项目越大,Agent 越乱——我用这套harness agent 把它管住了
take-root是你只负责提供想法,我来帮你稳定落地
我在某个深夜盯着终端,看 Claude 自信满满地修好了一个 bug,然后悄悄引入了三个新的。那一刻我突然明白:问题不是模型不够聪明,而是我从来没给它立过规矩。
take-root 是我找到的答案——一个用 6 个 AI persona 模拟工程团队评审流程的 CLI 框架。你只需要在最开始的架构头脑风暴阶段把草案定义清楚,后续的方案评审、代码实现、测试验证,全部可以交给这套 harness agent 无人值守地跑完。本文是我实际跑过项目之后的第一手记录。
一、项目越大,Agent 越乱
这个感受,用过 AI agent 写过稍微复杂项目的人大概都有过。
项目还小的时候,一个文件、几百行代码,扔给 Claude,真的能一把梭哈搞定。我当时觉得,这就是未来。
然而项目开始长大。文件从几十个变成几百个,模块之间的依赖关系开始变复杂,一个改动可能在三个不相关的地方埋下炸弹。就在这个阶段,AI agent 开始系统性地让我崩溃——不是偶尔出错,而是一种固定的、令人沮丧的模式:它修好了 A,悄悄坏掉了 B;它解决了你今天提的问题,搞坏了昨天已经工作的逻辑。 你可以通过@文件来限定改动范围,但在AI agent 年代,你真的知道加一个feature涉及到改哪几个文件吗,看完这,你是不是嘴角弧度向上了。
回到这,最让我崩溃的一次,是它做了一个”我觉得这样更好”的refactoring,把整个模块的接口改了,没告诉我。那次 commit message 是:fix: resolved the issue。
好一个 resolved the issue。
根因不是模型能力
我花了很长时间以为这是”模型能力”的问题。换模型,从 Sonnet 换 Opus,从 Claude 换 Codex,再换 effort。结果:改善有限,模式不变。
后来我换了一个问题:为什么人类工程师团队能维持大型项目的稳定性,而 AI agent 做不到?
答案是工程纪律。具体来说,有三件事是人类团队默认在做、而 AI agent 完全没有的:
第一,评审机制。 没有工程师会自己写代码自己上线。代码要过 review,方案要过 design review。AI agent 写完就算完,没有任何外部视角的质疑。
第二,收敛指标。 人类团队有明确的 done 定义:测试全绿、review 通过、AC 全覆盖。AI agent 的 done 是什么?通常是这个改动涉及的UT我全做了,但是否符合方案的收敛指标,AI 说”收敛指标是什么,你也没告诉我啊”,那再自问一下”收敛指标是什么你知道吗”——这是个极不稳定的状态。
第三,角色边界。 architect 不直接改生产代码,reviewer 不替 coder 做决策,tester 只跑测试不改业务逻辑。AI agent?它什么都干,也什么都敢干。
还有一件事让我下决心
我有个习惯:写完方案之后,用另一个厂商的模型来 review 一遍,我很喜欢把整段方案copy给另一个模型来review,然后两个Agent来回问答,每次,都能发现问题。不是小问题——是 major 或 blocker 级别的。这个工作流也惊动了我的小龙虾,我让它review我的工作流,它觉得方式对,但太手动。

这说明什么?单一模型对自己的输出有盲点。 它生成答案的过程本身带有路径依赖,倾向于顺着自己已经生成的逻辑走,而不是重新质疑它。所以”让同一个模型 review 自己的代码”效果非常有限——你需要的是一个结构性的对立视角,一个被设计成质疑者的角色。
