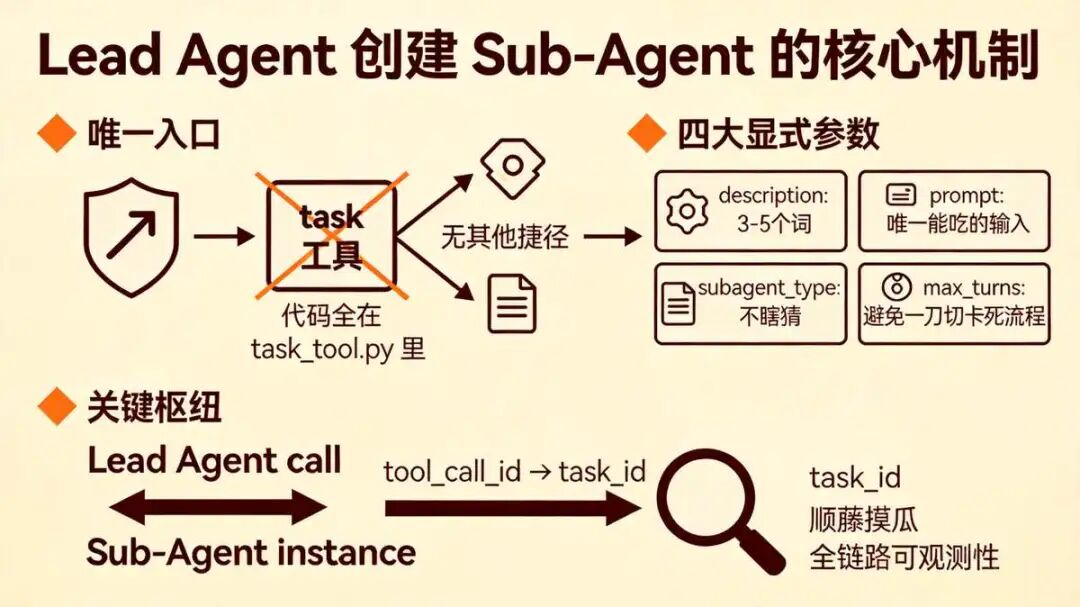 聊完委派关系,再看 Lead Agent 如何创建 Sub-Agent ?如何创建 SubAgent?
聊完委派关系,再看 Lead Agent 如何创建 Sub-Agent ?如何创建 SubAgent?task 工具是 Lead Agent 创建 Sub-Agent 的唯一入口,代码全塞在 task_tool.py 里,没有其他捷径。
三、 Sub-Agent 的分类:通用型 vs 命令型
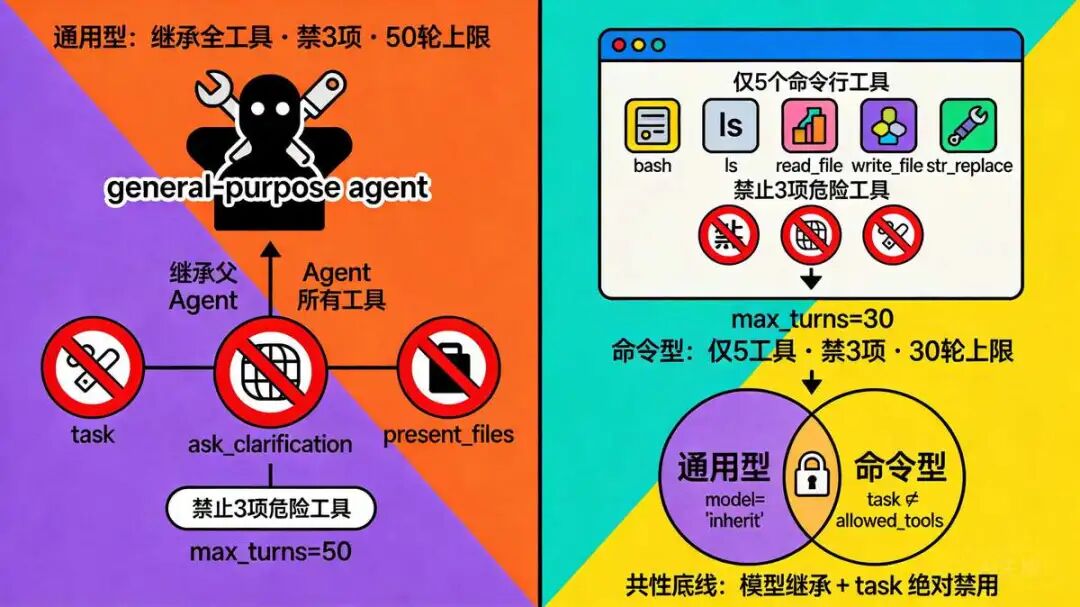 DeerFlow 内置的两种配置,全放在
DeerFlow 内置的两种配置,全放在 subagents/builtins/ 目录里。
- 通用型 (general-purpose)
- 命令型 (bash)
不是随便分的,是根据实际任务特征 推测 出来的。
尼恩提示:原文3w字以上, 超过平台限制, 此处省略 1000字,具体请参考 免费pdf。 完整版本,请参考 尼恩 免费百度网盘 免费pdf , 点赞收藏本文后 ,截图 找尼恩获取 __
四、 Sub-Agent 的 两道安全围栏:并发限制与超时保护
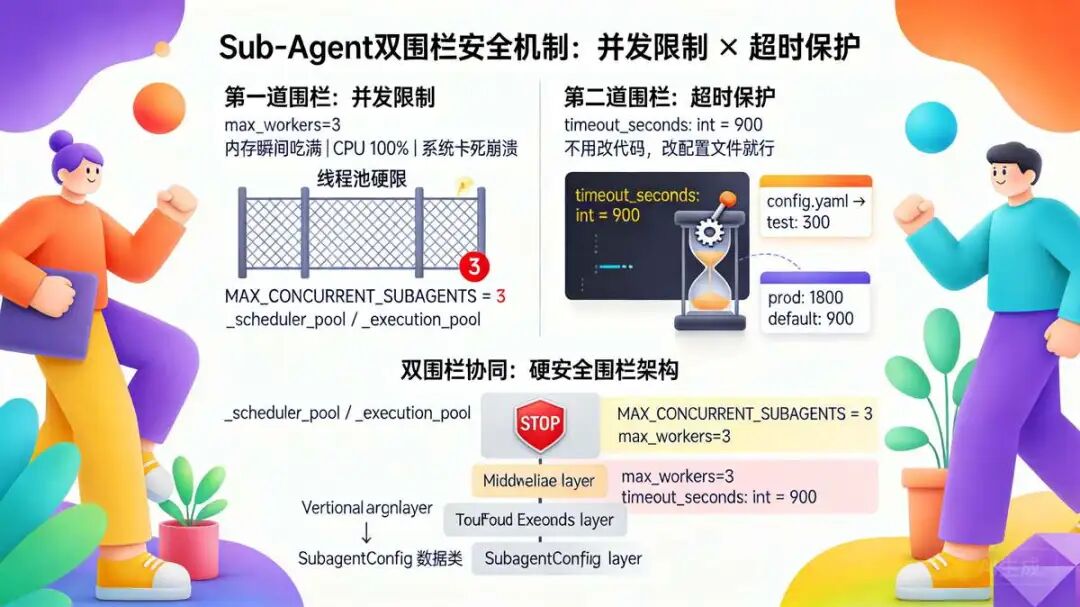 系统跑起来最怕的不是任务慢,是资源被吃干榨净, 导致 进程的 直接崩盘。Sub-Agent 这块加了并发限制 和超时限制 两道安全护栏,防的就是这个。
系统跑起来最怕的不是任务慢,是资源被吃干榨净, 导致 进程的 直接崩盘。Sub-Agent 这块加了并发限制 和超时限制 两道安全护栏,防的就是这个。
- 并发限制 = 不让同时干太多活,防炸内存
- 超时限制 = 不让一个活干太久,防卡死进程
尼恩提示:原文3w字以上, 超过平台限制, 此处省略 1000字,具体请参考 免费pdf。 完整版本,请参考 尼恩 免费百度网盘 免费pdf , 点赞收藏本文后 ,截图 找尼恩获取 __
五、父子 Agent 资源复用:沙箱共享与线程数据共享
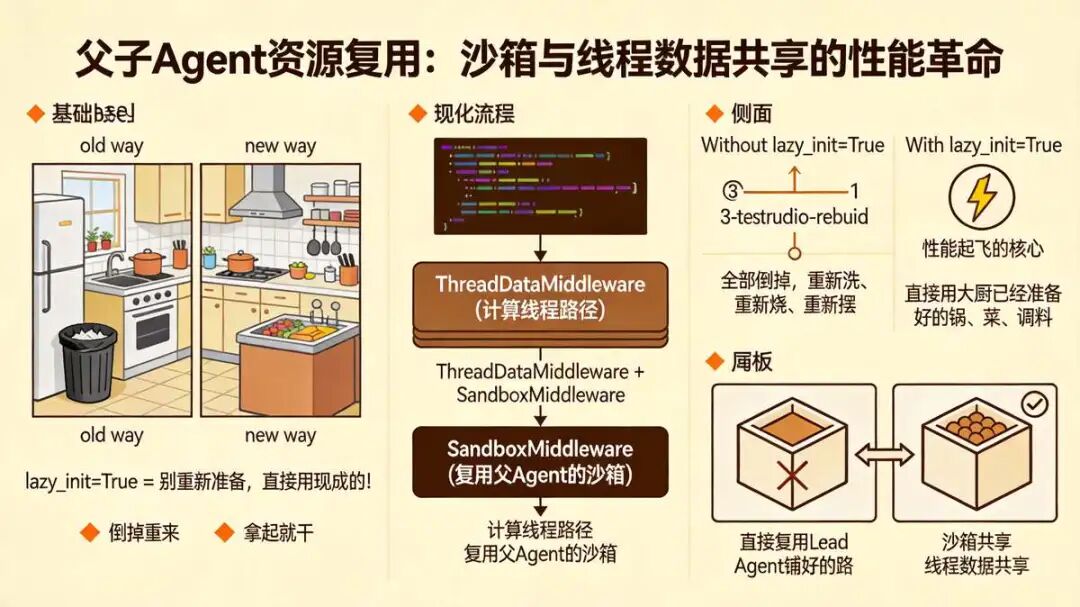 子任务(Sub-Agent)不重复造轮子,直接用父任务已经准备好的环境和文件,启动更快、更省资源。 _create_agent 方法中, Sub-Agent 装配了两个 中间件, ThreadDataMiddleware + ThreadDataMiddleware , 通过两个 中间件, 实现父子 沙箱共享与线程数据共享 :
子任务(Sub-Agent)不重复造轮子,直接用父任务已经准备好的环境和文件,启动更快、更省资源。 _create_agent 方法中, Sub-Agent 装配了两个 中间件, ThreadDataMiddleware + ThreadDataMiddleware , 通过两个 中间件, 实现父子 沙箱共享与线程数据共享 :
def _create_agent(self):
model = create_chat_model(name=model_name, thinking_enabled=False)
middlewares = [
ThreadDataMiddleware(lazy_init=True), # 计算线程路径
SandboxMiddleware(lazy_init=True), # 复用父 Agent 的沙箱
]
