参数砍到 1B,这个小钢炮拿下多模态第一
1.3B 参数拿下同级综合第一,推理吞吐量是同行的 1.5 倍。
今天,面壁智能发布并开源了 MiniCPM-V 4.6,MiniCPM-V 系列有史以来最小的模型,参数量只有 1.3B。
小归小,但其多模态综合能力则在 1B 级别里,拿到了第一。
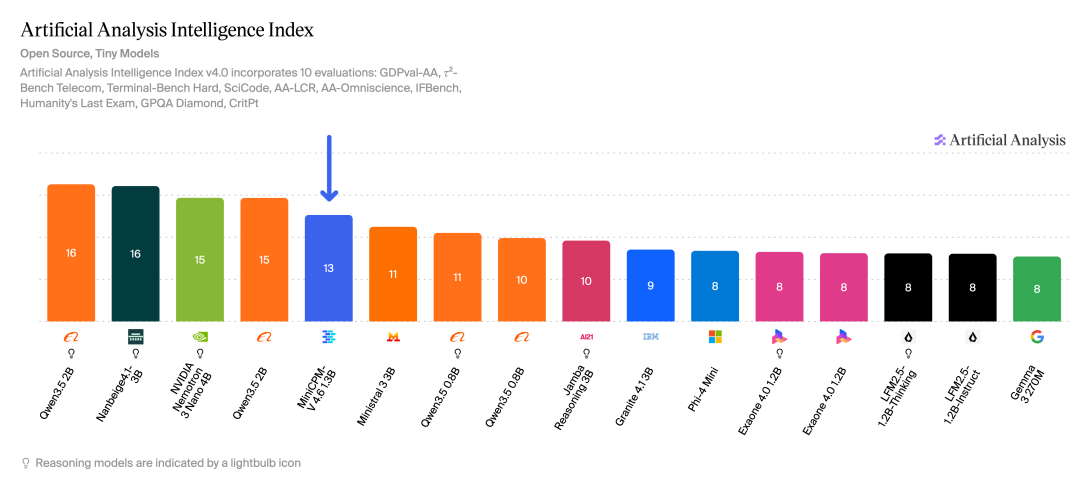
Artificial Analysis 智能指数
01
为什么做小
你可能会有些疑问:不都大模型吗?为什么要小?小有啥子用?
8B 的模型跑在服务器上、在 OpenAI 和 Anthropic 的机房里、在你的 4090 上……当然没什么问题,但到了手机、车机、智能家居这些终端设备上,就有点跑不动了。
参数越大,推理越慢,功耗越高,能适配的芯片、运行的环境也就会越少。
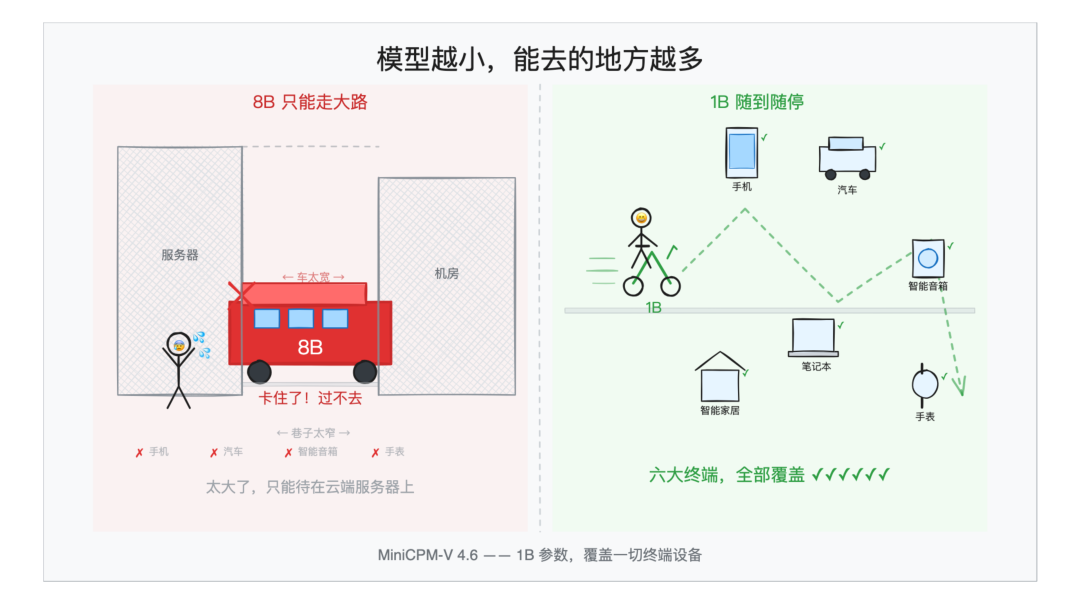
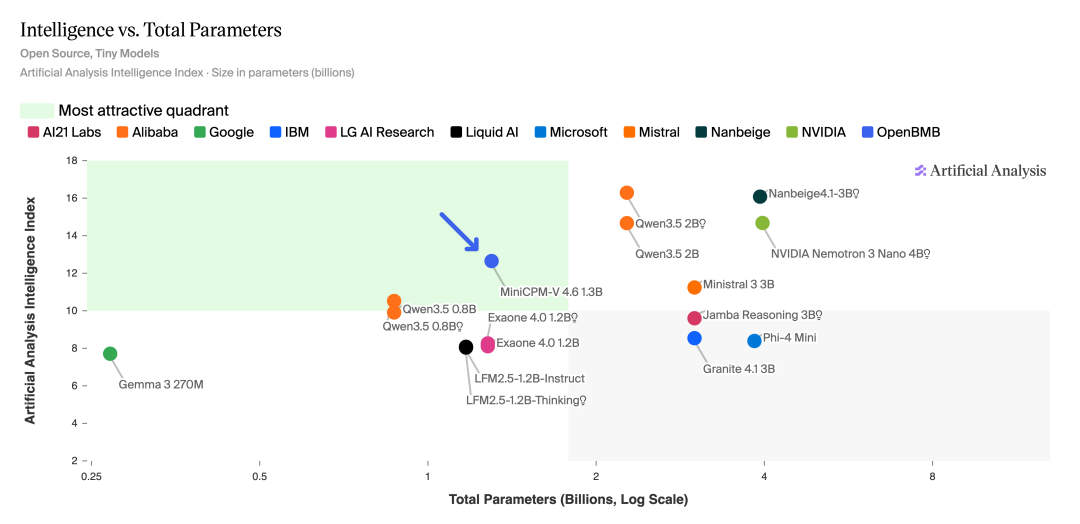
模型尺寸 vs 设备覆盖
打个比方吧,8B 像大巴车,宽敞舒适,但只能走大路。1B 呢,则更像是辆电动自行车,大街小巷随便钻,北京胡同也能玩,随到随停。
做到 1B 这个级别,基本上市面上所有手机和电脑,都能高效跑起来了。
你手里的手机,当然也轻松能跑。
面壁智能此前的比这次更大一些的端侧模型,就已经在联想、吉利、上汽大众等不少 B 端客户的产品里落地。
这些客户的共同诉求,就这一个字:小。
越小,能装进的设备就越多,能覆盖的场景就越广,越能满足各类用户群体的定位。
02
小但能打
而这么个 1.3B 的参数量,会不会能力有所缩水呢?