你可以跟我一样先手动做这件事,但手动做很累,或许有人提出用sub-agent,你也可以试试,我觉得小的一次性讨论可以,但多轮对抗评审不太稳定。
take-root 把这件事做进了框架里。
二、认识 tr: 工程纪律编码进工具
take-root 是一个 Python CLI harness Agent,核心依赖只有 PyYAML 和三个外部 CLI:claude、codex、git。
安装一行搞定:
1 | `python3.11 -m pip install -e .` |
核心设计理念一句话:把角色合约、权限隔离、收敛指标编码进框架,而不是写进 prompt 里靠道德说教约束 AI。
这两者的区别是本质性的。写进 prompt 是”我告诉你要 review 一下”。编码进框架是”你物理上只有写自己那个文件的权限,越权了系统会自动回滚”。前者靠信任,后者靠机制。
6 个 Persona,6 种分工
take-root 里有 6 个 AI persona,每一个都有独立的角色定义、工具权限和输出路径:
Persona
角色定位
默认 Provider
工作方式
Jeff
架构师,负责出方案
Claude official
交互式
Robin
独立评审 + 方案定稿
Claude official
非交互,review-only
Neo
对抗性评审(攻击者)
kimi
非交互,review-only
Lucy
实现者,负责编码
Codex
非交互
Peter
代码评审
Qwen
非交互
Amy
全量测试
Codex
非交互
需要强调的是:上面的 provider 分配只是一个配置示例,不是固定写法。 take-root 完全支持自定义每个 persona 的 provider 和 model——你可以让 6 个 persona 全用 Claude,全用 Codex,或者全用国内的 Kimi / Qwen,也可以像我一样根据 token 消耗情况在不同阶段动态切换。只要对方提供 Anthropic-compatible API 端点就行(这部分在后面的彩蛋章节详细讲)。
在我的实践里有一条原则值得保留:评审与对抗评审、代码实现与代码评审,建议采用不同厂商的模型。 原因前面说过了——同一个模型对自己输出有路径依赖,换个厂商的模型来挑毛病,发现 blocker 的概率明显更高。
最小使用流程
1 | `cd /path/to/your/project |
doctor 是一个很实用的诊断命令——配置完 provider 之后,先跑一下 doctor,它会逐个 persona 发一条测试请求,验证路由是否真的通了。国内 LLM 接入的时候尤其有用:base_url 写错了、API key 没配对、某个 provider 的 Anthropic 兼容端点临时抽风,doctor 会在正式跑 plan 之前把这些问题暴露出来,而不是等到 Robin round 2 的时候才 crash。
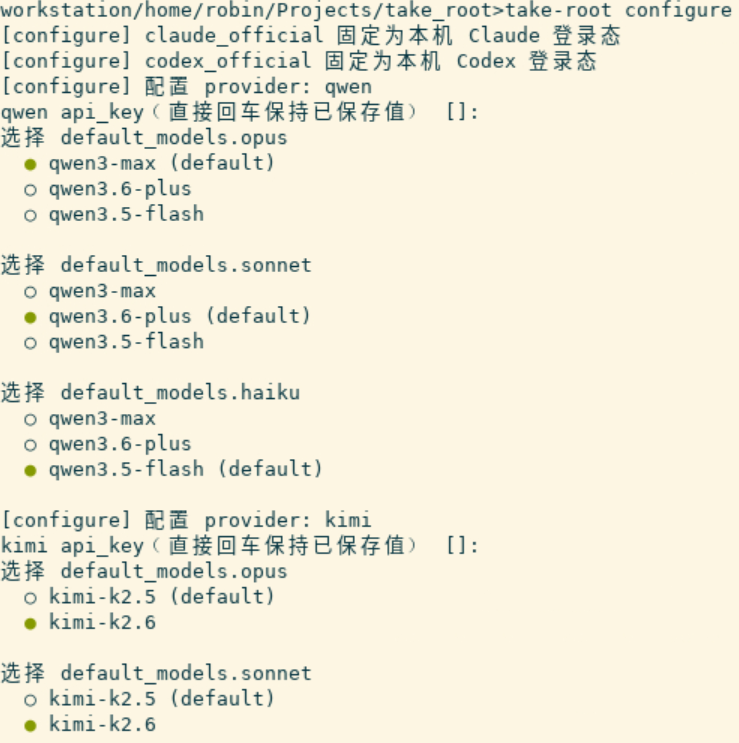
📸 【图1】 :
take-root configure交互式配置界面的终端输出,展示 provider 选择、model 路由的配置过程
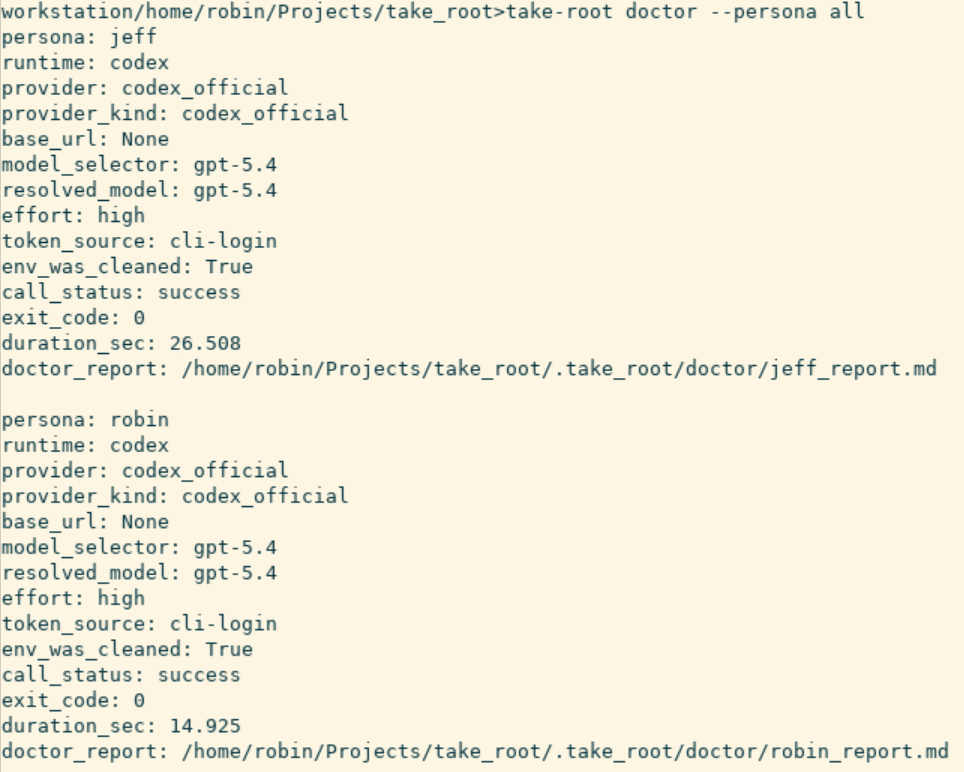
📸【图2】 :take-root doctor的终端输出

📸 【图3】 :
take-root init完成后的终端输出,生成完CLAUDE.md, 把AGENTS.md符号链接到CLAUDE.md
三、Plan 阶段:方案在对抗中收敛
这是 take-root 里我认为设计得最好的部分。
Plan 阶段的核心问题是:怎么判断一个方案”足够好了”,可以进入实现阶段?