return create_agent(
model=model,
tools=self.tools,
middleware=middlewares,
system_prompt=self.config.system_prompt,
state_schema=ThreadState,
)
lazy_init=True 是这节的魂。懒加载 = 别重新准备,直接用现成的! 以前没开这个参数:
- 大厨刚把锅烧热、菜洗好、调料摆好
- 帮厨一来,全部倒掉,重新洗、重新烧、重新摆
- 慢到爆炸(1~2 秒才能开始干活)
现在开了 lazy_init=True:
- 帮厨一来,直接用大厨已经准备好的锅、菜、调料
- 拿起就干,几百毫秒搞定
这就是性能起飞的核心 。lazy_init=True , 告诉 Middleware 别瞎折腾初始化,直接复用 Lead Agent 铺好的路:
- 沙箱共享 :两边操作同一个沙箱环境,文件系统状态实时互通,子任务跑起来直接能拿到父级生成的文件
- 线程数据共享 :路径计算、上传文件列表直接继承,省掉重复扫描和重建的开销,启动速度肉眼可见变快
六、子 Agent 上下文隔离:自包含消息与链路跟踪
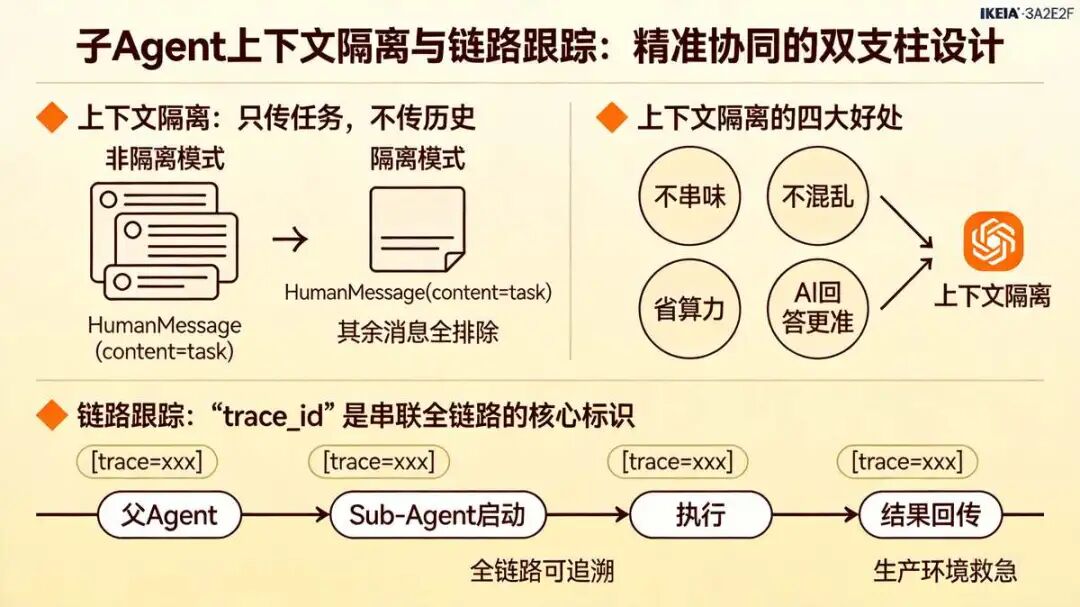 有共享的部分, 也有隔离的部分。多 AI 子助手(Sub-Agent)协作时的两个核心设计:上下文隔离 + 链路追踪 。每个 Sub-Agent 启动,只认一条
有共享的部分, 也有隔离的部分。多 AI 子助手(Sub-Agent)协作时的两个核心设计:上下文隔离 + 链路追踪 。每个 Sub-Agent 启动,只认一条 HumanMessage,其他的全当不存在:
def _build_initial_state(self, task: str) -> dict[str, Any]:
state: dict[str, Any] = {
"messages": [HumanMessage(content=task)],
}
if self.sandbox_state is not None:
state["sandbox"] = self.sandbox_state
if self.thread_data is not None:
state["thread_data"] = self.thread_data
return state
子 Agent 上下文隔离 ,就是 只给子 AI 传一条任务消息,别的啥都不传。
七、上下文隔离的目标: 提升 推理质量与可重放
 为什么 Sub-Agent 拿不到 Lead Agent 的完整对话历史。 这难道不是信息丢失吗?启动时只喂一条
为什么 Sub-Agent 拿不到 Lead Agent 的完整对话历史。 这难道不是信息丢失吗?启动时只喂一条 HumanMessage,内容就是 task 工具传进来的 prompt。其他三类东西一律屏蔽,Lead Agent 的历史、其他子任务的中间产出、用户最初的聊天上下文,全被挡在外面。隔离带来的收益,实打实盖过了信息缺失的代价。 Sub-Agent 专注单点的 Agent,推理质量和执行效率,绝对吊打被海量上下文糊脸的模型。大家想想,让 Sub-Agent 去搜 Python 异步编程最佳实践,它真需要知道用户之前问没问过天气,或者另一个子任务在不在编译代码吗。 不需要。Lead Agent 的完整对话历史 , 这些杂音只会挤占 Sub-Agent 上下文窗口,干扰核心指令。这就逼着Sub- Agent 的 prompt 必须自包含 。