答案是:不会。
来看下成绩。
MiniCPM-V 4.6 在多模态综合评测中超过了 Qwen3.5-0.8B 和 Gemma4-E2B-it,在 1B 级别的所有模型中拿到了最好的成绩。
它有 Instruct 和 Thinking 两个版本,Instruct 快速响应日常任务,Thinking 遇到复杂推理时会深度思考。
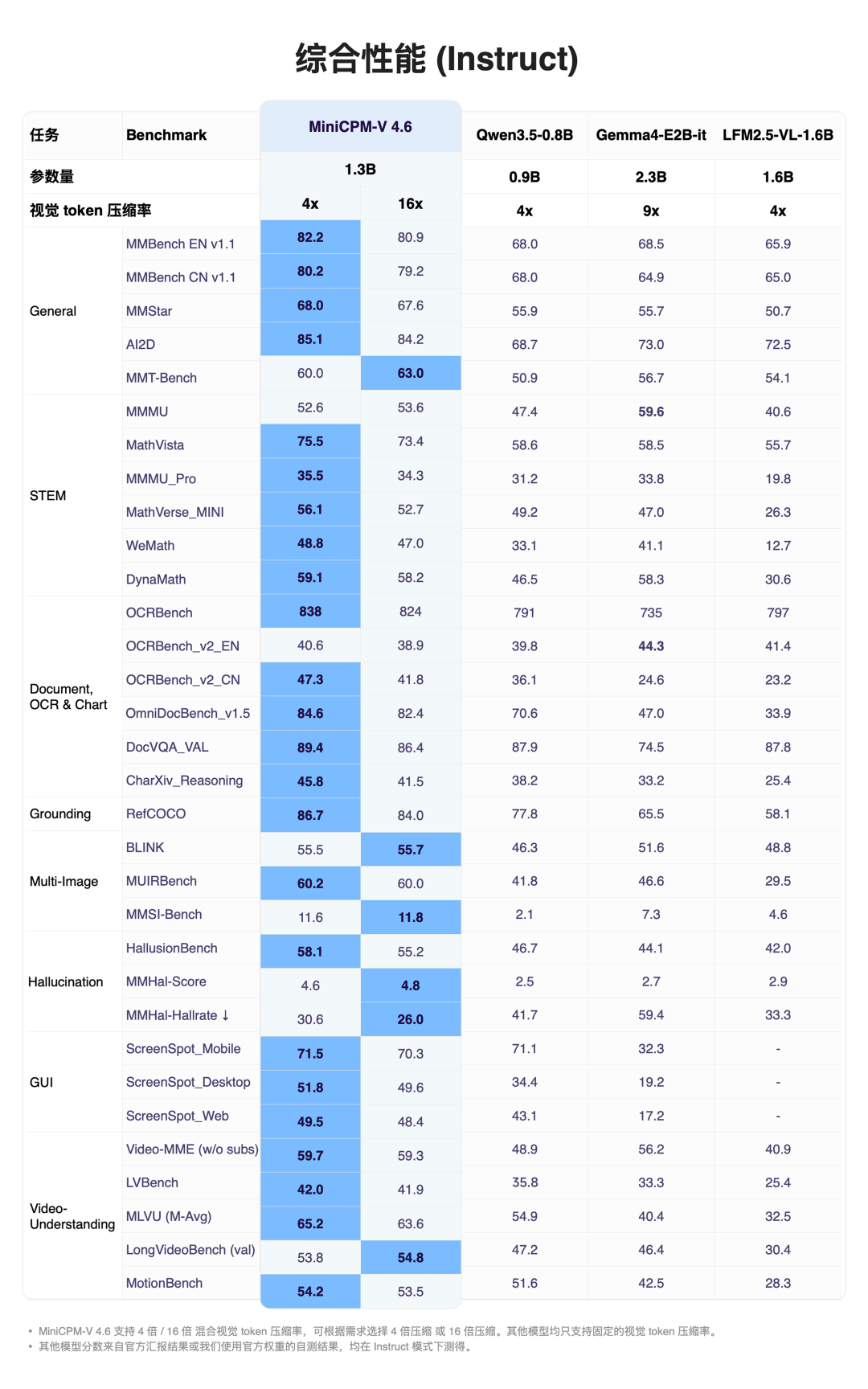
Instruct 评测成绩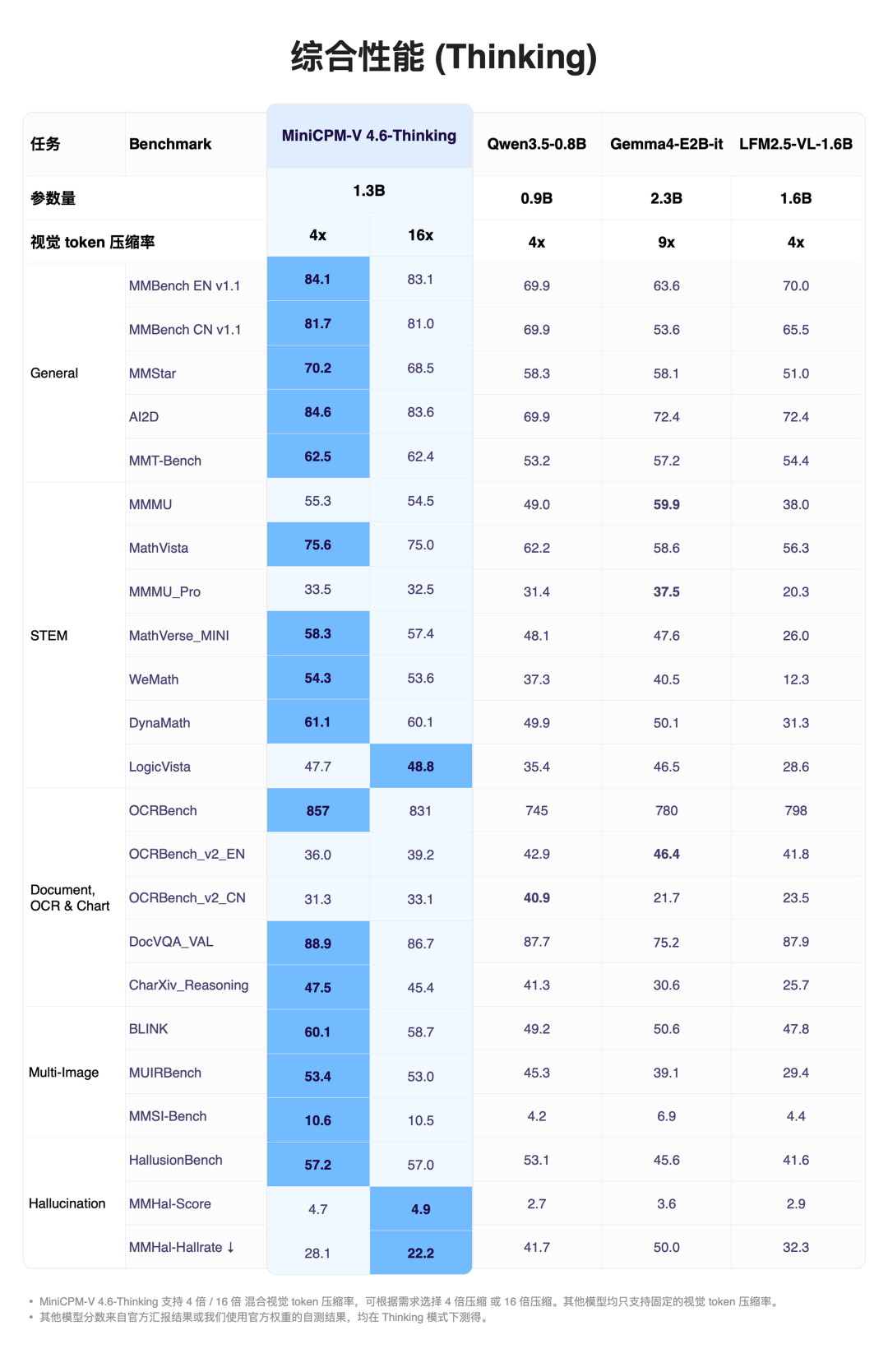
Thinking 评测成绩
而这之外,更能说明问题的是:效率。
在 Artificial Analysis 评测中,MiniCPM-V 4.6 仅用了 Qwen3.5-0.8B 2.5% 的 token 量,就超过了对方的得分。
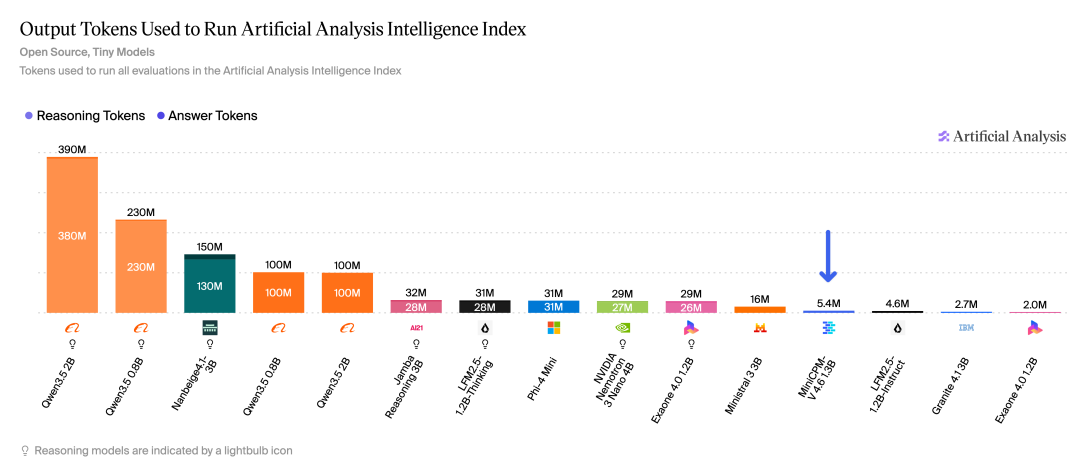