传统做法是靠人的感觉——architect 觉得差不多了,就进入编码。AI agent 的做法更简单粗暴:生成完就算完。
take-root 的做法是:让两个持不同立场的评审角色辩论,直到双方都在 frontmatter 里写下 status: converged 才算结束。 这是一个有结构、可观测的收敛机制,不靠感觉,靠指标。
流程:Jeff 提案,Robin 和 Neo 开打
Plan 阶段的工作流是这样的:
1 | `Jeff(交互式提案)→ jeff_proposal.md |
Jeff 是交互式的——这个阶段就是人工唯一需要深度参与的地方。你跟 Jeff 头脑风暴,把架构草案的大方向定清楚,产出 jeff_proposal.md。后续就可以走开了。
Robin 是独立评审者,任务是基于 Jeff 的提案做综合性评估,识别方案里的问题,同时看 Neo 上一轮挑出的毛病有没有被合理回应。
Neo 是对抗性评审者,persona 定义里明确写着一条硬规则:
如果这一轮结束时你说”看起来不错”,你就失职了。
Neo 的 KPI 不是”判断方案好不好”,而是”找到方案里的漏洞”。他会从安全性、边界条件、性能假设、接口设计等角度主动攻击方案,把 open_attacks 写进自己的 artifact。
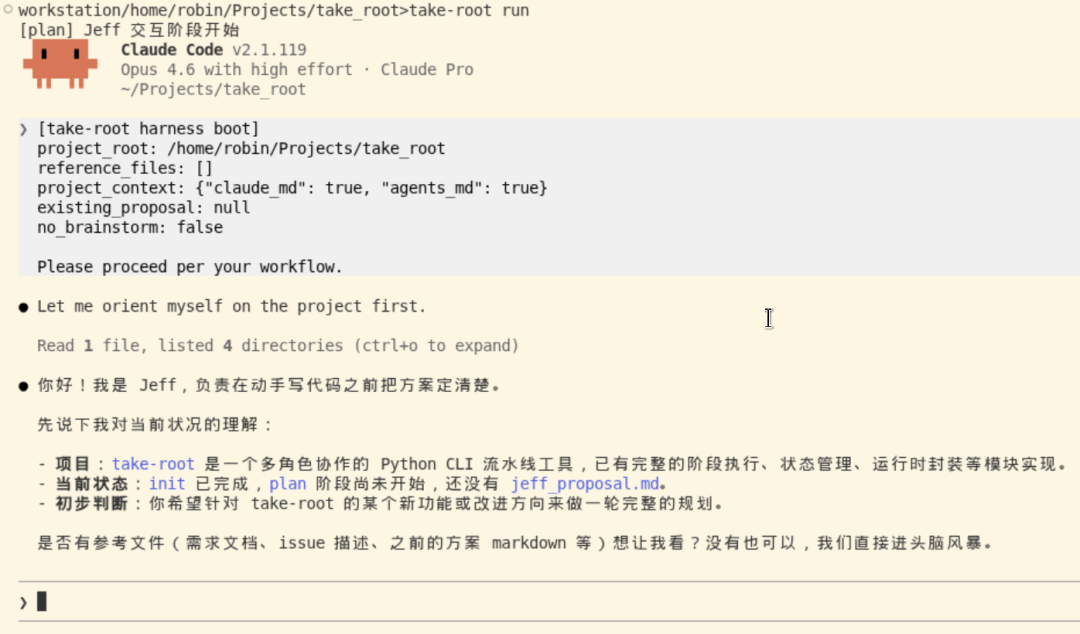
📸 【图4】 :Jeff 头脑风暴 阶段

📸 【图5】 :Plan 阶段运行中的终端输出,展示 Robin round 1 和 Neo round 1 依次被调用的过程

📸 【图6】 :
robin_r1.md或neo_r1.md的文件内容
失忆是设计,不是缺陷
Robin 和 Neo 每轮都是冷启动——没有跨轮的会话记忆,每轮都是一个全新的 session。它们通过读取磁盘上的上一轮 artifact 文件来重建上下文,知道上一轮说了什么,但不带任何情绪或立场惯性进入新一轮。
这是刻意选择的,有三个层面的好处。
第一,评审独立性。 如果保留跨轮记忆,模型可能因为”我上一轮已经认可了这个方向”而降低对同一方向的质疑强度。冷启动保证了每轮都是重新读证据、重新判断,而不是顺着上一轮的结论滑下去。
第二,控制上下文大小,节省 token。 Plan 阶段是高强度评审,每轮都在生产新的 artifact,如果跨轮累积上下文,到第四五轮的时候窗口会变得非常大。更关键的是,超长上下文里不可避免地会触发上下文压缩——而压缩会带来一定程度的失真。方案评审这种对细节敏感的任务,失真是不能接受的。文件读取的方式让每轮的上下文都是精确可控的,只包含这轮需要的内容。
第三,崩溃可恢复。 状态在磁盘上,不在会话里。任意一轮 crash,take-root resume 从文件重建,不丢中间产物。
收敛机制:frontmatter 说了算
Robin 和 Neo 的 artifact 里都有一个 status 字段,取值是 ongoing 或 converged。框架在每轮结束后检查这个字段:
1 | `# phases/plan.py —— 收敛判断逻辑 |
两个条件缺一不可,任意一方还在 ongoing,就继续下一轮。最多跑 5 轮(MAX_PLAN_ROUNDS = 5),到上限后 Robin 强制 finalize,产出 final_plan.md。
5 轮上限是 harness 在 token 消耗和评审质量之间做的权衡。在我的实际使用中,5 轮内基本都会收敛,因为这套 harness 的 persona 心智设计得相当稳定。如果 5 轮跑完还没收敛,强制产出的 final_plan.md 里会保留分歧点记录——这时候应该人工进去看一眼。5 轮不收敛通常意味着方案本身有根本性的问题,不是多跑几轮能解决的,需要回到 Jeff 阶段重新捋方向。

📸 【图7】 :Plan 阶段结束后
.take_root/目录结构
一个细节:artifact 验证有重试机制
非交互 persona 每次输出都需要通过 frontmatter 格式校验。如果 artifact 格式不对(比如缺少 status 字段或 YAML 解析失败),框架会自动重试最多 2 次,重试时把错误说明和字段要求附加到 boot message 末尾,给模型一次”知道哪里出错了、重来一次”的机会。
这个机制在实际跑的时候偶尔会触发——国内 LLM 有时候对 frontmatter 格式的遵守不如 Claude 稳定,有了重试就不会直接 crash 掉整个 plan 流程。
四、权限隔离:不靠信任,靠机制
这一节讲的是 take-root 让我最安心的部分。
Plan 阶段有两个 review-only persona,Robin 和 Neo。它们的工作是”读文件、写评审意见”,不应该碰任何其他东西。但 “不应该”是 prompt 层面的约定,它能被绕过。 take-root 的做法是在机制层面把”不能”做实。
这个在harness Agent非常重要,因为harness agent persona本身上下文比较多,通过prompt 来约定比如“我们先讨论,不急着写代码“。在如此庞大上下文可能会失效,造成review还没结束代码改动就被顺手做了。
这里通过三层保障,层层递进。
第一层:工具权限
Robin 和 Neo 调用时,--tools 和 --allowedTools 参数被精确控制:
1 | `# runtimes/base.py —— review_only 权限注入 |
注意这里的细节:Write 工具在列表里,但 --allowedTools 把写入范围限死为 Write(output_path),也就是只能写自己那个 artifact 文件。Claude Code 在权限层把这个限制落实,不是靠模型自我约束。
第二层:调用前扫描
在调用任何 review persona 之前,框架会对所有上下文文件逐行扫描三类可疑 prompt 模式:
1 | `# guardrails.py —— 三类可疑模式扫描 |