自包含 是什么意思自包含 = 一句话 / 一段指令本身,自带所有必要背景、条件、要求,不用看聊天记录、不用看上下文、不用猜前因后果,单独拿出来就能直接看懂、直接执行。 __
八、子 Agent 配置注册表:默配置 与运行时覆盖
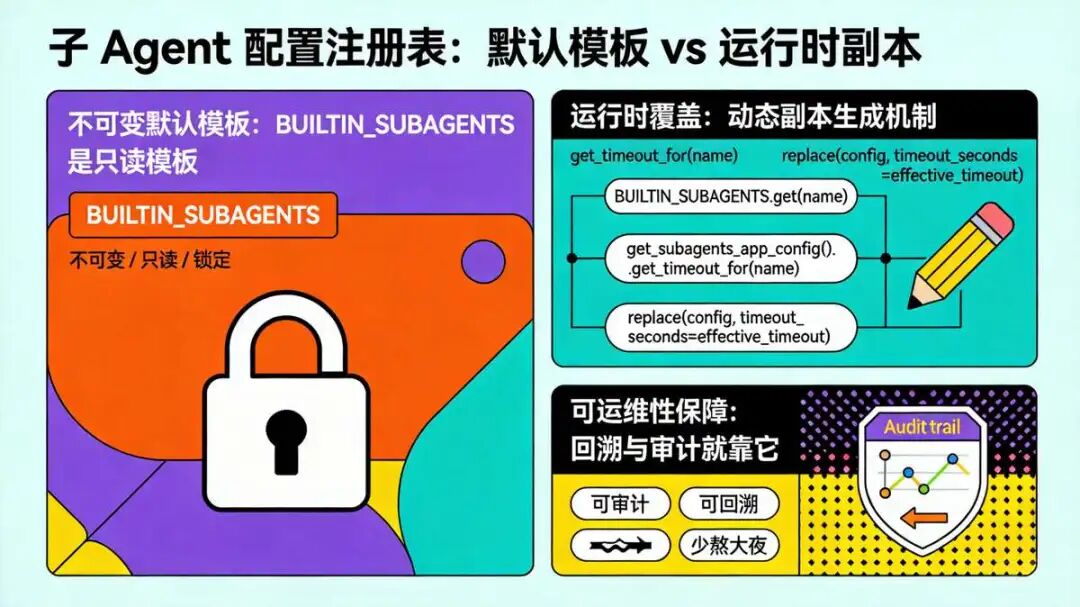 子 Agent 配置注册表 有点 特殊:
子 Agent 配置注册表 有点 特殊:
def get_subagent_config(name: str) -> SubagentConfig | None:
config = BUILTIN_SUBAGENTS.get(name)
if config is None:
return None
# 支持 config.yaml 的运行时覆盖
app_config = get_subagents_app_config()
effective_timeout = app_config.get_timeout_for(name)
if effective_timeout != config.timeout_seconds:
config = replace(config, timeout_seconds=effective_timeout)
return config
子 Agent 的配置,有默认值,但运行时可以改;而且改的时候**不破坏原始配置,安全、不乱、可追溯。** 可以理解成:
- 默认配置 = 模板(永远不动)
- 运行时配置 = 临时复印件(随便改)
原始配置对象绝对不碰,只生成新副本覆盖目标字段。配置被改乱了还能回溯,审计日志打起来清清楚楚。线上出事故的时候,这套机制能少熬多少大夜。
九、lazy_init 深挖:实现Middleware 初始化阶段 I/O 归零
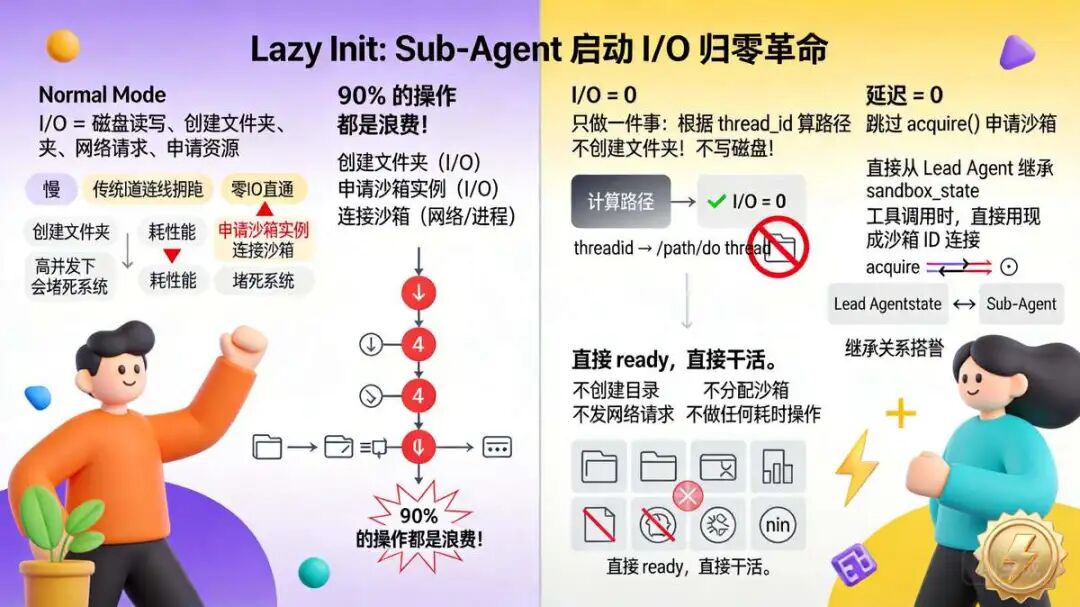 第五节提过的
第五节提过的 lazy_init=True,尼恩觉得值得单拎出来再盘一遍。这参数背后全是性能优化的狠活。lazy_init = 能不做的事,绝对不提前做;必须做的事,拖到最后一秒再做。 目的:让 Sub-Agent 启动超级快,初始化完全不做磁盘 / 网络操作(I/O 归零)。
尼恩提示:原文3w字以上, 超过平台限制, 此处省略 1000字,具体请参考 免费pdf。 完整版本,请参考 尼恩 免费百度网盘 免费pdf , 点赞收藏本文后 ,截图 找尼恩获取 __
十、trace_id 的生命周期:从请求接受到排障检索的六步流转
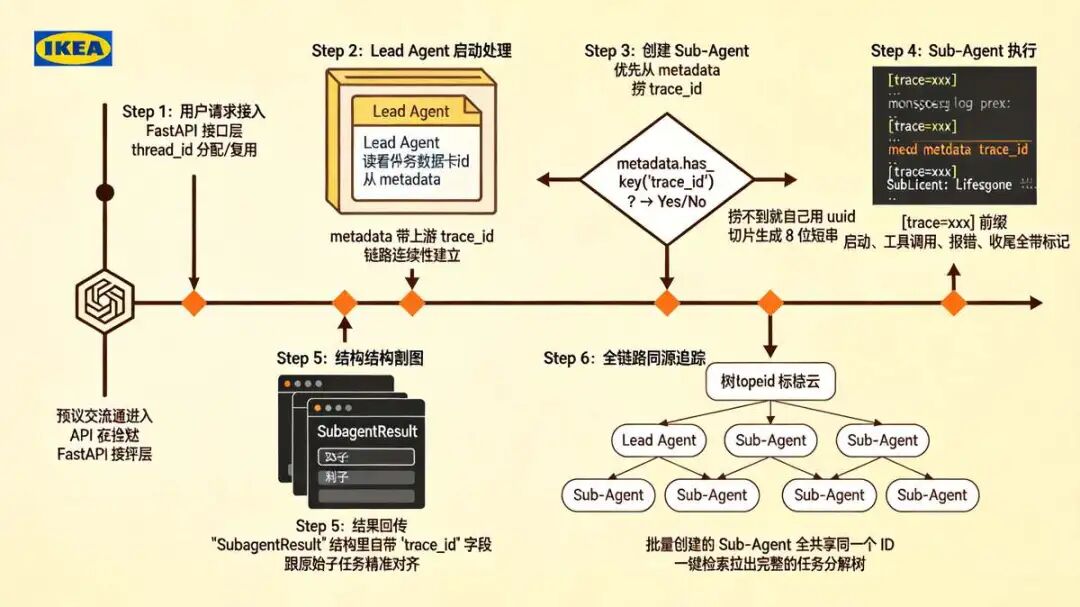
trace_id 的生命周期贯穿整条请求链路,不摸清它,运维和排障就是纯瞎蒙。尼恩把它的流转路径拆成六步,大家顺着看就明白了:
- 用户请求接入 :流量打到 FastAPI 接口层,框架分配或复用
thread_id,给会话打基础标签 - Lead Agent 启动处理 :主脑开始跑需求,运行时
metadata里可能已经带着上游塞进来的trace_id - 创建 Sub-Agent :Lead Agent 调
task工具,内部建SubagentExecutor,优先从metadata捞trace_id,捞不到就自己用uuid切片生成 8 位短串 - Sub-Agent 执行 :整个跑动过程里,所有日志统一挂上