Artificial Analysis token 用量对比
注意:2.5%,也就是 40 分之一。
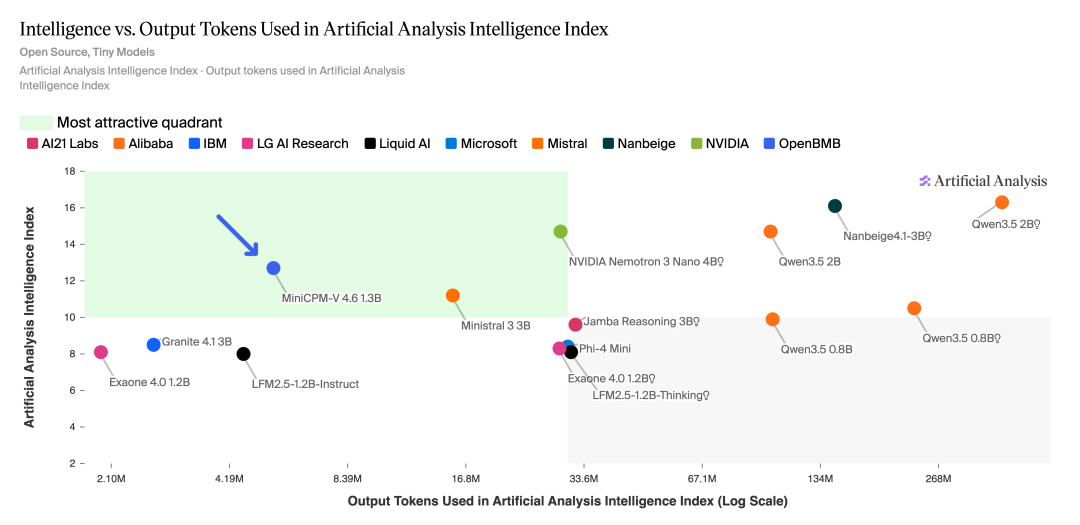
Artificial Analysis 智能指数 vs token 数量
换个说法,别人用一整本书才讲完的事儿,它一页纸就说清楚了。
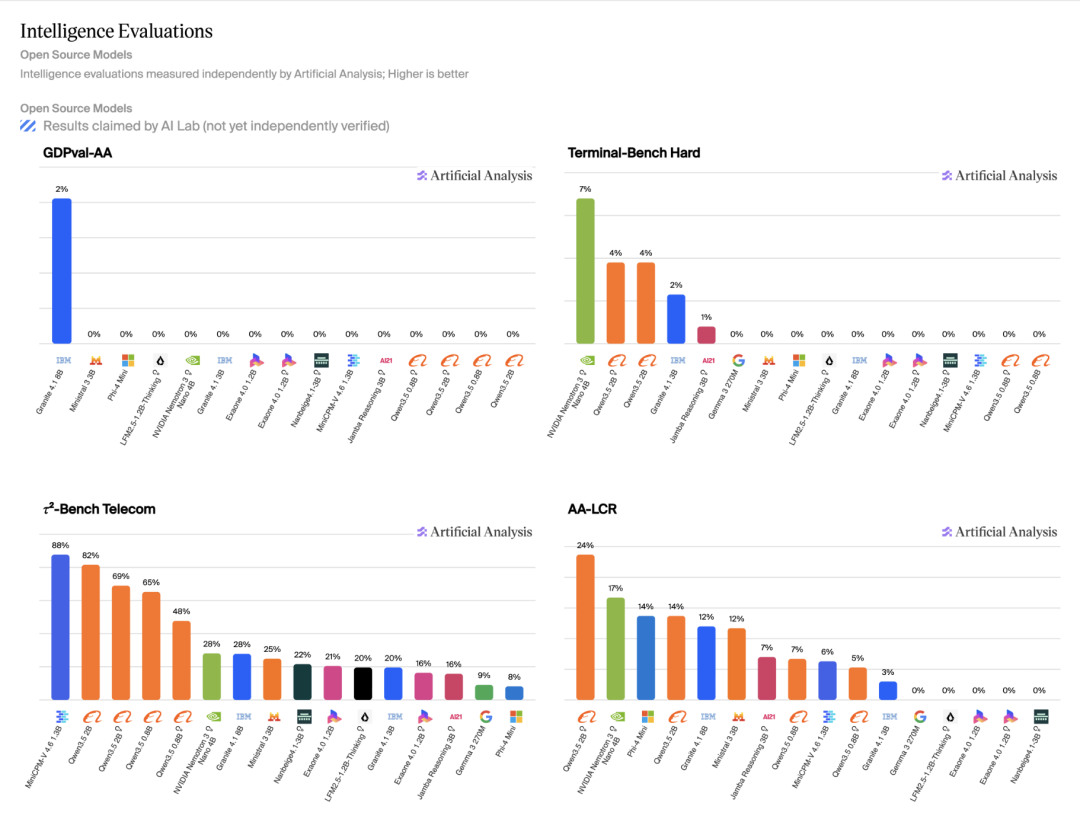
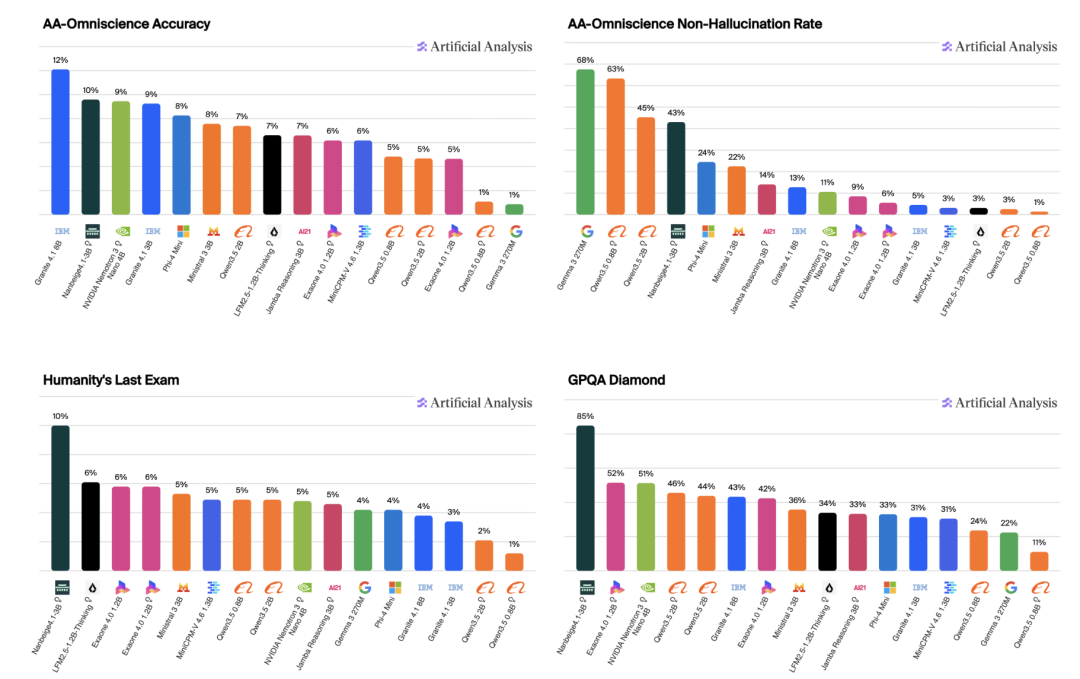
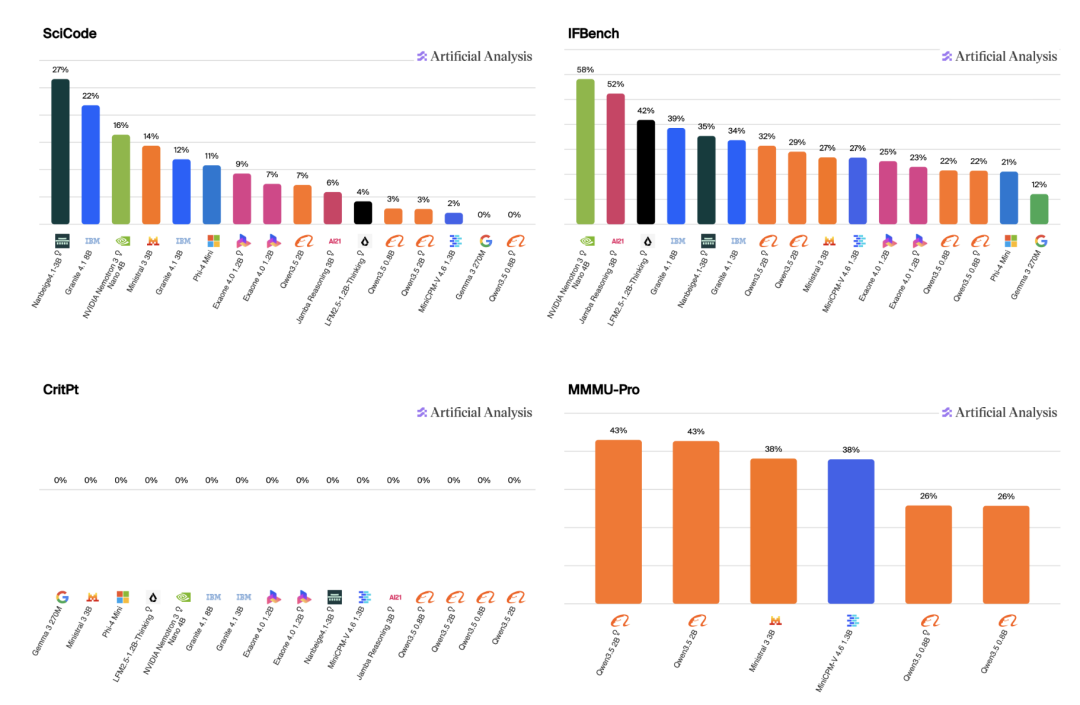
Artificial Analysis 整体成绩
这个「智能密度」在同尺寸模型中排到了最高,也算是又一次验证了面壁智能 2024 年提出并登上 Nature 子刊的「密度定律」。
密度定律验证03
超快推理
能力强只是一面,推理速度也是非常迅速。