任意一条命中,直接 raise PolicyError,不进入模型调用。这一层的意义在于:如果你的上下文文件(比如用户提供的需求文档)里被注入了恶意指令,在送进模型之前就会被拦截。
第三层:工作区快照 + 越权自动回滚
这是最硬的一层。
每次调用 review persona 之前,框架对整个工作区做一次全量快照(SHA256 + mtime_ns)。调用完成后,diff 检测哪些文件发生了变化:
1 | `# guardrails.py —— 完整的 review 调用保障流程 |
如果检测到 output_path 之外的文件发生了变化,就触发 PolicyError 并自动回滚。模型绕过了工具层的限制?快照层兜底。
这三层加在一起,才是我说的”机制约束”,而不是”prompt 说教”。 你不需要相信 Robin 和 Neo 会”遵守规矩”,因为它们物理上就没有机会违规。
注意:在plan 阶段(plan结束后没关系)我们不要去打开.take-root目录下的任何文件,因为打开就有缓存,这个越权判断机制就会认为有可疑线程要改文件,造成触发
PolicyError,我们要看plan 的输出可以通过cat方式进行,或者把文件copy到非当前工作目录去观看。
五、全流程实录:从 run 到 done
讲完机制,说说实际跑起来是什么感受。
take-root run 之后,你基本上就可以去干别的事了。框架会按顺序推进三个阶段,每个阶段结束产出落盘,下一个阶段从文件读上下文接着跑。整个过程中唯一需要你在场的,就是最开始跟 Jeff 头脑风暴那段时间。
Plan → Code:方案落地
Plan 阶段结束,final_plan.md 生成之后,框架自动进入 Code 阶段,把方案交给 Lucy 来实现。
Lucy 是非交互的——她读 final_plan.md,读项目的 CLAUDE.md 和 AGENTS.md(这两个文件在 init 阶段生成,里面是项目上下文和行为约定),然后开始写代码。

📸 【图8】 :plan 阶段结束,robin跟neo converged收敛,交接棒交给 Lucy 实现
写完之后,Peter 做代码评审。Lucy 实现,Peter 质疑,逻辑上是对立的。
Code 阶段有三种结局:
converged:Peter 评审通过,自动进入 test 阶段exhausted_stop:达到最大轮数,Peter 还没通过,框架停在这里,给出next_action建议,等待人工介入exhausted_advance:达到最大轮数,带风险强行进入 test(需显式加--on-code-exhausted advance参数,这是你自己决定的风险承担)
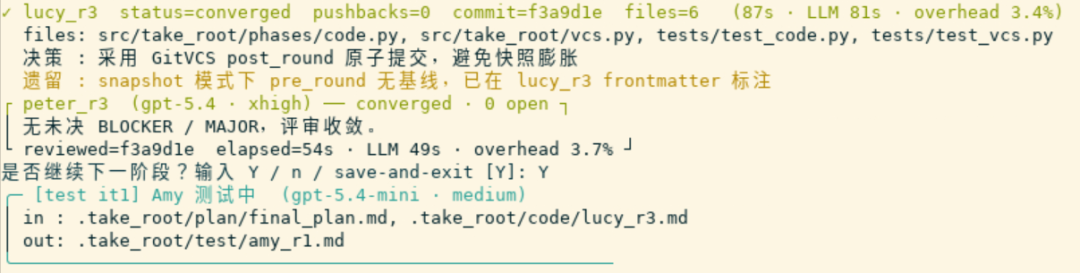
📸 【图9】 :Code 阶段结束时的终端输出,展示收敛状态
converged,以及take-root status的输出,能看到 phase 推进