[trace=xxx]前缀,启动、工具调用、报错、收尾全带标记 - 结果回传 :
SubagentResult结构里自带trace_id字段,Lead Agent 靠它把执行结果跟原始子任务精准对齐 - 全链路同源追踪 :同一轮对话里批量创建的 Sub-Agent 全共享同一个 ID,日志系统里一键检索就能拉出完整的任务分解树
生产环境里,运维拿一个 trace_id 就能还原整条执行线。谁先跑、谁超时、谁报错,一清二楚。瓶颈在哪、资源卡在哪,数据说话,不用猜。
十一、System Prompt 的分层策略:重型指挥 vs 极简执行
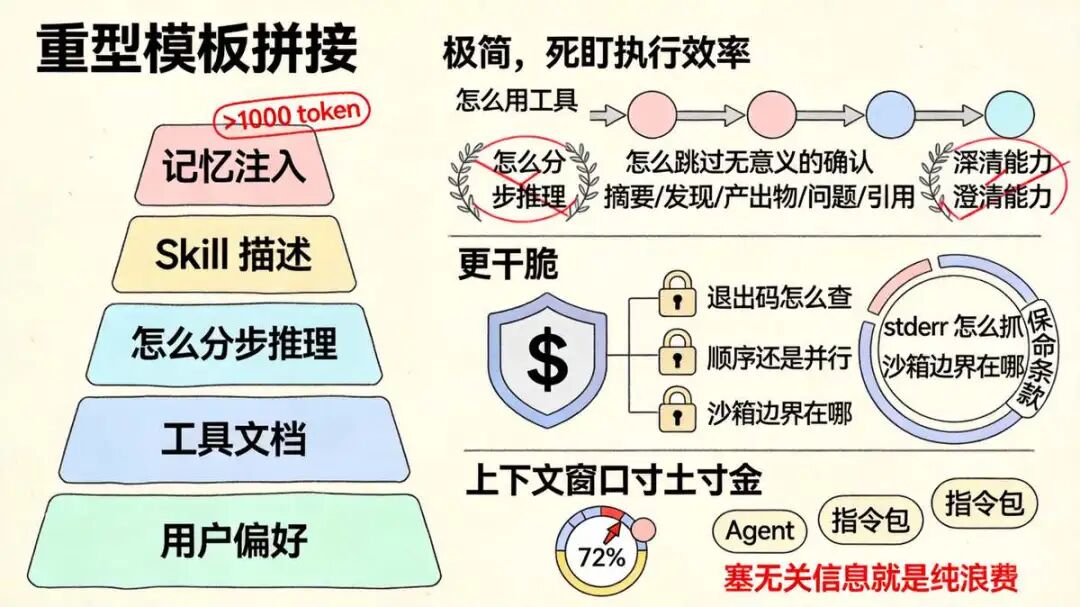 底层框架共用,但 system prompt 的写法天差地别。按需裁剪,绝不贪多,这才是上下文窗口的正确用法。Lead Agent 的 system prompt :重型模板拼接。记忆注入、Skill 描述、工具文档、用户偏好全往上堆。长度轻松破千 token,目的就一个,撑起复杂交互和全局拆解能力。general-purpose 类型 Sub-Agent 的 system prompt :极简,死盯执行效率。教模型怎么用工具、怎么分步推理、怎么跳过无意义的确认。附带标准输出模板,要求按摘要、发现、产出物、问题、引用这种结构吐结果。记忆注入和 Skill 描述全砍,澄清能力也没有,收到
底层框架共用,但 system prompt 的写法天差地别。按需裁剪,绝不贪多,这才是上下文窗口的正确用法。Lead Agent 的 system prompt :重型模板拼接。记忆注入、Skill 描述、工具文档、用户偏好全往上堆。长度轻松破千 token,目的就一个,撑起复杂交互和全局拆解能力。general-purpose 类型 Sub-Agent 的 system prompt :极简,死盯执行效率。教模型怎么用工具、怎么分步推理、怎么跳过无意义的确认。附带标准输出模板,要求按摘要、发现、产出物、问题、引用这种结构吐结果。记忆注入和 Skill 描述全砍,澄清能力也没有,收到 prompt 就得闭眼跑完。bash 型 Sub-Agent 的 system prompt :更干脆。只聊命令执行最佳实践。退出码怎么查、stderr 怎么抓、顺序还是并行、沙箱边界在哪。保命条款写清楚,执行就不会翻车。分层设计就图一件事。每种 Agent 只背自己该背的指令。上下文窗口寸土寸金,塞无关信息就是纯浪费。
十二、SubAgent的 工具权限 围栏策略:黑名单 VS 白名单
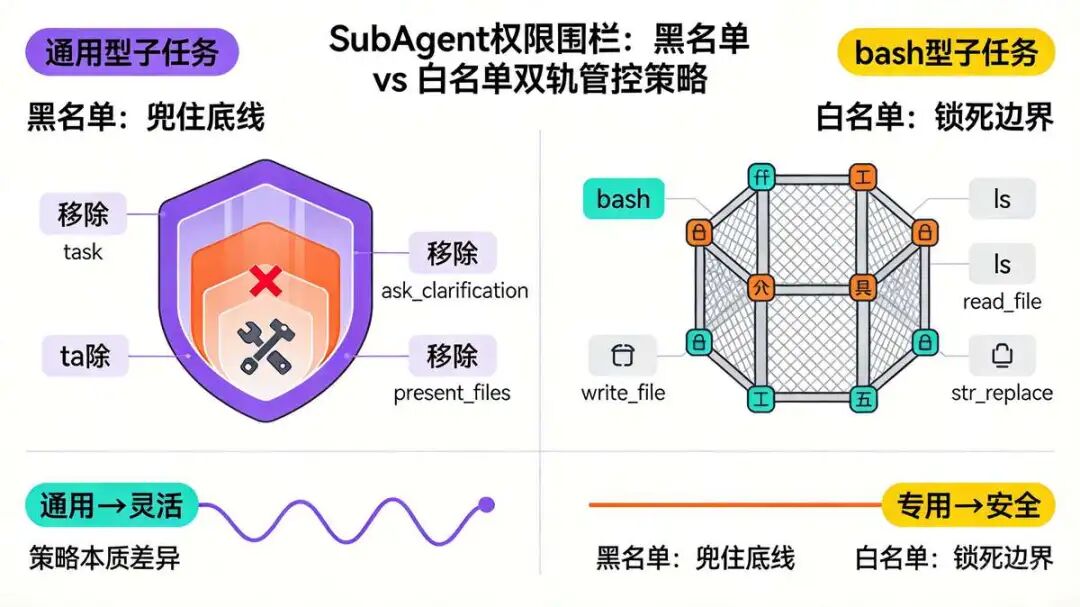
tools=None 看着像全继承,其实底层过滤逻辑卡得很死。DeerFlow 对能力边界的管控,全藏在这。核心逻辑就两步。
- 先拿 Lead Agent 工具列表的完整副本,再把
disallowed_tools里的三个直接剔除。
三个工具 被 移除:
- 移除
task工具:死守不递归底线。
开了口子深度就失控,资源消耗指数级飙升,单层委派是铁律
- 移除
ask_clarification工具:Sub-Agent 没资格直接跟用户对话。
需求模糊只能硬猜或标注不确定性,这也反向要求 Lead Agent 的 prompt 必须自包含
- 移除
present_files工具:文件展示是 Lead Agent 的专属活儿。
子任务只能在沙箱里读写,对外输出必须经过主脑统一包装,交互体验才连贯