我们在面壁手机 APP 下载模型后,直接断网进行上手体验,这样更为直观。下面的两个演示,完全的跑在手机端侧(不经过任何云端 api),用的是 MiniCPM-V 4.6 INT4 量化版本。
第一个是文档识别。我们把一张拍英文论文截图上传后,让它识别文字,表格输出 HTML,公式输出 LaTeX:
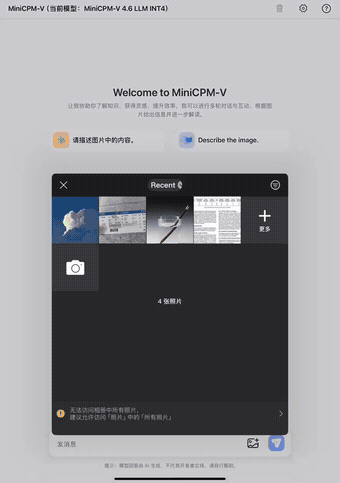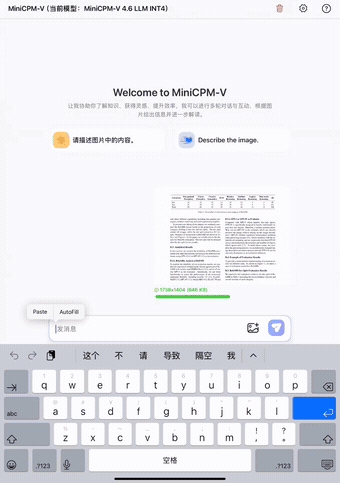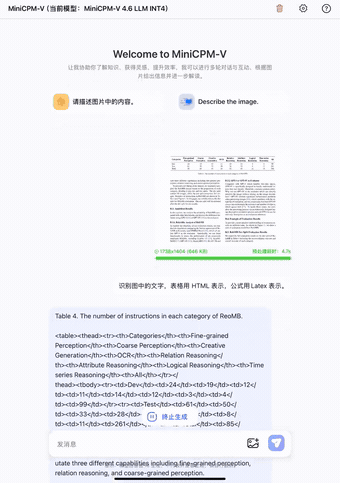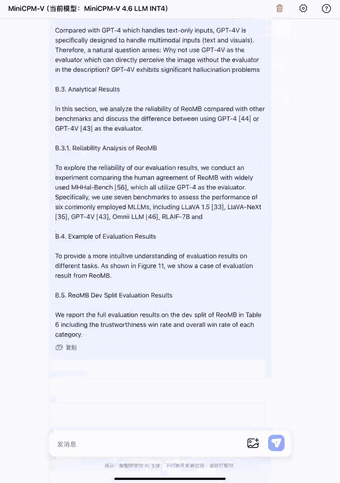
论文识别演示
大约 5 秒,就跑完了:表格结构、数学公式、正文段落,全都识别正确。
再来试一个偏生活化的场景:拍一张英文餐厅菜单,然后问它:「帮我把饮料翻译成中文。」

菜单问答:翻译饮料
几乎就是秒回……于是我们再追问一句:「最便宜的主菜是哪个?」