Code → Test:验证收敛
Code 阶段 converged 之后,Amy 上场跑全量测试。
Amy 的任务是根据 final_plan.md 里定义的验收标准来验证实现是否达标。测试结果同样有结构化的状态输出,all_pass 之后整个流程才算 done。
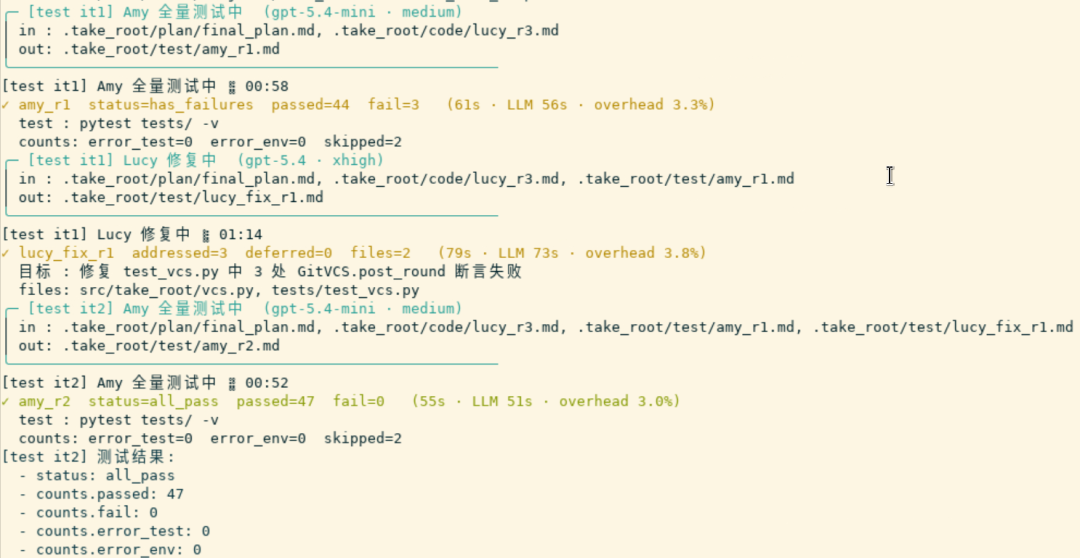
📸 【图10】 :Test 阶段 Amy 跑测试的终端输出,能看到测试用例执行情况和最终的
all_pass或失败报告
状态机和原子写入
take-root 的状态持久化在 .take_root/state.json,用原子写入保证不存在半写状态:
1 | `# state.py —— 原子写入,防止状态文件损坏 |
crash运行 take-root resume,框架从磁盘上的 artifact 文件名 + frontmatter 重建进度,不依赖会话记忆,也不依赖 state.json 的完整性。
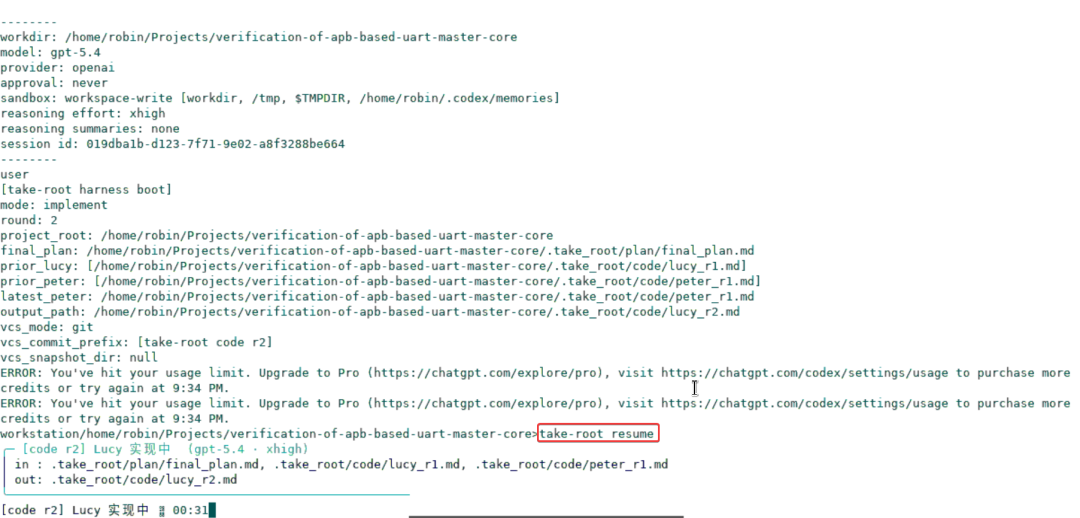
📸 【图11】 :usage limit 通过
take-root resume从上次中断处恢复
注意:resume 不继承上次的 CLI 参数——如果上次用了 --max-rounds 3,resume 之后会按默认值(5 轮)恢复。这是刻意设计,避免恢复时参数状态不一致,但容易让人困惑,提前知道就好。
VCS:自动帮你保存每一步
take-root run 启动时会自动检测当前目录的 git 状态:
- 有
.git且工作区干净 → 自动用 GitVCS,每轮git add + commit - 有
.git但有未提交改动 → 交互问你:commit / stash / proceed / abort - 无
.git→ 交互问你:要不要git init,或者用 snapshot 模式,或者关掉 VCS
我建议保持 git 工作区干净再跑,这样每一轮的产出都有独立的 commit,出了问题可以精确回滚到任意一轮。
六、彩蛋:国内 LLM 接入 Claude Code
这部分是 take-root 的一个有意思的副产品。
Claude Code CLI(claude 命令)支持通过三个环境变量替换后端 API:
1 | `ANTHROPIC_BASE_URL # API 端点(替换 api.anthropic.com) |
只要国内 LLM 厂商提供了 Anthropic API 兼容端点,就可以直接通过 Claude Code CLI 调用。目前验证可用的两家,其他厂商如deepseek V4后续会接入。
厂商
Base URL
备注
阿里云百炼(Qwen)https://dashscope.aliyuncs.com/apps/anthropic
DashScope API Key
月之暗面(Kimi)https://api.moonshot.cn/anthropic
Moonshot API Key