十三、Sub-Agent 状态机:五状态不可逆流转
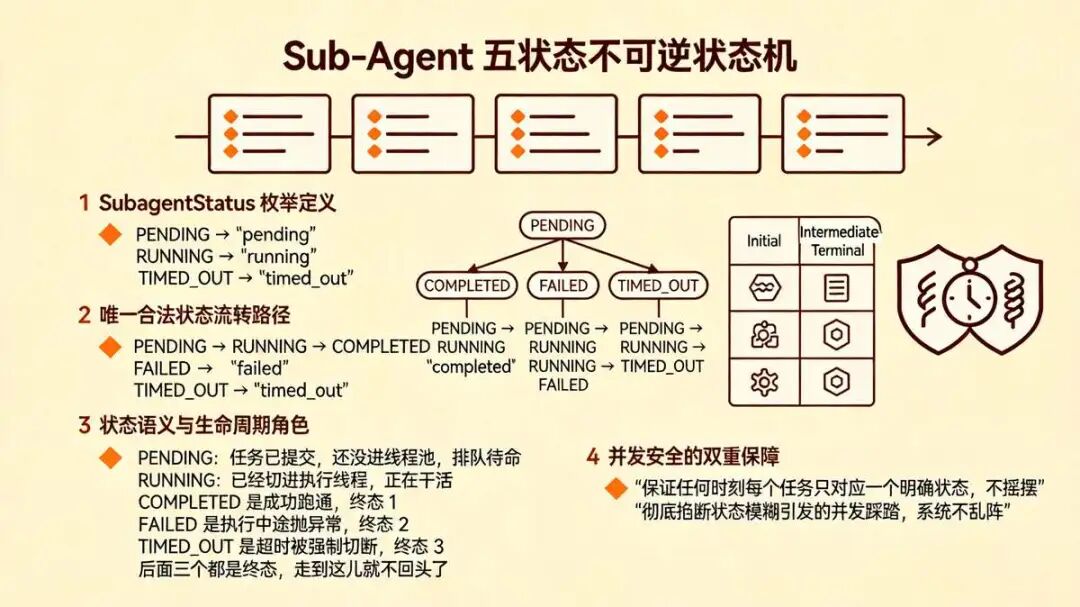 每个 Sub-Agent 任务从提交到收尾,生命周期必须清清楚楚。并发环境里最怕状态模糊,一模糊就出脏数据。
每个 Sub-Agent 任务从提交到收尾,生命周期必须清清楚楚。并发环境里最怕状态模糊,一模糊就出脏数据。SubagentStatus 枚举把这条线锁死,定义直接摆出来:
class SubagentStatus(Enum):
PENDING = "pending"
RUNNING = "running"
COMPLETED = "completed"
FAILED = "failed"
TIMED_OUT = "timed_out"
状态转换路径就这一条,没多余分支,大家记牢节奏:
PENDING → RUNNING → COMPLETED
→ FAILED
→ TIMED_OUT
逐个拆开看,不用死背,跑通了就懂:
PENDING:任务已提交,还没进线程池,排队待命RUNNING:已经切进执行线程,正在干活COMPLETED是成功跑通,终态 1FAILED是执行中途抛异常,终态 2TIMED_OUT是超时被强制切断,终态 3
后面三个都是终态,走到这儿就不回头了。这设计的核心目的就两条:
- 保证任何时刻每个任务只对应一个明确状态,不摇摆
- 彻底掐断状态模糊引发的并发踩踏,系统不乱阵
十四、执行结果记录:SubagentResult 关键信息全记录
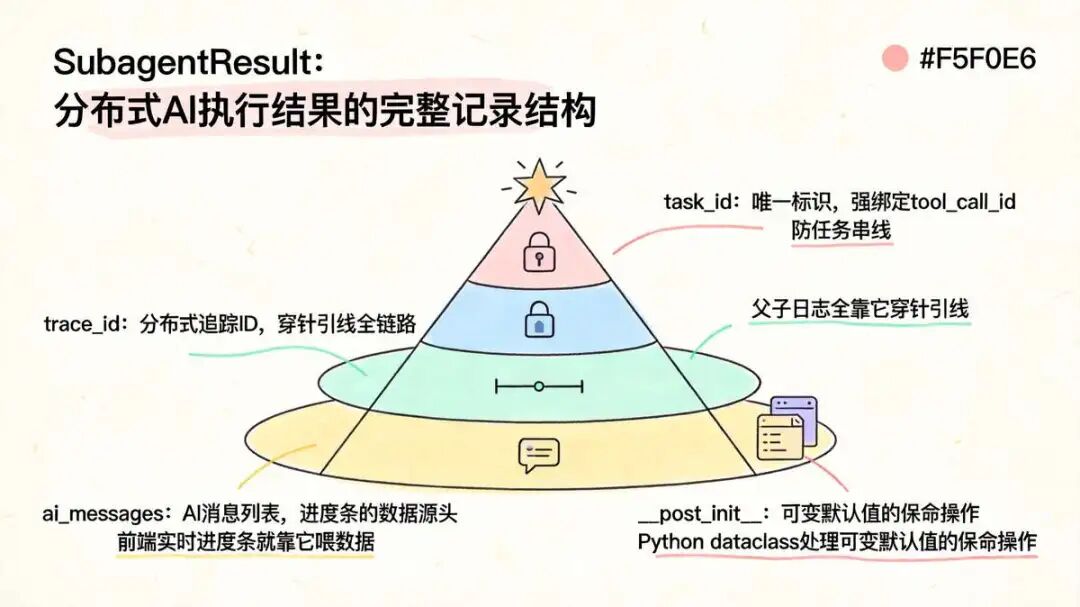
SubagentResult 就是 Sub-Agent 执行的完整 结果记录。从起步到收尾,关键信息全记在这,后面查问题、算耗时、看性能,全靠它兜底。
十五、三大 ID 关系:thread_id → trace_id → task_id 的层级包含
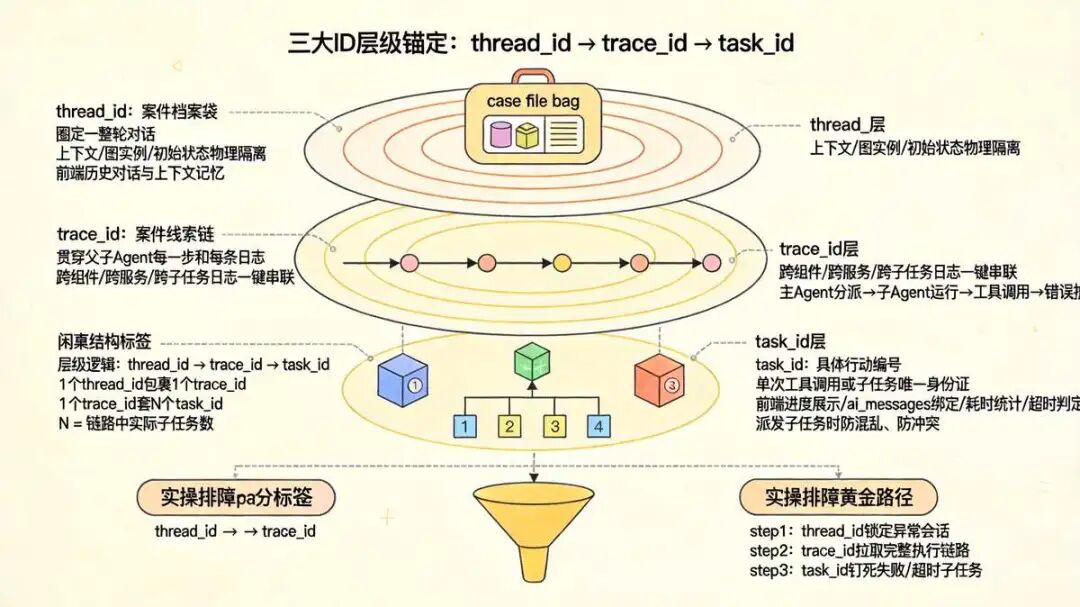 多智能体系统里,这三个 ID 就是实操里的定位锚点。尼恩有时候觉得,把它们的关系理不清,排障就是纯靠运气。字段职责独立,但层级咬合得很紧,拆开看就明白。
多智能体系统里,这三个 ID 就是实操里的定位锚点。尼恩有时候觉得,把它们的关系理不清,排障就是纯靠运气。字段职责独立,但层级咬合得很紧,拆开看就明白。
三id 字段的核心定义
1. thread_id(线程 ID / 会话 ID) 这是会话级的隔离标识,属于用户对话层面的 ID,不碰任务逻辑。用户每次发起新请求,系统就生成一个全局唯一的 thread_id。核心作用就是圈定一整轮对话,确保不同用户的上下文、图执行实例、初始状态物理隔离。实操里它粒度最大,一次对话可能裹着 N 次调用、N 条 trace、N 个任务。前端展示历史对话和上下文记忆,全指着它干活。2. trace_id(分布式追踪 ID) 全链路排查的上帝视角标识。贯穿父子 Agent 的每一步和每条日志。不管任务拆多细、跨多少组件,只要捏住这个 trace_id,整条请求链的日志就能一键串联。实操中它对应一次完整调用链。排查问题时它是真神器。搜一下,主 Agent 怎么分派、子 Agent 怎么跑、工具怎么调、报错怎么抛,全流程透明。3. task_id(任务唯一标识) 具体任务单元的执行标识,单次工具调用或子任务的唯一身份证。DeerFlow 里它通常由 tool_call_id 传入。核心作用就是跟 Lead Agent 的工具调用对齐,派发子任务时防混乱、防冲突。实操里它粒度最小,一个任务一个 ID,干完就止。前端实时进度展示、ai_messages 绑定、耗时统计、超时判定,全绑在它身上。实操排障的常规路径尼恩顺一下:
- 先拿 thread_id 锁定异常会话,看谁的问题
- 再拿 trace_id 拉完整执行链路,看哪段断了
- 最后拿 task_id 钉死失败或超时的具体子任务,精准爆破
十七、asyncio.run() 桥接:让同步线程池无缝跑异步逻辑
execute 方法看着就几行,实则是整个引擎的同步异步桥。一边是同步线程池,一边是异步 Agent 逻辑,全凭它衔接。
def execute(self, task: str, result_holder: SubagentResult | None = None) -> SubagentResult:
try:
# 关键:用asyncio.run()运行异步方法,创建全新事件循环
return asyncio.run(self._aexecute(task, result_holder))
except Exception as e:
logger.exception(f"[trace={self.trace_id}] execution failed")
# 异常处理:确保无论如何都返回一个SubagentResult,不搞空值
if result_holder is not None:
result = result_holder
else:
result = SubagentResult(
task_id=str(uuid.uuid4())[:8],
trace_id=self.trace_id,
status=SubagentStatus.FAILED,
)
result.status = SubagentStatus.FAILED
result.error = str(e)
result.completed_at = datetime.now()
return result
重点卡死一个点。为啥非用 asyncio.run() 而不是直接 await。因为线程池里的线程压根没事件循环,await 直接歇菜。asyncio.run() 会原地起个新循环,专门跑异步代码。这么一桥接,Sub-Agent 就能无缝跑 MCP 工具这类异步逻辑,不用改底层代码,同步池里照样转得飞起。
十六、SubagentExecutor 双线程池架构:调度和执行彻底拆开
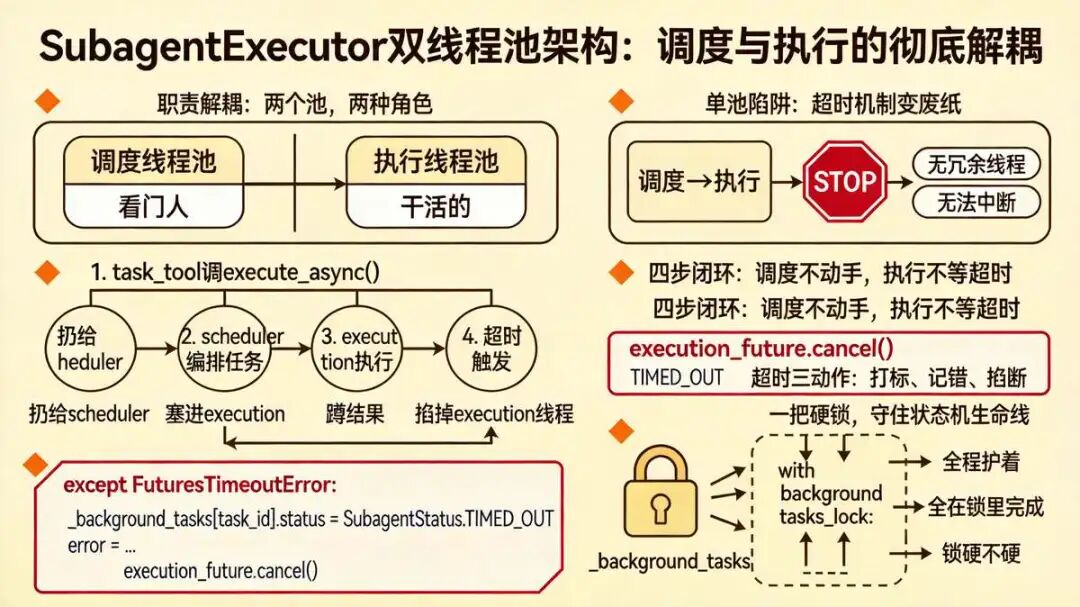
SubagentExecutor 最亮眼的设计,就是把调度和执行彻底拆开。这也是它能实现可靠超时控制的底牌。
尼恩提示:原文3w字以上, 超过平台限制, 此处省略 1000字,具体请参考 免费pdf。 完整版本,请参考 尼恩 免费百度网盘 免费pdf , 点赞收藏本文后 ,截图 找尼恩获取 __
十八、SubAgent 任务轮询:状态查询和进度推送
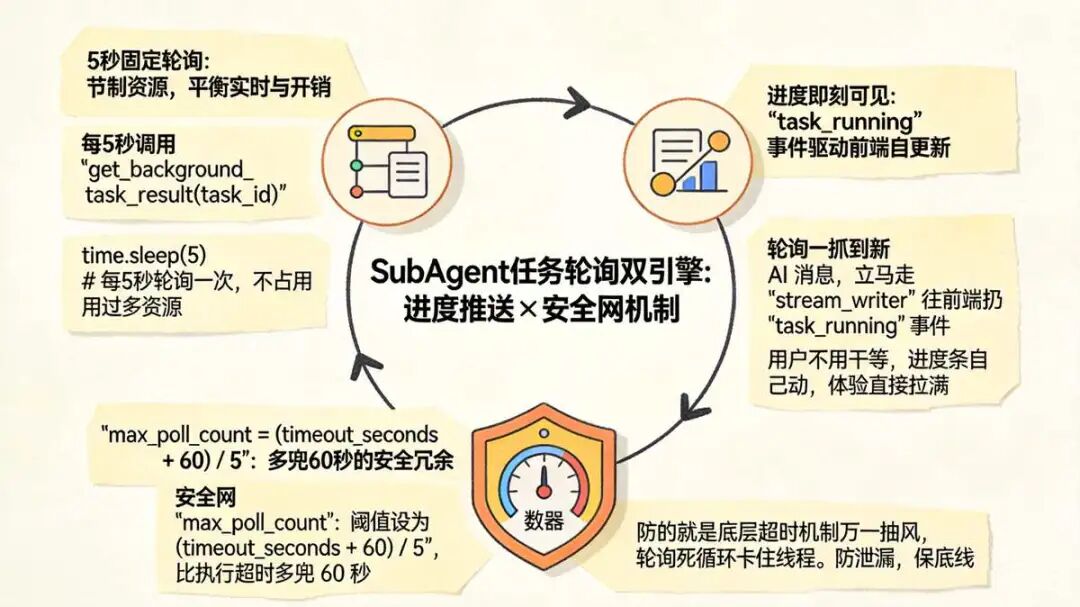
task_tool 里藏了个轮询循环。每 5 秒扫一次状态,等终态是一方面,推进度是另一方面。
十九、SubAgent 任务清理:只看终态防止误删
生产环境里内存泄漏是隐形杀手。任务跑完必须从全局字典 _background_tasks 里踢出去,不然日积月累直接吃满 OOM。清理逻辑看着短,细节全在判断里:
def cleanup_background_task(task_id: str) -> None:
with _background_tasks_lock:
result = _background_tasks.get(task_id)
if result is None:
return # 任务不存在,直接返回,避免报错
# 关键检查:只有终态任务才清理,防止误删运行中任务
is_terminal_status = result.status in {
SubagentStatus.COMPLETED,
SubagentStatus.FAILED,
SubagentStatus.TIMED_OUT,
}
if is_terminal_status or result.completed_at is not None:
del _background_tasks[task_id]
核心避坑点死盯终态。这个判断能掐死一种竞态条件。如果轮询线程抢在 scheduler 线程更新状态前就动手清理,很可能把一个还在跑的条目误删。状态更新直接扑街。卡住终态才删,确保清理动作绝对安全,不干扰执行中的活。
二十、SubAgent 三层异常兜底:异常也记进 SubagentResult
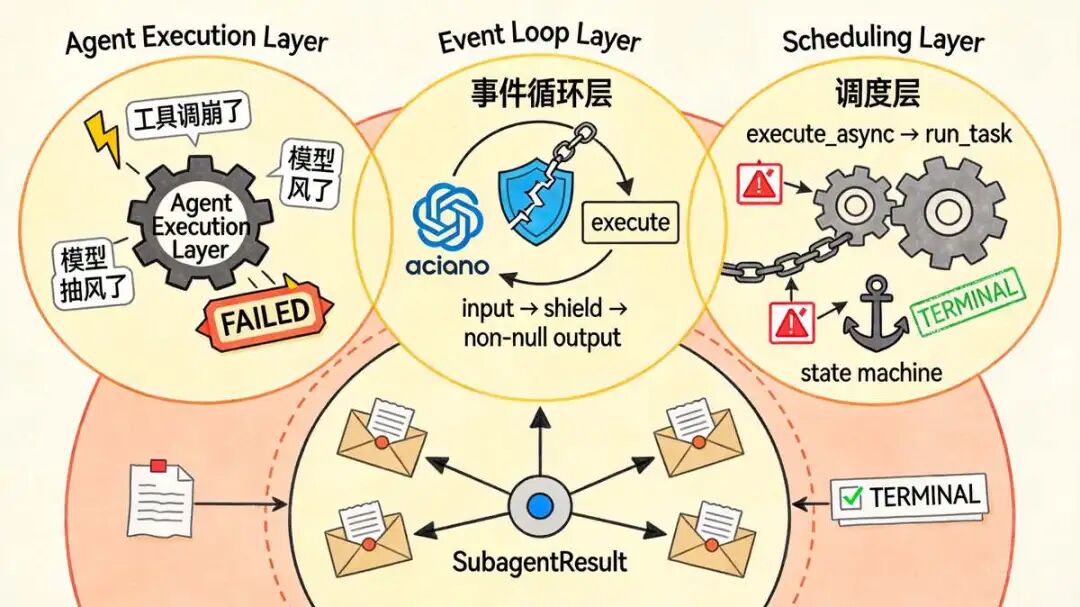 Sub-Agent 的错误处理,没搞一刀切的
Sub-Agent 的错误处理,没搞一刀切的 try-except 包圆。尼恩觉得,生产级代码必须织网。这里铺了三层防护,任何异常都漏不掉,任务绝不会凭空蒸发。
- Agent 执行层 :
_aexecute里兜底。
工具调崩了、模型抽风了,全在这捕获,直接打标 FAILED
- 事件循环层 :
execute里兜底。
asyncio.run() 自己起不来、循环启动失败,全在这拦截,不走空值,稳出结果
- 调度层 :
execute_async的run_task里兜底。
小结
DeepAgents 的 Sub-Agent 体系,骨子里是设计约束与运行时可靠性交织在一起的完整闭环。每一层都在高效、稳定、可扩展这三个靶心上做取舍。尼恩写这一整篇最深的体会就一句:设计上想清楚的,代码里全守住了。从委派模型到线程池,从上下文隔离到异常兜底,每一处都不是拍脑袋,是从生产环境的卡顿、超时和内存泄漏里逼出来的。executor.py 不到 500 行,不是炫技,是真的够用了。够用,就是生产级代码最好的状态。
说在最后:有问题找45岁老架构取经
尼恩提示: 要拿到 高薪offer, 或者 要进大厂,必须来点 高大上、体系化、深度化 的答案, 整点技术狠活儿。只要按照上面的 尼恩团队梳理的 方案去作答, 你的答案不是 100分,而是 120分。 面试官一定是 心满意足, 五体投地。按照尼恩的梳理,进行 深度回答,可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流” ,然后实现”offer直提”。在面试之前,建议大家系统化的刷一波 5000页《尼恩Java面试宝典PDF》,里边有大量的大厂真题、面试难题、架构难题。很多小伙伴刷完后, 吊打面试官, 大厂横着走。在刷题过程中,如果有啥问题,大家可以来 找 40岁老架构师尼恩交流。另外,如果没有面试机会, 可以找尼恩来改简历、做帮扶。 刚刚一个 卖肥料一年,上岸 架构师 。月薪3w 比 卖肥料 香 太多!Java架构+AI架构,帮助31岁小伙伴 大逆袭成了: 卖肥料一年,上岸 架构师 。月薪3w 比 卖肥料 香 太多!Java架构+AI架构,帮助31岁小伙伴 大逆袭狠狠卷,实现 “offer自由” 很容易的, 前段时间一个武汉的跟着尼恩卷了2年的小伙伴, 在极度严寒/痛苦被裁的环境下, offer拿到手软, 实现真正的 “offer自由” 。