菜单问答:追问最便宜的菜
同样秒回:Cheese Sandwich,$2。
多轮对话、图片理解、中英翻译、价格比较,全都在手机上完成,不需要联网。
MiniCPM-V 4.6(16 倍压缩模式)基于 vLLM 的单卡高并发吞吐量达到了 2624 token/s。处理 1344² 分辨率的图片,则能跑到 14.3 张/秒。
是 Qwen3.5-0.8B 的 1.5 倍。
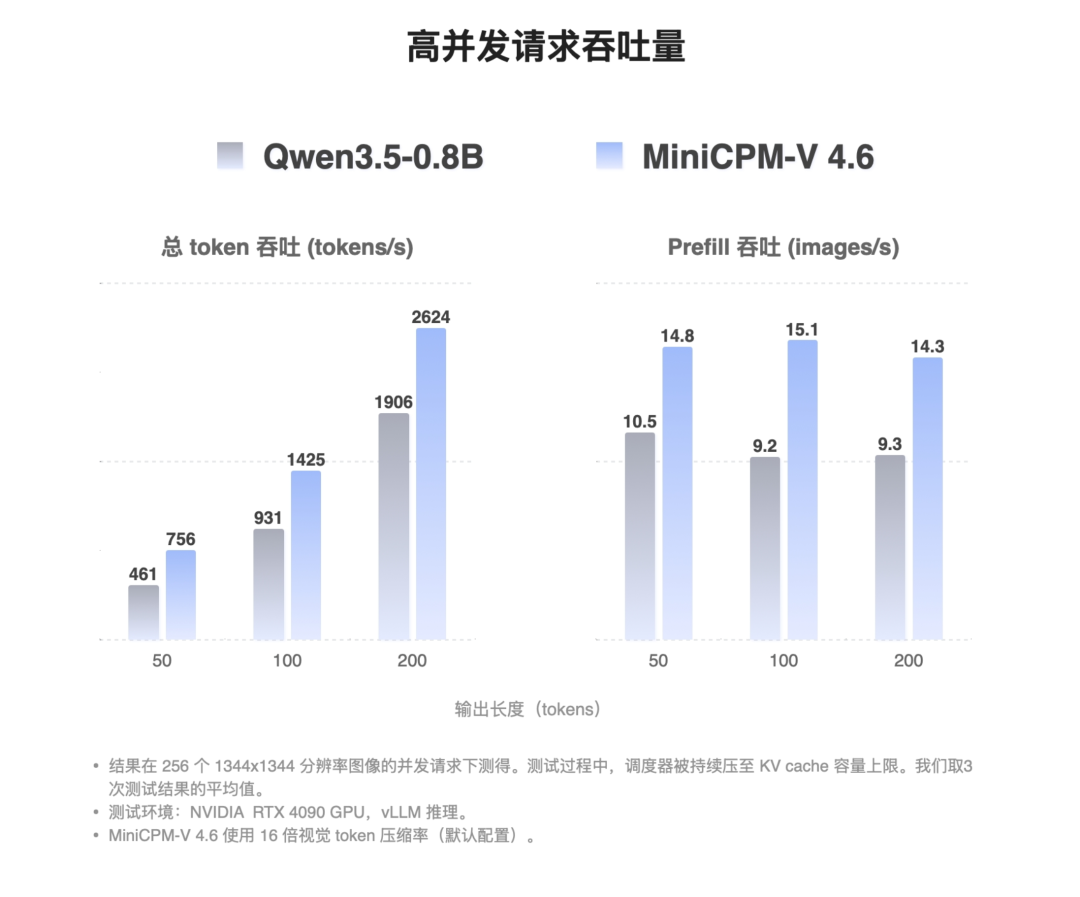
换句话说,同一张显卡,部署 MiniCPM-V 4.6 能承接的线上流量显著多于同级对手。对租两小时 AutoDL 跑着玩儿的可能没啥,但对企业来说,这相当于 GPU 成本真金白银的直接减少。
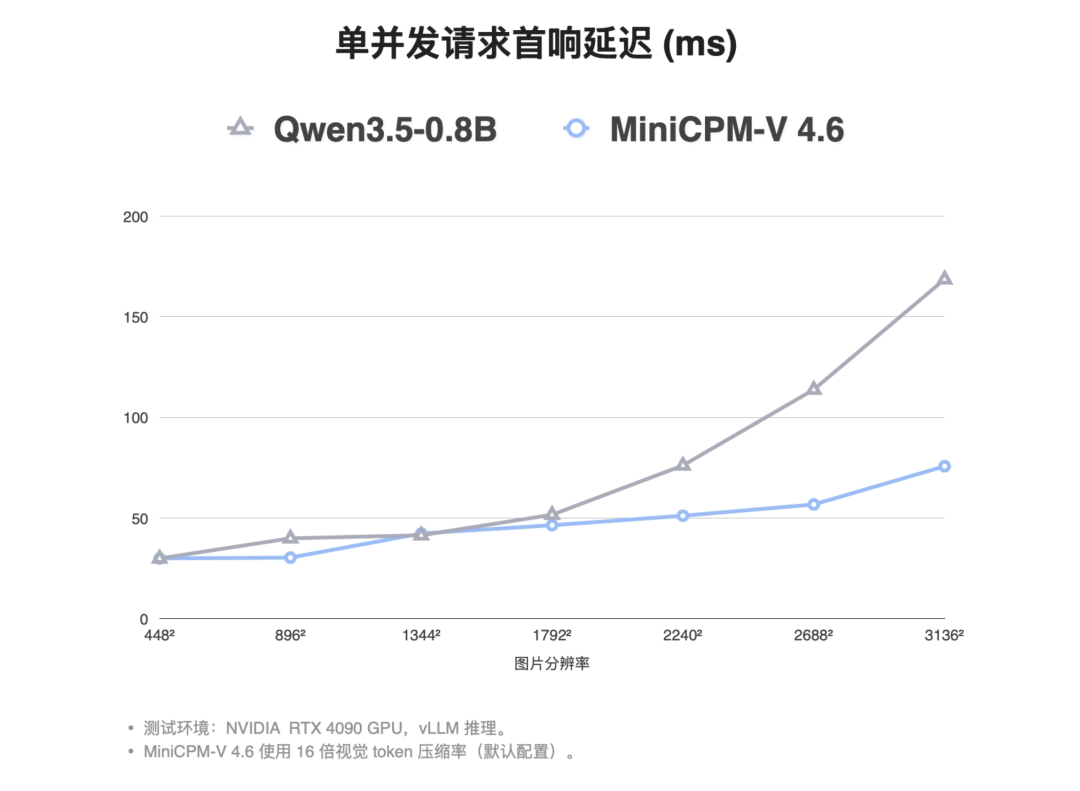
首响延迟方面,也同样拉开了差距。
低分辨率(448²)的时候,两个模型的 TTFT 差不多,都在 30ms 左右。但随着分辨率往上走,曲线就开始分叉了。
到 3136² 的高清大图,MiniCPM-V 4.6 的 TTFT 是 75.7ms,Qwen3.5-0.8B 则需要 168.6ms,快了 2.2 倍。
图片越大,MiniCPM-V 4.6 的优势越明显。
原因很好理解,16 倍视觉 token 压缩让序列更短、KV-Cache 更小,高分辨率下的计算膨胀被压住了。
04
怎么做到的呢?
又小、又快、能力还有点强,这背后是两个模型架构层面的创新。
我们知道,在进行多模态模型处理图片时,需要先通过 ViT(Vision Transformer)把图像编码成一串视觉 token,再交给语言模型去理解。
所以图片分辨率越高,token 越多,计算量就越大。
常规的做法是,等 ViT 编码完之后,再接一个压缩模块来减少 token 数量。这样确实能减轻语言模型的负担,但 ViT 内部的那一大堆计算量,一点都没省下来。
那……能不能把压缩往前挪呢?