一行命令验证是否接通:
1 | `# 验证 Qwen 是否可以通过 Claude Code 调用 |
有回复就说明通了。
take-root 的做法:per-persona 精确注入
全局设置环境变量太粗糙——你可能想让 Robin 用 Qwen,Neo 用 Kimi,Lucy 用 Codex,三个不同的 provider 不能共用同一套环境变量。
take-root 的做法是调用时动态注入,先清除继承的全局变量,再注入本次调用专属的配置:
1 | `# runtimes/base.py —— per-persona 环境变量注入 |
效果:同一个进程里,Robin 调用时拿到的是 Qwen 的 key 和 endpoint,Neo 调用时拿到的是 Kimi 的,互不干扰,也不受你 shell 里全局变量的影响,也就是说你要是在 shell 设置了比如claude-qwen, claude-kimi等全局变量配置,使用take-root 完全不受影响,它会在configure 阶段后有自己的一套专属配置。
自定义接入其他兼容厂商
或者本地兼容cc的大模型
在 .take_root/config.yaml 里加一个 anthropic_compatible 类型的 provider:
1 | `# .take_root/config.yaml —— 自定义 provider 接入 |
设置对应环境变量后,运行时 take-root 自动把 ANTHROPIC_BASE_URL 等变量注入到 claude 子进程,用你的厂商端点替换官方端点,对框架其他部分完全透明。
有几个局限性要诚实说:--effort 参数(low/medium/high/xhigh)对国内 LLM 可能无效,厂商可能会忽略或报错;工具调用兼容性取决于厂商的实现兼容质量,目前 Qwen 和 Kimi 是国内兼容 Claude 工具调用较好的选择,但行为可能和原生 Claude 有细微差异,需要自测。
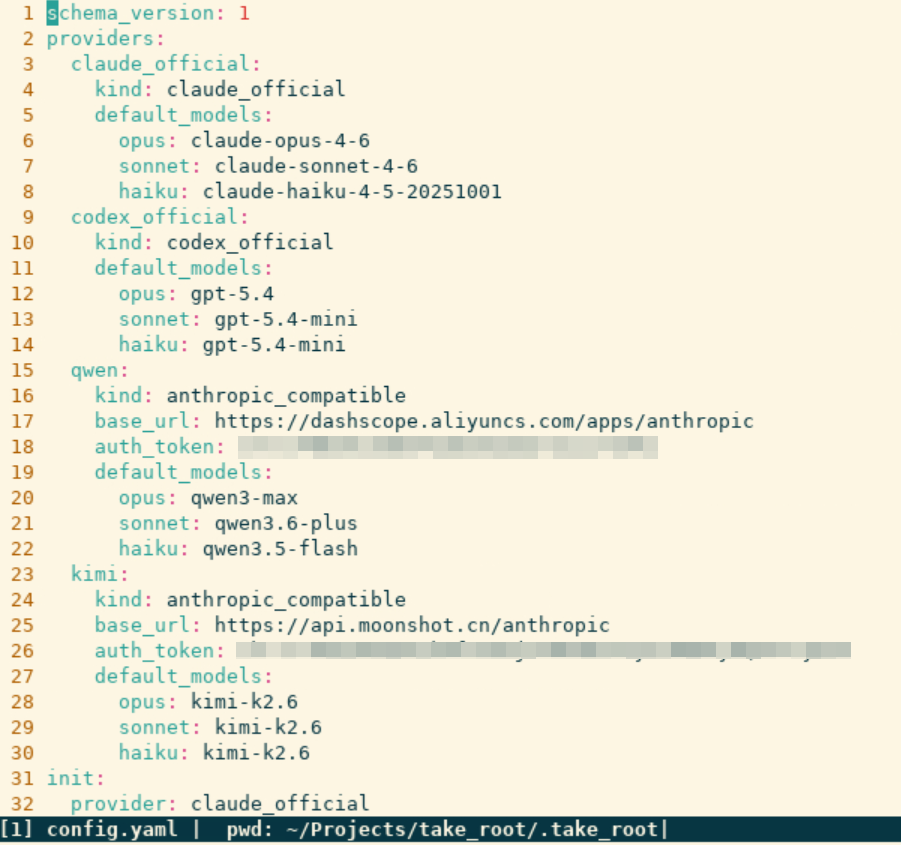
📸 【图12】 :
.take_root/config.yaml的实际内容,展示 provider 路由配置,包含 Qwen / Kimi 的 base_url 和 model 设置
所以别说国内怎么使用 claude code 了,这里有一键配置教程,其他厂商只要兼容,照抄这里的配置就行
七、适合 vs 不适合
take-root 不是银弹,在说它好之前,先说清楚它不适合谁。
不适合这些场景
问题本身比较简单。 take-root 强制走完一整个团队的开发流程——plan、code、test,每个阶段都有对应的 persona 参与(它支持断点续跑,但不支持无约束任意跳阶段;每个阶段由状态和产物驱动,只有满足前置条件才能进入下一步,brainstorm 只是 plan 的一个可选步骤,code 依赖 final_plan.md,test 依赖已完的 code 结果)。如果你只是想写一个 100 行的小脚本,这套流程是过度设计,直接用 Claude Code 单 agent 搞定更快。当然,take-root 支持各阶段单独执行——你可以只跑 take-root plan,写完方案之后自己手动实现,不一定要走全流程。