下面的案例, 通过 尼恩 三高架构 +尼恩 AI架构 +尼恩 架构陪跑, 实现 P7 升级
小伙赶在32岁 末班车,拿到 京东P7(60w), 撬开P8(年薪100W)通道, 逆天改命了!!!
逆袭 100万 P8。37岁 空窗6个月,靠 Java+AI双栖架构, 2个月上岸 100w年薪到手,职业重生+逆天改命!
一飞冲天, 逆 首席: 37 岁 借力 Java+AI 逆袭 首席架构 , 年薪80W+太香了
31岁 /专科 升架构成功, 收10个offer 变 offer 皇帝 !! 下一步,直冲100W
奇迹 : 一年 涨2倍, 年薪 60W 梦想实现 。 接下来,开启 40岁之前的 年薪 200W 梦想
28岁/6年/被裁1年,收 3 大厂offer , 成 大厂 皇后 。2本学历 51W 年薪,惊天 逆涨,涨薪2倍,大厂皇后
涨薪传奇: 18k->38K , 单月暴20K,32岁小伙伴 2个月时间年薪 翻1.5倍 ,一步登天+逆天改命
低学历 传奇:29岁6年专套本,受够了外包,狠卷3个月逆袭大厂 涨 1倍, 逆天改命
极速上岸: 被裁 后, 8天 拿下 京东,狠涨 一倍 年薪48W, 小伙伴 就是 做对了一件事
外包+二本 进 美团: 26岁小2本 一步登天, 进了顶奢大厂( 美团) , 太爽了
超牛的Java+Al 双栖架构: 34岁无路可走,一个月翻盘,拿 3个架构offer,靠 Java+Al 逆天改命!!!java+AI 逆袭2::3年 程序媛 被裁, 25W-》40W 上岸, 逆涨60%。 Java+AI 太神了, 架构小白 2个月逆天改命
Java+AI逆袭3 : 36岁/失业7个月/彻底绝望 。狠卷 3个月 Java+AI ,终于逆风翻盘,顺利 上岸
Java+AI逆袭 : 闲了一年,41岁/失业12个月/彻底绝望 。狠卷 2个月 Java+AI ,终于逆风翻盘
Java+AI逆袭5:1个月大涨2.5W,37岁 脱坑外包, 入了正编,GO+AI 要逆天了
职业救助站
实现职业转型,极速上岸

关注职业救助站 公众号,获取每天职业干货
助您实现职业转型、职业升级、极速上岸
-——————————–
技术自由圈
实现架构转型,再无中年危机

关注技术自由圈 公众号,获取每天技术千货
一起成为牛逼的未来超级架构师
几十篇架构笔记、5000页面试宝典、20个技术圣经
请加尼恩个人微信 免费拿走
暗号 ,请在 公众号后台 发送消息:领电子书
如有收获,请点击底部的”在看”和”赞”,谢谢
- 标题: 架构天花板:基于LangGraph的生产级Harness执行层——Sub-Agent深度拆解
- 作者: lxiol
- 创建于 : 2026-05-15 00:00:00
- 更新于 : 2026-05-20 18:11:49
- 链接: https://blog.lxiol.cn/2026/05/15/langgraph-harness-sub-agent/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。