越早压缩,后面的 ViT 层需要处理的 token 就越少。
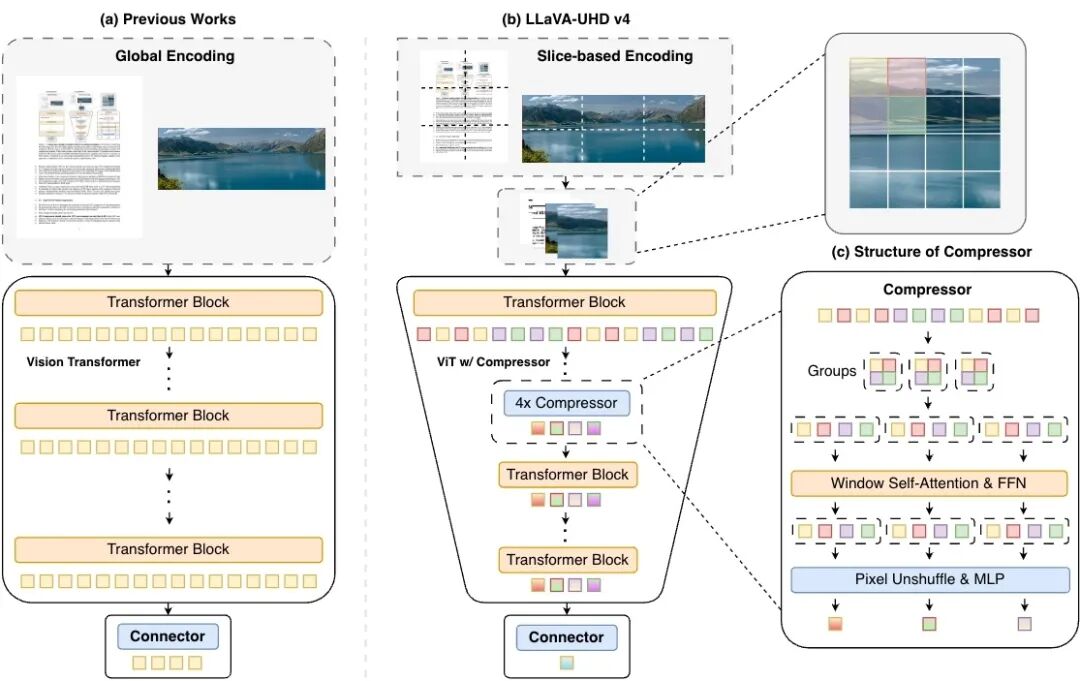
LLaVA-UHD v4 架构
面壁智能和清华大学联合研发的 LLaVA-UHD v4,核心思路就是这个。
把视觉 token 压缩前移到 ViT 内部的浅层。
但直接在浅层插一个随机初始化的压缩模块……会严重破坏 ViT 已经学好的视觉表征,训练代价太高了,效果也可能掉点。
这里的解法是:复用相邻预训练 ViT 层的参数来初始化这个压缩模块。同时在 token 合并前引入窗口注意力(Window Attention),补偿上下文信息。
简单说就是,在已有结构上巧妙嫁接,尽量不破坏原来学好的东西。
效果则是:视觉编码阶段的浮点运算量降低了 55.8%,性能没掉。
省了一半多的图像编码开销。
这也是 MiniCPM-V 4.6 参数量虽然比 Qwen3.5-0.8B 大,推理效率反而更高的关键原因。
另一个创新在视觉 token 的压缩率上。
市面上大部分多模态模型用的是 4 倍压缩率。面壁的 MiniCPM-V 系列从 2024 年就开始支持 16 倍压缩,但以前有个限制:4 倍和 16 倍只能二选一。
4 倍精度高,16 倍速度快。鱼和熊掌,往往不可兼得。
但……MiniCPM-V 4.6 实现了兼得。
需要高精度识别的时候走 4 倍,需要极速推理的时候切 16 倍。端侧和云端的需求,一个模型就可以覆盖。
16 倍压缩率的含金量,其实已经被验证过了。快手 2025 年发布的 OneRec 推荐大模型,在处理视频的字幕、标签、ASR、OCR、封面图等多模态数据时,用的就是 MiniCPM-V-8B。
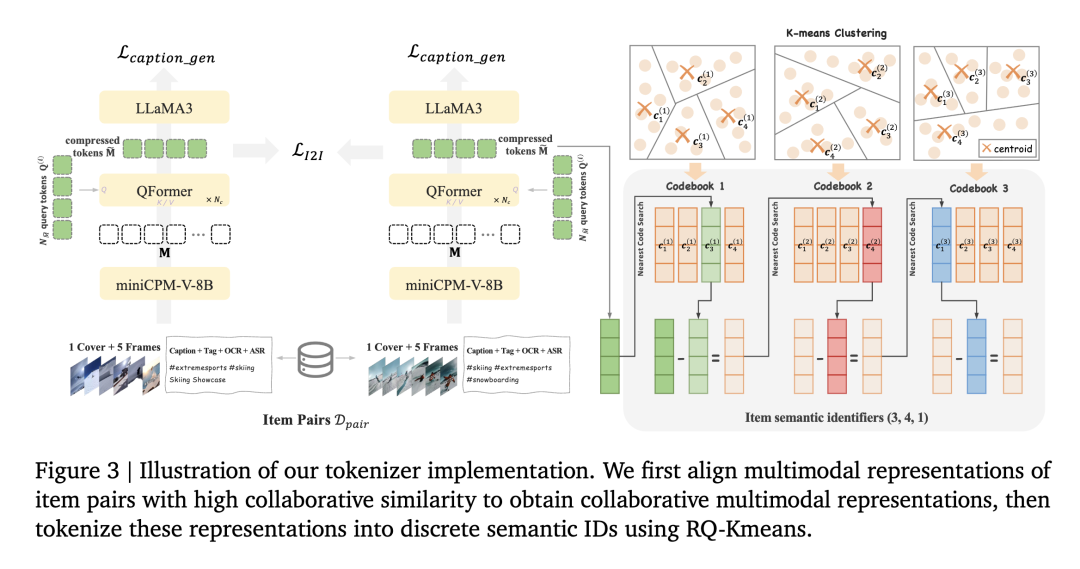
OneRec 架构
上线后,OneRec 承接了快手短视频推荐主场景 25% 的请求量。

OneRec 数据05
开箱即用、天生爆改
面壁这次,也给开发者准备了一套从微调到部署的完整工具链。
这也在于 1.3B 参数量带来的一个直接好处:一张 RTX 4090 就能跑完全量微调。
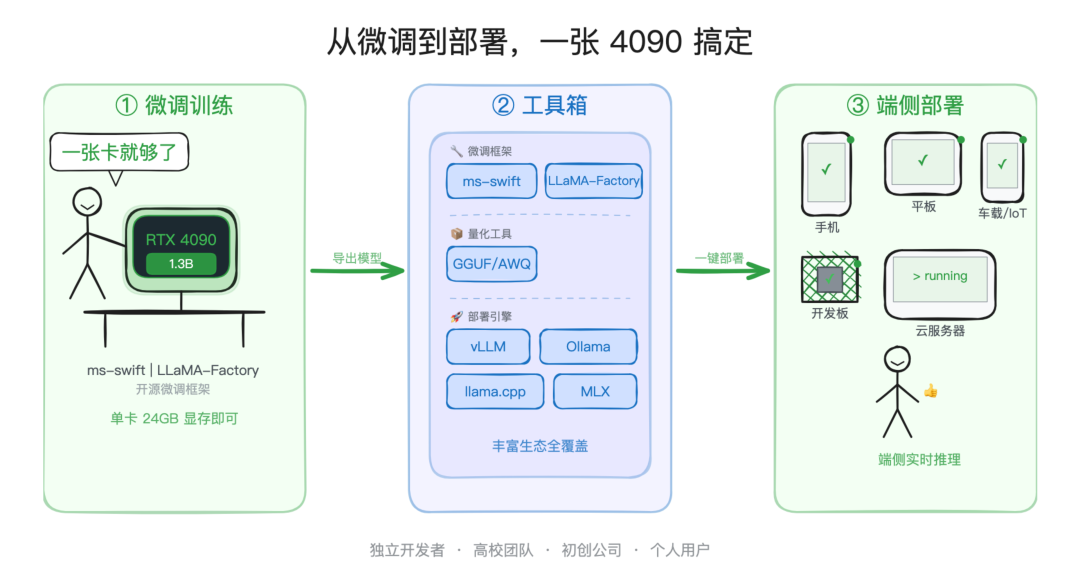
以前大模型微调动不动要算力集群,现在,一张消费级显卡就够了。独立开发者、高校团队、初创公司想验证一个多模态的 idea,成本可要比以前低了太多了。
微调框架上,官方原生支持了 ms-swift 和 LLaMA-Factory,准备好数据改几行配置就能跑起来。
部署端也是全家桶适配:vLLM、SGLang、llama.cpp、Ollama。云端上 vLLM 跑高并发,端侧用 llama.cpp 或 Ollama 跑离线,都是现成的方案。