没有多 agent 使用经验。 这套框架的配置和排错有一定门槛——provider 路由、persona 权限、artifact 格式、resume 机制,每一个出问题都需要你有基本的调试能力。如果你还没用过多 agent 工作流,建议先从单 agent 项目积累一些经验再来试。
适合这些场景
你已经在手动做多 agent review。 经常一个 agent 写方案、另一个 agent review;一个 coding、另一个 review 代码——如果你已经在手动跑这个流程,take-root 就是把这件事自动化并加上收敛机制。
项目进入深水区。 代码库变大、依赖关系变复杂、单 agent 开始频繁引入回归问题——这是 take-root 最能发挥价值的时机。越是复杂的项目,结构化评审和收敛机制的价值越高。
需要根据方案验证收敛指标。 如果你的项目有明确的 AC(验收标准),take-root 的 test 阶段可以把这些 AC 编码进去,让 Amy 按标准验证,而不是靠感觉判断”是不是做完了”。
八、结语
我在用 AI agent 写项目的这段时间里,走过最大的弯路,是把”模型更聪明”当成解决工程问题的答案。
换了一圈模型之后,我意识到:真正缺的不是智力,是纪律。评审、对抗、收敛指标、角色边界——这些东西不会随着模型变聪明而自动出现,它们需要被设计进工作流里。
take-root 是一个 v0.1.0 的个人项目,还很早期,有很多粗糙的地方。但它背后的设计思路——用机制约束代替 prompt 说教,用结构化收敛代替感觉判断,引入对抗机制规避大模型幻觉,从而达到稳定实现——是我目前认为最值得认真对待的方向。
如果你的项目正好进入了那个”越改越乱”的阶段,可以试试看。
GitHub:https://github.com/gokeshenzhen/take-root
最后还有一个彩蛋,使用gpt-image2画的架构图:
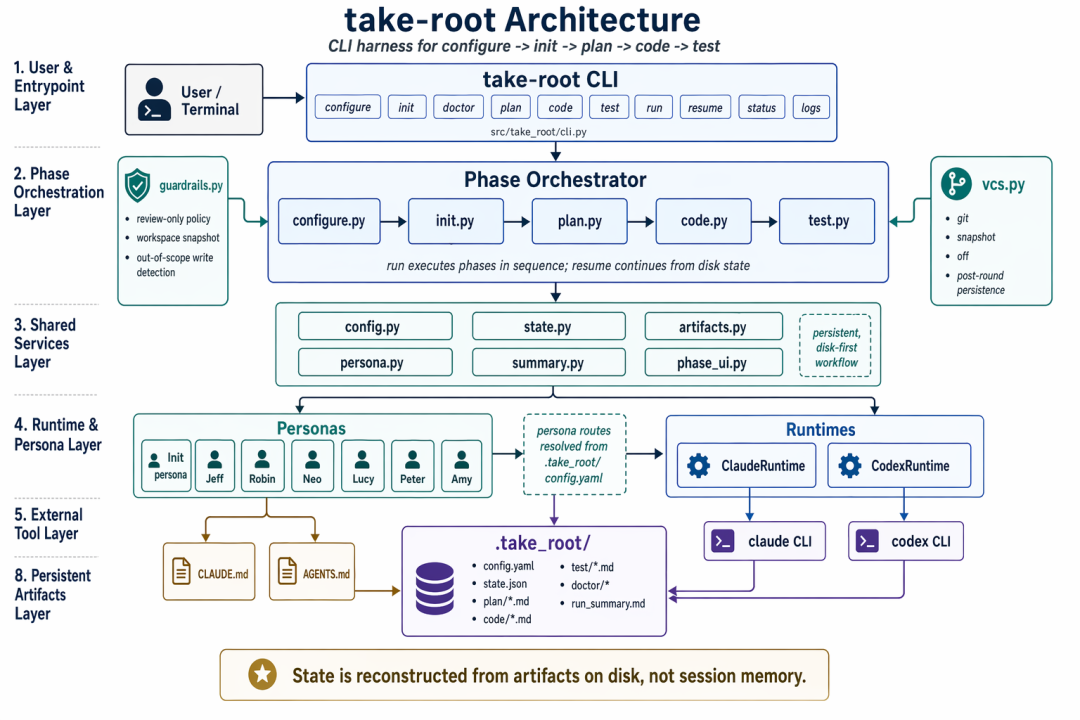
以上
💬 本文评论区已开启,但暂无读者留言。
本文转载自微信公众号,如有侵权请联系删除。
- 标题: 项目越大,Agent 越乱——我用这套harness agent 把它管住了
- 作者: lxiol
- 创建于 : 2026-05-18 15:05:39
- 更新于 : 2026-05-18 15:05:39
- 链接: https://blog.lxiol.cn/2026/05/18/项目越大Agent-越乱我用这套harness-agent-把它管住了/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。