还有个端侧部署指南,手机、平板、开发板都能轻松接入,可以扔给你的 Claude Code 或 Codex 看看。
不管是垂类文档解析、工业缺陷检测还是其他场景,可以说,面壁这个 1.3B 的小底座,天生就为「爆改」而生。
06
密度定律
MiniCPM-V 系列从 2024 年 4 月至今,已经迭代了六个版本。
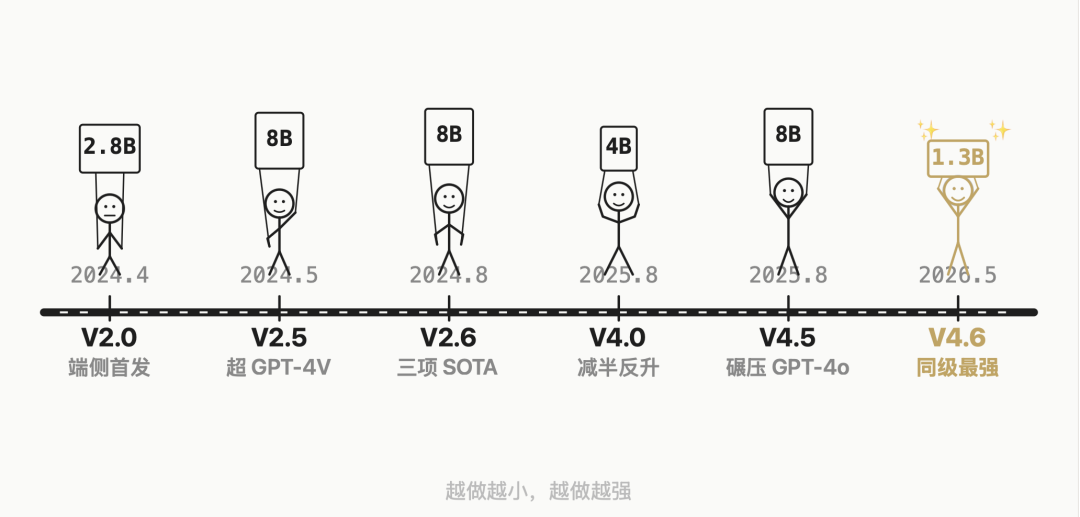
从 2.8B 起步,到 8B 越级超 GPT-4V,再压回 4B 性能反升,每一代都在同级别拿到最强。
到今天的 4.6 版,参数压到了 1.3B。系列最小,同级最强。
两年下来,MiniCPM-V 霸榜 GitHub Trending 和 HuggingFace 趋势榜,开源累计下载量近 3000 万次。相关成果登上了 Nature 子刊,还经历过斯坦福团队套壳事件……也算是技术路线被国际同行认可的一种证明。
越做越小,越做越强。
面壁 2024 年提出的「密度定律」,到今天算是自己验证了一遍又一遍。
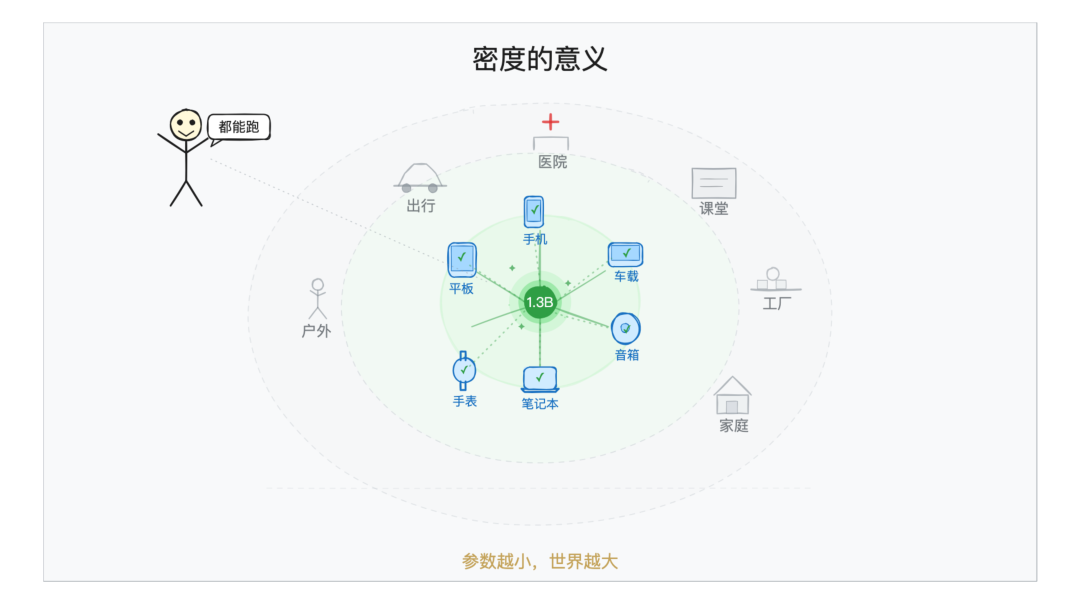
而参数越小,能跑的设备越多。能跑的设备越多,AI 能触达的场景就越广。
这大概也是,「密度」的另一种解释和意义了。
◇ ◆ ◇
相关链接:
• HuggingFace:https://huggingface.co/openbmb/MiniCPM-V-4.6
• GitHub:https://github.com/OpenBMB/MiniCPM-V
• ModelScope:https://modelscope.cn/models/OpenBMB/MiniCPM-V-4.6
• Web Demo:https://huggingface.co/spaces/openbmb/MiniCPM-V-4.6-Demo
• App Demo:https://github.com/OpenBMB/MiniCPM-V-Apps
💬 本文评论区已开启,但暂无读者留言。
本文转载自微信公众号,如有侵权请联系删除。
- 标题: 参数砍到 1B,这个小钢炮拿下多模态第一
- 作者: lxiol
- 创建于 : 2026-05-18 14:59:48
- 更新于 : 2026-05-18 14:59:48
- 链接: https://blog.lxiol.cn/2026/05/18/参数砍到-1B这个小钢炮拿下多模态第一/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。